의외로 다른 IT 프로젝트와 달리, 특히 AI 프로젝트의 성공율이 15%정도라고 한다. 왜 15%밖에 안되는 것인가? 해당 보고서에는 아래와 같이 설명하고 있다.
ML은 아직 리서치 단계(연구단계)의 작업들이다. 따라서, 애초에 프로젝트 시에 무조건 된다는 버려야 한다.
기술적을 불가능한 문제를 푸려고 한다.
프로덕션 단계를 고려하지 않는다.
ML 프로젝트의 성공여부가 불분명하다.
팀 관리가 안된다.
Lifecycle (생애주기)
ML project의 생애주기는 ML 프로젝트에 각각 무엇이 수행될 수 있는지에 관한 내용이다. 크게는 프로젝트 계획하기-> 데이터 수집 및 라벨링 -> 모델 학습 및 디버깅 -> 모델 적용 및 테스트로 구분된다. 이 단계가 무조건 1, 2,3,4의 순차적인 단계로 실행되는 것은 아니고, 진행하던 단계가 문제에 봉착했는데 풀 수 없을 경우는 이전, 또는 더 이전단계로 돌아가서 계획부터 다시 할 수 있다는 것을 알아야 한다.
ML 프로젝트의 생애주기
- 프로젝트 계획하기(Planning and Project setup): 실제 문제를 풀어 나갈 것인지, 목표는 무엇인지, 리소스는 어떤 것들이 있는지 파악하는 단계이다.
- 데이터 수집 및 라벨링(data collection and labeling): 훈련용 데이터를 수집하고, ground truth(실제 참이라고 할 수 있는 라벨)을 이용하여 데이터를 라벨한다. 만일 이 단계에서 뭔가 문제가 있거나 데이터를 구하기 어려우면 프로젝트 계획부터 다시 실행하는 것을 권장한다.
- 모델 학습 및 디버깅(Model traning and debugging): 이 단계에서는 베이스 라인 모델을 빨리 적용해놓고, 가장 좋은 모델들을 찾아서 성능을 높혀나가는 것을 의미한다. 그리고 이 단계에서는 뭔가 라벨링이 이상하거나 데이터가 더 필요한 경우는 이전 단계인 "데이터 수집 및 라벨링" 단계로 돌아간다. 혹은 문제가 너무 어려워서 풀지 못할 것 같거나, 프로젝트 요구사항에서 밀릴 경우는 프로젝트 게획하기 단계부터 다시 실행한다.
- 모델 적용 및 테스트(ML Deploying and Model testing): 이 단계에서는 파일럿 모델을 연구실 환경에서 한번 돌려보고, 잘되는지 확인하고, 실제 프로덕션 단계로 적용한다. 만일, 성능이 애초에 안나오는 경우, 모델 학습 및 디버깅 단계로 돌아간다. 또는 데이터가 더 필요하거나, 훈련데이터랑 실제 데이터랑 너무 안맞는 경우 데이터 수집 및 라벨링 단계로 간다. 마지막으로 실제 환경에서 잘 동작하지 않거나, 사용자의 사용 환경과 너무 안맞는 결과들이 나올 경우에는 계획부터 다시해야할 수도 있다.
프로젝트의 우선순위 결정하기(Priortizing projects)
ML프로젝트를 실행하기전에, 이 프로젝트가 얼마나 비지니스 모델에 영향을 줄 것인지? 아래의 그림처럼, 가능한 실현가능성도 높고, 실제 비지니스에 영향을 줄만한 프로젝트를 하는 것이 중요하다.
영향도 평가: 니즈(Needs). 니즈를 파악하는 것은 얼마나 의사결정 과정에서 마찰을 경험하고 있는지를 파악해보는 것이다. ML의 장점(Strength)은 Software 2.0(데이터가 많아질 수록 성능이 강력해지는 소프트웨어)과 데이터가 실제 복잡한 규칙기반의 소프트웨어이며, 이 규칙이 데이터로 학습할 수 있는 지를 의미한다.
실현가능성 평가(Feasibiltiy): 실현 가능성을 평가하는 것들중에 비용이 많이 드는 순서로 문제의 난이도 -> 요구되는 모델의 정확성 -> 사용가능한 데이터순으로 높다. 첫 째로 가장 문제가되는 데이터는 "데이터가 많은지", "얻기 쉬운지?", "얼마나 많이 필요할지" 등이다. 흔히 생각할 수 있는 내용이다. 둘 째로, 모델의 정확도 요구사항은 혹시 모델이 틀렸을 때 얼마나 비용이 많이 드는지, 어느정도 정확해야 쓸만한지, 윤리적인 이슈는 없는지에 관한 내용이다. 마지막으로 문제의 난이도는 "문제가 잘 정의도리 수 있는지", "이전에 해결한 문제들은 없는지" 컴퓨팅 요구사항"은 되는지, 사람이 할 수 있는일인지에 관한 내용이다.
아키텍처(Archetypes)
ML 프로젝트의 메인 카테고리로, 프로젝트 관리 및 구현을 어떻게 할 것인지에 관한 내용이다. 이 챕터는 그 원형(Archetypes)에 대한 얘기로, 크게 3가지로 분류되며, Sofware 2.0, HITL(Human in the loop), Autonomous system이다. 본인이 풀고자하는 문제들이 어느부분에 해당하는지, 어떻게 구현되는지 개념적으로 명확히 이해하는데 도움을 줄 수 있다.
Software 2.0: 소프트웨어의 성능이 데이터가 많아질 수록 강력해지는 것을 의미한다. 기존의 규칙기반 시스템을 능가하는 것을 의미한다.
HITL: 사람의 컨펌하에 쓰는 소프트웨어이다. 가령, 구글 이메일 작성시, 오토 컴플릿되는 것을 의미한다.
자동화 시스템: 사람 손을 안타는 시스템이다.
평가지표(metrics)
위의 내용처럼 어떻게 구현하겠다라는 가이드가 잡히면, 실제로 어떤 지표를 삼아야 성공여부를 달성했는지, 효율적으로 평가할지를 알 수 있다. 당연하겠지만 평가도구는 모델의 성능을 평가할 수 있는 지표를 삼아야한다. 처음에는 모델을 성능을 단순히 평가할만한 하나의 지표로 삼다는다. 그 후에, 안정화되면, 여러 평가지표를 복합적으로 쓸 수 있다. 가령, 평균적인 모델의 성능은 어느정도가 되어야하는지지표(average)와 지표를 넘는지 안넘는지 임계치(Threshold)로 계산해볼 수 있다. 가령 임계치는 모델 몇 MB이하여야한다 정도로 써볼 수 있다.
베이스라인 모델 구하기
실제 ML프로젝트를 하다보면 무조건 SOTA(State of the Art)부터 가져와서 적용할라다보니까, 어렵다. 그리고, SOTA을 적용하다가 너무어려워서 다 따라가지도 못하고 접는 경우도 생긴다. 그리고 SOTA부터 적용하니까 어느정도가 적정한 모델 성능인지 파악하기 어렵다. 베이스라인 모델을 구해서 적용해보는 것은 위의 내용을 파악하는데 도움을 준다. 베이스라인 모델은 대강 우리의 모델이 어느정도 성능이 나올 것이다하는 바로미터로 써볼 수 있다. 예를 들어, 질병 추천시스템의 Top 5 Recall이 대충 선형회귀로 해도 80%가나오면 이문제는 어느정도 풀만한 모델이고, 잘만하면 90%도 나올 수 있다는 것을 알 수 있다.
Grad-CAM의 FeatureMap의 기여도를 찾는 방법은 각 FeatureMap의 셀로판지가 최종 색깔에 어느정도 기여하는지와 동일하다.
요약
Grad-CAM은 CNN 기반의 모델을 해석할 때 사용되는 방법이다. 인공지능의 해석방법(XAI)에서는 Grad-CAM은 흔히 Post-hoc으로 분류되고(일단, 모델의 결과(Y)가 나오고 나서 다시 분석사는 방법)으로 취급된다. 또한, 딱 CNN에서만 사용되기 때문에 Model-specific 방법이다. 이 Grad-CAM의 가장 큰 쉬운 마지막 CNN이 나오고 나서 반환되는 Feature Map(본문에서:A)이 평균적으로 Y의 분류에 어느정도 되는지를 계산하고, 각 픽셀별로 이를 선형으로 곱하는 방법이다.
상세 내용
Grad-CAM은 아래와 같이 계산할 수 있다.
식1: Grad-CAM의 핵심적인 계산과정
각, 기호에 대한 설명은 아래와 같다. y은 모델이 내뱉는 확률이며, c는 특정 라벨을 의미한다. 개 vs 고양이의 분류기이면 c의 최대값은 2이 된다(=1, 2의 분류). 그 다음, $A^k$은 각 Feature Map을 의미한다. Feature Map은 이미지가 CNN을 통과한 결과를 의미한다. $k$가 붙는 이유는 CNN을 통과하고나서 CNN의 필터의 개수(k)만큼 반환되는 값(feature map)의 k채널이 생기기 때문이다. 일종의 채널과 같다.
마지막으로 $a_{k}^{c}$은 $A^{k}$의 필터맵이 이미지와 유사한데, 이 필터맵의 각 픽셀들이 분류에 어느정도 기여했는지를 의미한다. 아래의 그림(Figure 1)을 보자. Feature maps이 4개가 있으니 $k=4$인 예시이다. 녹색의 feature maps을 보면, 5x5로 이미지가 이루어져 있는데, 각 $i, j$에 해당하는 픽셀이 $y^{c}$에 어느정도 기여했는지를 구한 것이다.
Figure 1. GAP의 그림
즉, Grad-CAM은 각 feature Map이 어느정도 모델의 결과값($y$)에 기여했는지($A^{k}$)와 각 픽셀이 모델의 결과값에 어느정도 기여했는지($a_{k}^{c}$)을 곱하는 것이다. 결국, 각 픽셀이 feature maps을 고려하였을 때(가중하였을 때) 결과값에 어느정도 영향을 미쳤는지를 계산할 수 있다.
구현:
torch에서는 register_foward_hook과 register_backward_hook을 이용하여 grad cam을 계산할 수 있습니다. register_forward_hook과 register_backward_hook은 PyTorch에서 모델의 레이어에 대한 forward pass와 backward pass 중간에 호출되는 함수를 등록하는 메서드입니다. 이를 통해 레이어의 활성화 맵이나 그래디언트를 추출하거나 조작할 수 있습니다.
register_forward_hook: 이 메서드는 모델의 레이어에 대해 forward pass가 수행될 때 호출되는 함수를 등록합니다. 등록된 함수는 해당 레이어의 출력을 인자로 받아 다양한 작업을 수행할 수 있습니다. 주로 활성화 맵 등 중간 결과를 추출하거나 조작하는 데 사용됩니다.
def forward_hook(module, input, output):
# module: 레이어 인스턴스
# input: forward pass의 입력
# output: forward pass의 출력
pass
target_layer.register_forward_hook(forward_hook)
register_backward_hook: 이 메서드는 모델의 레이어에 대해 backward pass가 수행될 때 호출되는 함수를 등록합니다. 등록된 함수는 해당 레이어의 그래디언트를 인자로 받아 다양한 작업을 수행할 수 있습니다. 주로 그래디언트를 조작하거나 특정 그래디언트 정보를 추출하는 데 사용됩니다.
def backward_hook(module, grad_input, grad_output):
# module: 레이어 인스턴스
# grad_input: 입력 그래디언트
# grad_output: 출력 그래디언트
pass
target_layer.register_backward_hook(backward_hook)
위의 두 함수를 이용하여 아래와 같이 구현할 수 있습니다.
def grad_cam(
model: torch.nn.Module,
image: np.ndarray,
target_layer: torch.nn.Module,
) -> np.ndarray:
"""
Args:
model (torch.nn.Module): Grad-CAM을 적용할 딥러닝 모델.
image (np.ndarray): Grad-CAM을 계산할 입력 이미지.
target_layer (Type[torch.nn.Module]): Grad-CAM을 계산할 대상 레이어.
Returns:
np.ndarray: Grad-CAM 시각화 결과.
"""
def forward_hook(module, input, output):
grad_cam_data["feature_map"] = output
def backward_hook(module, grad_input, grad_output):
grad_cam_data["grad_output"] = grad_output[0]
grad_cam_data = {}
target_layer.register_forward_hook(forward_hook)
target_layer.register_backward_hook(backward_hook)
output = model(image) # 모델의 출력값을 계산합니다. y_c에 해당
model.zero_grad()
# 가장 예측값이 높은 그레디언트를 계산합니다. output[0,]은 차원을 하나 제거
output[0, output.argmax()].backward()
feature_map = grad_cam_data["feature_map"]
grad_output = grad_cam_data["grad_output"]
weights = grad_output.mean(dim=(2, 3), keepdim=True)
cam = (weights * feature_map).sum(1, keepdim=True).squeeze()
cam = cam.detach().cpu().numpy()
return cam
Pod(파드): 여러 컨테이너를 묶어 놓은 논리적인작업 단위이다. 파드 내에는 1개의 컨테이너가 존재할 수 있고, 여러 개의 컨테이너가 존재할 수도 있다. 1개만 존재하면 싱글 컨테이너 파드, 2개 이상 존재하면 멀티 컨테이너파드라고 부른다. 그럼 컨테이너는 무엇인가? 하나의 "어플리케이션"이라고 생각하면 된다. 파드에는 여러 개의 컨테이너가 존재할 수도 있기 때문에, 웹 서버 컨테이너, 로그 수집기, 볼륨(=디스크)을 묶어 하나의 파드로 구성할 수도 있다.
파드 사용하는 방법
파드를 사용하는 방법은 CLI(커멘드 명령의 인터페이스)로 실행시키는 방법이 있고, 아래의 그림과 같이 YAML포맷의 파일을 이용해서 생성하는 방법이 있다.
metdata.name: 값에 해당하는 필드 및 필드명은 이 파드의 이름을 설정하기 위함이다.
spec.containers: 이 필드아래에 container을 적으면 하나씩 컨테이너가 생긴다. 아래의 예시는 컨테이너 1개를 생성하는 예시이다. "-"(하이픈)은 하위필드를 배열로 묶겠다는 것이다. 즉, 파이썬의 딕셔너리로 생각하면 {"spec": {"container": [{"image":"nginx":"latest"}, {"name":"my-nginx"}, {"resources": {}}]와 같이 속성들을 containers의 하위 필드 배열로 취급하겠다는 것이다.
spec.containers.image: 컨테이너에 사용될 이미지명을 적는다, ":"앞은 어플리케이션 명, 뒤는 어플리케이션의 버전정보이다. 사용자가 다운로드 받지 않아도, 이 컨테이너를 실행하는 순간에 컨테이너 허브에서 이 이미지를 다운로드(PULL)하여 가져온다.
Pod 생명주기
파드 생명주기는 파드 생성부터 파드의 삭제, 실패까지의 과정 중에 각각 어느단계에 있는지에 대한 개념이다. 만일 파드가 러닝중인지? 생성중인지? 실패했는지에 관한 내용을 알 수 있다. 일단 파드가 한번 생성되면 유니크안 식별자(UID, Unique ID)을 갖는다. 그리고, 삭제되기 전까지는 유지된다. 파드 생명주기 중에 어느 상태인지는 status의 필드로 확인할 수 있다.
이름이 mywebserver인 STATUS가 실행중인 파드. 어플리케이션은 1개중에 1개가 구동중
각 단계별로 의미하는 것은 아래와 같다.
상태(STATUS)
의미
Pending
쿠버네티스 클러스에서 일단 실행이 가능한 상태라고 판명된 상태. 하지만, 컨테이너중에 몇개는 아직 구동을 준비중인 상태를 의미한다. (=즉, "만들어지는 중이에요" 라는 상태)
Running
파드 내에 모든 컨테이너가 구동중인 상태
Succeeded
파드 내 모든 컨테이너가 구동에 성공된 상태.
Failed
파드 내 모든 컨테이너가 종료된 상태. 정상 실행이 아닌 (non-zero status) 컨테이너가 존재하는 상태.
Unknown
모종의 이유로 컨테이너 상태를 얻을 수 없는 경우
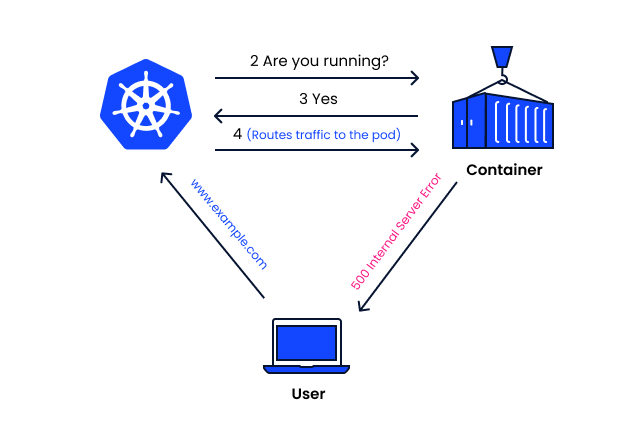
LivenessProbe 사용하기: 자동으로 컨테이너가 죽는 경우, 재시작 하기
kubernetes의 livnessProbe의 동작 방식 그림 (참조: https://komodor.com/learn/kubernetes-liveness-probes-a-practical-guide/)
livenessProbe을 이용해서 컨테이너 sefl-healing 이용하기
livenessProbe가 동작하는 방식은 httpgetprobe, tcpSocketprobe, execprobe라는 것을 이용해서 각각의 목적에 맞는 일부 기능들을 주기적으로 체크를 해서 컨테이너가 정상적으로 동작 중인지를 확인한다. 예를 들어, http 웹서버라면, httpget probe은 주기적으로, 지정한 IP, port, path에 대해서 HTTP get요청을 보내서 응답이 잘 못나오는 경우 컨테이너를 다시 시작한다. tcpSocket probe은 ssh로 접속해보고 접속이 몇 번 실패하면, 해당 컨테이너를 다시 시작하는 것이다. exec probe은 명렁을 전달하고 명령의 종료코드가 0 (정상종료)가 아니면, 컨테이너를 다시 시작하는 것이다. 중요한 것은 Pod을 재시작하는 것이 아니라 Container을 재시작하는 것이다. 따라서, Pod은 그대로 이기 때문에, IP을 동일하게 사용할 수 있다.
livenessProbe을 사용하기 위해서는 몇 가지 전달해야하는 인자가 있는데, 아래와 같다. 자세한 인자들(Configuration)은 여기에서도 확인이 가능하다. initialDelaySeoncds은 컨테이너 실행 후 몇초 뒤에 probe을 실행할 것인지에 대한 속성이다. periodSeoconds은 몇초 주기로 프로브를 실행할 것지에 대한 속성, timeoutSeconds은 프로브를 실행하고나서 몇초 내에 명령들이 종료되어야하는지에 대한 속성, seccessThreshold은 이 프로브가 몇 번 연속 성공하면 성공이라고 볼것인가에 대한 것이다. failureThreshold은 프로브가 몇 번 실패해야 실패로 볼 것인지에 대한 기각역이다.
아래의 예시는 buxybox라는 이미지를 이용해서 컨테이너 1개짜리를 담은 "liveness-exam"이라는 Pod을 생성한다. 추가로, 컨테이너를 실행할 때, 컨테이너 상의 '/tmp/healthy'라는 파일을 만들고 30초 후에 삭제하는 명렁도 같이 넣어놓았다. 즉, 컨테이너가 실행되고나서 30초 동안만 파일이 존재할 것이다.
exec livenessProbe을 사용하기위한 yaml 예시. 컨테이너 실행할 때 초기에 30초동안만 파일을 생성하고, 그 뒤에 지우는 커멘트가 들어가있다. 마찬가지로 이 파일을 cat으로 확인하는 커멘드도 포함되어 있다.
아래와 같이 exec livenessProbe가 실행을 몇 번해보다가, failthrehold만큼 실패하면 해당 컨테이너를 재시작한다.
위의 yaml파일에서 failureThrehold가 3번이 지정되었기 때문에, 3번 검사하고 (x3 over 11s) 실패했기 때문에, 해당 컨테이너를 삭제하고 재시작하는 것이다.
초기화 컨테이너(Init container): 초기화 컨테이너는 파드에 앱 컨테이너가 실행되기 전에, 실행되는 특수한 컨테이너이다. 이 초기화 컨테이너로, 앱 이미지(도커이미지)에 없는 설정, 유틸리티 스크립트를 실행하여 일부 변형을 할 수 있다.
초기화 컨테이너(init container)은 Pod내에서 어플리케이션이 동작하기전에 실행되는 특별한 컨테이너를 의미한다[ref]. 주로, 만들어진 이미지를 컨테이너로 실행하면서 추가사항을 실행하기 위한 목적으로 쓰인다. 예를 들어, 구동하고자하는 앱은 RestAPI + 딥러닝추론엔진이라면, 컨테이너에는 FastAPI이미지만 있고, 초기화 컨테이너가 실행될 때, 딥러닝추론엔진만 다운로드 받아오는 식이다. 이렇게하면 딥러닝 추론엔진이 사이즈가 엄청 크더라도(>10Gb) 한 이미지에 담을 필요없이, 이미지 + 추가실행사항 정도로 이해하면된다.
일반적인 컨테이너랑 거의 유사(리소스 제한, 볼륨 사용, 보안세팅)한데, 다른 몇 가지가 있다, 대표적으로 lievnessProbe을 지원하지 않는 것이다. 그리고 초기화 컨테이너도 일반 컨테이너(regular container)와 마찬가지로 다수의 초기 컨테이너를 사용할 수 있다. 초기 세팅이 2~3개 이상 필요한 경우, 초기화 컨테이너를 2~3개 이상 명시하는 것이다. 이 때, yaml파일에 적인 순서대로 동작한다. 먼저 선언된 초기화 컨테이너가 동작하지 않으면, 뒤의 초기화 컨테이너가 동작하지 않는다. 초기화 컨테이너의 실행이 실패하면, 쿠버네티스는 실행 될 때까지 초기화 컨테이너를 구동해본다. (=쿠버네티스의 "선언적 특징"). 그리고, 초기화 컨테이너가 다 실행되어야, 메인 컨테이너를 동작한다(=초기화 컨테이너가 실행이 안되면 메인컨테이너가 구동이 안됨)
실제 파드를 쿠버네티스에 띄워보면 아래와 같아. myapp-pod가 초기화되려고할 때, STATUS은 Init:0/2상태로 2개의 초기화 컨테이너가 파드내에서 동작해야함을 의미하고 있다.
그리고, kubectl desribe pod myapp-pod을 찍어보면, 첫 번째 초기화 컨테이너(init-myservice)가 실행중임을 알 수 있다.
kubectl desribe pod myapp-pod
# std out
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 13m default-scheduler Successfully assigned default/myapp-pod to docker-desktop
Normal Pulling 13m kubelet Pulling image "busybox:1.28"
Normal Pulled 13m kubelet Successfully pulled image "busybox:1.28" in 5.871629222s
Normal Created 13m kubelet Created container init-myservice
Normal Started 13m kubelet Started container init-myservice
조금 더 자세히, 첫 번째 컨테이너의 로그를 보면(kubectl logs myapp-pod -c init-myservice) 계속 실패중이다.
위와 마찬가지로 두 번째 컨테이너의 로그를 보면, 첫 번째 컨테이너가 실패했기 때문에, 구동을 시도조차 하지 않았을 것이다.
Infra container 사용하기
싱글 컨테이너로 파드를 구동하면 일반 컨테이너(regular)가 1개 돌아가는데, 사실은 아무일도 하지 않는 Infra container (pause) 컨테이너가 숨어있다.파드 생성될 때, 1개씩 생성된다. 파드에 대한 인프라 IP, HOSTNAME 을 관리한다. 이 파드는 식별자(UID)가 1이다. 다른 컨테이너의 부모 컨테이너로 사용(다른 컨테이너를 생성할 때, 상속받듯이 사용)이 된다. 그래서, 파드 안에 새로운 컨테이너 생성되면, Infra contatiner을 참조하여 만드니까, IP, hostname이 동일하게 생성된다. 혹시나, 이 infra conatiner가 재시작이 된다면, 파드 내에 네트웍구성이(IP, hostname)가 동일해야되기때문에, 모든 컨테이너가 다시 재시작이 된다.
스태틱 파드(Static Pod)
각 워커노드에서는 kublect 이라는 데몬이 돌아이 돌아가는데, kubelet은 파드에서 컨테이너가 확실하게 돌아가게끔 관리해주는 역할을 한다. 여태까지는 컨테이너를 띄울 때, Kubectl을 통해서, 각 노드에게 명령을 전달했다. 반면, 스태틱 파드는 직접 데몬에서 실행하는 (노드에 직접 들어가서 파드를 정의하는 디렉토리(/etc/kubernetes/manifests, kubelete configuration file)에서 직접 설정하게끔 파일을 설정하면, 자동으로 kubelet이 이 파일을 참조해서 컨테이너를 만드는 데, 이것이 스태틱파드이다. 즉, API서버 없이 특정노드에 있는 kubelet에 의해 직접 실행되는 파드를 의미한다. 쉽게 말해, 수동으로 돌리는 파드이다.
# 특정 노드로 접속
$ ssh alchemist@node1
# kubelet 설정 파일을 확인
$ docker exec -it 0a5f48991df2 /bin/bash # minikube을 docker에서 띄운 경우
$ cat /var/lib/kubelet/config.yaml | grep staticPodPath
staticPodPath: /etc/kubernetes/manifests
# PodPath에 지금 kubelet이 실행하고 있는 자원들을 확인
$ cd /etc/kubernetes/manifests
$ ls /etc/kubernetes/manifests
etcd.yaml kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml
# nginx을 예시로 실행하기
$ vi nginx-pod
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: nginx-pod
name: nginx-pod
spec:
containers:
- image: nginx:latest
name: nginx-pod
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
# control-plane으로 들어와서
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-pod-minikube 1/1 Running 0 14s
Pod 생성시 컨테이너에서의 자원 제한하기(requests, limits)
Pod을 생성할 때, 각 컨테이너가 어느 노드에 실행될지는 컨트롤플래인(control-plane)의 스케쥴러가 확인해준다고 했다. 사용자가 지정으로 "특정 컨테이너를 돌릴 때, 적어도 이정도 자원이 필요해요", 또는 "특정 컨테이너를 돌릴 때, 다른 컨테이너에 영향안받게 최대 여기까지만 자원을 할당해주세요" 와 같이 요구사항/제한을 둘 수 있다. 전자(특정 컨테이너를 돌릴 때, 적어도 이정도 자원이 필요해요)는 requests, 후자(특정 컨테이너를 돌릴 때, 다른 컨테이너에 영향안받게 최대 여기까지만 자원을 할당)은 limits을 의미한다. 혹여나 컨테이너가 limits의 자원을 넘어서 할당되면, 해당 파드가 죽게되고, 다시 스케쥴링이 된다. Requests은 container을 생성할 때, 어느 최소요구사항을 만족하는 node을 찾아달라는 요청이다. 신기하게도? limits을 넣으면 requests도 같은 크기로 함께 자동으로 갖게된다.
쿠버네티스에서는 메모리의 크기는 Mi단위로 표현하고, CPU은 숫자(코어수), 또는 1000mc(밀리코어, 1CPU)로 표현한다.
Kubernetes에서 컨테이너를 실행할 때, 컨테이너에 내에서 쓰이는 환경변수를 설정할 수 있다. 아래와 같이 컨테이너(Containers)이하에 env라는 속성명 이하에 담으면 된다.언제 쓰느냐? 도커 컨테이너에서 정의된 환경변수외에 추가로 필요하거나, 변경할 때 필요하다.
파드 디자인패턴은 파드 내에 컨테이너를 어떻게 구성해서 실행할 것인지에 대한 설계도를 의미한다. 파드가 2개 이상의 컨테이너로 이루어져있기 때문에, 여러 파드가 있거나 의존성이 어떤지에 따라서 구성이 각가 다를 수 있다. 크게는 1) 사이드카(Side car), 2) 엠베서더(Ambassador), 3) 어뎁터(Adaptor) 패턴이 있다. 자세한 내용은 여기서도 확인할 수 있다.
1) 사이드 카 패턴: 사이드카는 아래의 그림과 같이 오토바이에 옆에 타는 부분을 의미한다. 사이드 카라는 의미는 여기서 가져왔다. 사이드카 패턴은 이미 기능적으로 잘 실행 될 수 있는 컨테이너에 뭔가 기능을 덧댄(Add on) 이미지 패턴을 의미한다. 본디 실행하고자하는 컨테이너 자체가 잘 동작하는 경우를 의미한다. 주로 로그를 쌓거나, 모니터링하는 기능을 더해서 사용하기도한다.
Side car
2) 엠베서더(Ambassodor): 파드 외부와 내부를 연결해주는 역할을하는 것이다. 엠베서더는 대사를 의미한다. 외교사절단 대표정도로 의미가되는데, 쿠버네티스에서는 외부 TCP-Proxy로 DB을 연결해주는 역할을할수 있다. 주로 로드밸런서 역할을
3) 어뎁터 패턴(Adaptor): 어뎁터패턴은 어뎁터 용도의 컨테이너가 있어서, 각 컨테이너에서 생성하는 정보들을 모아서 관리해주거나, 또는 실제 물리적 DB에 인터페이스해서(또는 외부 데이터를 가져오는 역할), 어플리케이션에 다시 전달해주거나 해주는 역할로 사용된다. 가령 A, B, C 어플리케이션(각 컨테이너)의 로그가 제각각으로 저장되면, 이를 전처리해서 모아주는 역할을 하는 컨테이너가 있으면, 이 컨테이너가 어뎁터가 된다.
당사는 포트폴리오에 있는 자산중에 일부가 2024년에 최소수입보장(Minimum Revenue Guarantee, MRG)이 만기가 도래하여, 정부에서 수입을 보장해주지 않고, 초과분은 초과분대로, 손실은 손실대로 맥쿼리인프라가 갖게되어, 유입현금흐름의 변동성이 생길 수 있다 (아래 그림1). 이 글은 "2024년에 최소수입보장제도가 만기되어 실제로 현금흐름이 감소할 위험이 있는가?"에 대한 답을 알아가기 위한 내용이다. 아래의 내용은 MKIF(맥쿼리한국인프라투자융자회사)가 인프라투자로 수익을 어떤식으로 내고 있는지에 대한 내용이다. 또한, 이 수익구조에서 장래에도 안정적인 수익이 가능한지도 함께 조사한 내용이다. 결론부터 말하면, MKIF은 "융자"회사이다. 대출을 주운용수단으로한다.
최소수입보장(MRG)에 대한 이해
최소수입보장은 민자자본으로 건설되는 도로 등 (이하 인프라)을 만들 때, 실제 수익이 예상 수익보다 못 미칠 경우 손실 일부를 보전해주는 제도이다. 일정 한도까지는 주무관청이 투자위험을 부담해주기에, 주무관청이 SOC사업에 민간의 참여를 유도할 수 있다는 장점이 있다. 97년 외환위귀로 민자투자사업이 거의 불가능하고, 부족한 인프라 건설을위해서 사업추진 일부를 주무관청이 부담하기 위한 제도이다. 일반적으로 민자사업은 30년 이상 동안 운영되므로 해당기간 동안의 시설물 이용 수요를 정확히 예측하는 것은 상당히 어렵다. 30년후에 미래의 수요를 어떻게 예상하나? 이러한 불확실성을 제거하고 민간의 참여를 적극적으로 유도하고자 정부가 도입한 것이 MRG제도다. 그러나, 민간투자사업자의 이익을 과도하게 보장하고 있다는 많은 비판이 있어, 2009년 10월에 MRG가 폐지되었다. 대신 투자위험분담방식으로 변경되었다.
그림1. 정부수입보장 구조 (참조: 맥쿼리인프라)
MRG만기에 따른 유입현금흐름에 대한 이해
앞서 MRG와 MKIF의 "융자"에 관한 간단한 설명을 했다. 즉, 맥쿼리인프라의 현금흐름은 융자해준(돈을 빌려준) 회사가 디폴트가 나지 않는지, 지분을 가지고 있는 인프라회사(이하 사업시행자)가 안정적인 배당수익을 내는지가 가장 중요하다. 인프라산업의 투자는 대부분 후순위 채권이다. 엄청난 규모의 돈을 빌려야하기 때문에(한 80%정도를 빌린다), 담보가 부족한 경우가 있다. 맥쿼리인프라는 이 후순위채권에 투자한다. 즉, 투자중인 사업시행자가 "돈을 갚을 수 없어요" (디폴트)하는지 안하는지가 제일중요한데, 이를 지원해주는 것이 MRG이다. MRG가 보장된다면 고금리의 후순위 대출이자를 안정적으로 받을 수 있다. 또한, 일부 투자중인 회사는 지분을 가지고 있기도하다. 사업시행자의 지분을 갖고있어 배당수익도 받을 수 있다. 그렇기에 MRG만기가 안정적인 현금흐름을 가져갈 수 있는지에 대한 기준이된다.
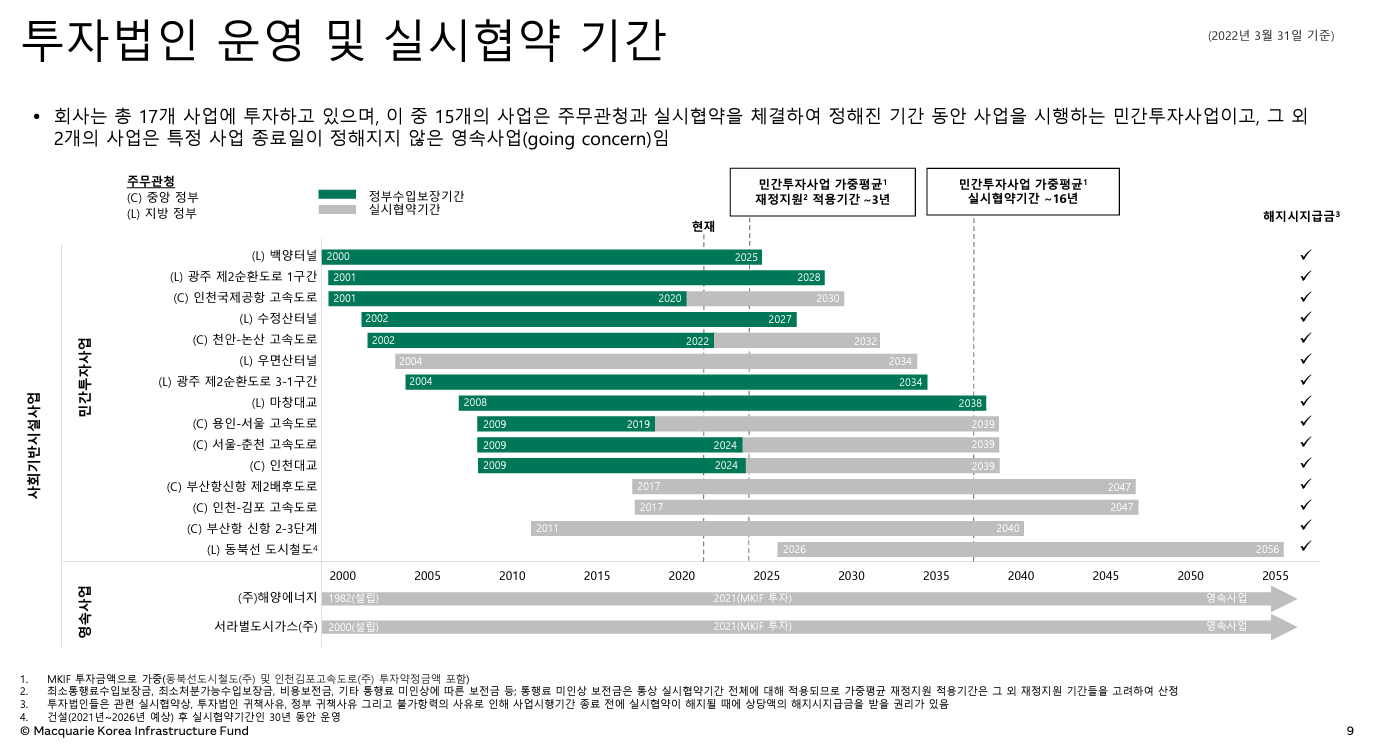
투자법인(맥쿼리인프라 포트폴리오)별로 운영 및 협약기간은 아래의 그림과 같다. 총 17개 중에, 15개는 정부와 협약해서하는 "민간투자사업"이고, 2개는 평생운영할 수 있는 영속사업이다. 이 영속사업의 2개는 가스사업으로 2021년에 약 7,000억원을 유상증자하여 얻어낸 (주)해양에너지와 서라벌가스 2가지이다. 다시, 15가지의 민간투자사업으로 돌아와보면 현재 2022년에 녹색으로 표시된 "정부수입보장기간"(=MRG 기간)이 얼마안남은 자산들이 꽤 보인다는 것이다. 2024년이되면, 정부가 손실을 보전하지도 않고, 초과분을 반환하지 않아도 된다. 맥쿼리인프라가 투자한 금액을 비율대로 하였을 때, 대략 3년 정도만 손실보전을 받을 수 있을 것이라고 기대한다는 것이다(이 말이 그림 내 "민간투자사업 가중평균 재정지원 적용기간 ~3년").
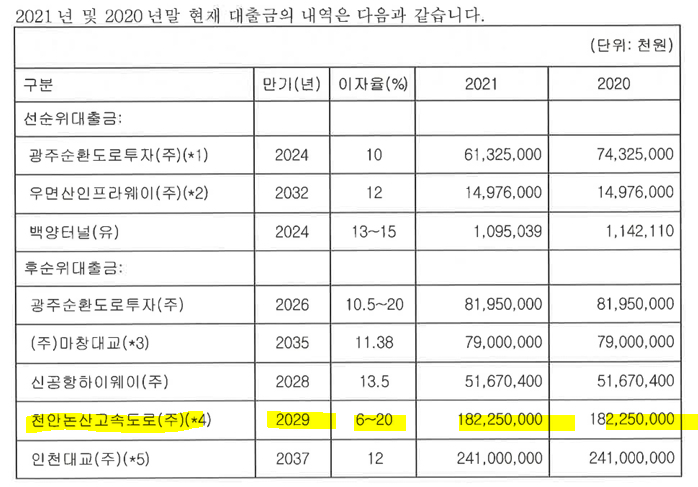
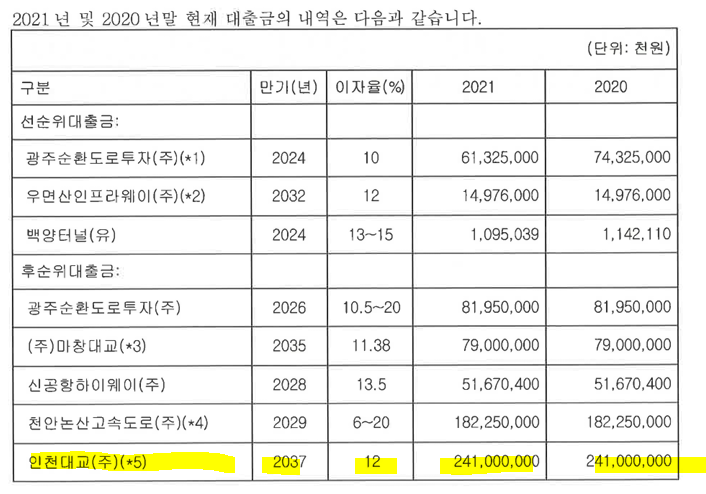
당장 정부수입보장기간이 곧 종료되는 자산인 "천안-논산 고속도로", "서울-춘천 고속도로", "인천대교", "백양터널"이 정부수입보장을 지금도 받고있는지, 향후에도 받을 것인지에 대한 판단이 필요하다. 즉, 언급한 사업시행자들이 당기순이익이 (+)인지 파악하는 것이 매우 중요하다. 미래에는 MRG을 받지 못하기 때문에, 사업시행자가 디폴트고, 미수상태로 유지된다면, 유입현금흐름이 감소할 수 있기 때문이다.
그림 2. 맥쿼리인프라의 민간투자사업 및 영속사업의 구분. 민간투자사업은 약 3년내에 MRG가 종료된다.
각 유입현금흐름을 보기 앞서, 각 자산들은 최소수입보장(MRG)이 어느정도 조건에 해당되어야 보존해주는지 파악해볼 필요도 있다. 2022년 3월 기준으로 백양터널은 약 3년, 천안-논산고속도로는 0.7년, 서울춘천,인천대교도 약 2.5년정도가 남았다. 이 기간내에서는 수입보장기준에 미달되면, 무주관정이 손실을 보상해주고, 수입환수기준보다 수입이 큰경우는 환수해간다. 기준은 각각 거의 90%, 110%정도이다. 눈여겨볼 것은 수입보장기준이 높을 수록 더 큰 현금흐름의 변동성을 보일 수 있다. 수입보장기준이 높으면, 현재 벌고있는 수입이 한 50%이어도, 90%을 맞춰주니까 40%정도를 주무관청(예, 도청, 국토부)이 보전해준다는 것이다. 물론, 수입량(Q)의 절대규모가 큰 자산은 10%~20%의 수입보장차이로도 꽤 큰 현금흐름유입의 변동성을 볼 수도 있다. 즉, 융자금의 미수가 발생하지 않아야한다. 잔존 재정지원기간이 있는 자산인 백양터널, 천안-논산 고속도로, 서울-춘천고속도로, 인천대교의 MRG의 기준대비 어느정도 벌고 있는지 파악이 너무나 중요하다.
그림3. 투자자산별 주무관정 재정지원 조건 (출처: 맥쿼리인프라)
각 자산별 유입현금흐름은 어느정도?
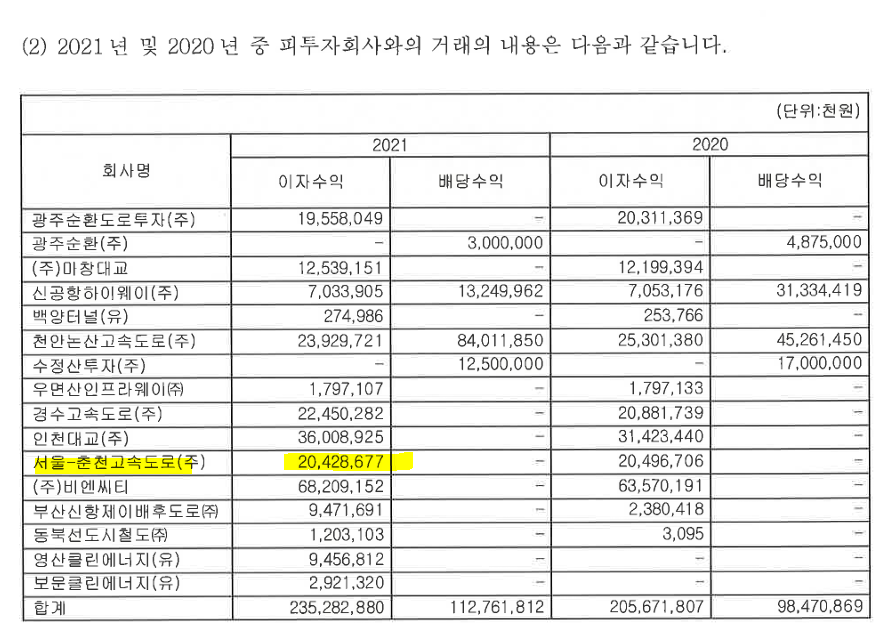
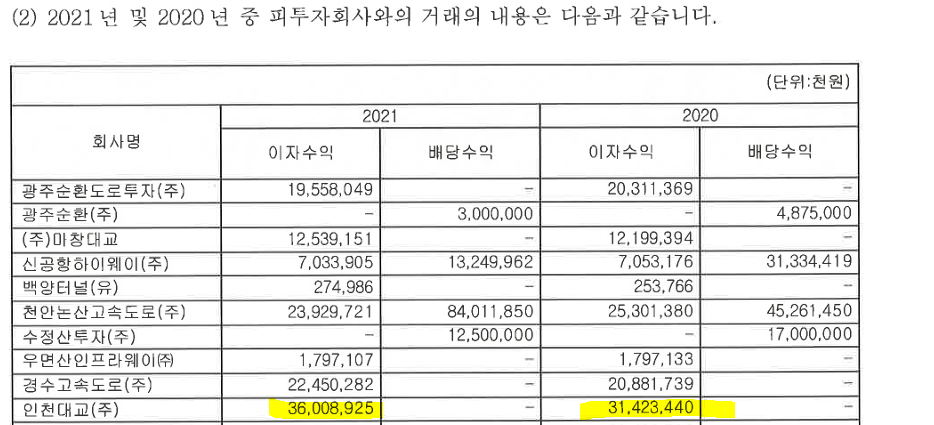
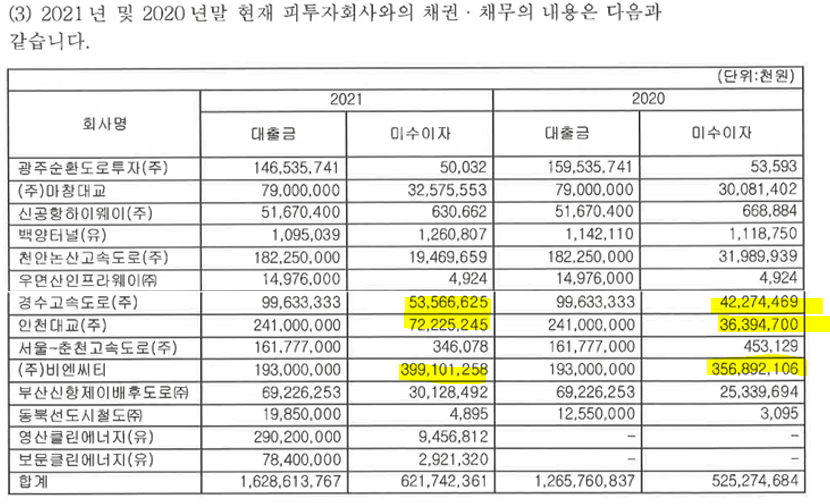
맥쿼리인프라의 자산중에서 유입현금흐름은 감사보고서에서 찾을 수 있었다. 각 행에는 각 자산별, 컬럼에는 이자수익 또는 배당수익을 2021년, 2020년으로 보여주고 있다. 아래와 같이 인프라펀드는 사회기반시설을 운영하여 배당수익을 얻는과정(=지분을 투자)과 운영기관의 융자(부채), 건설기간에는 이자로 수익을 받기 때문이다(이자수익은 어찌되었든 후순위 대출로 얻는 것이다). 큰 순서대로 보면, "천안-논산고속도로" -> "부산항((주)비엔씨티)" -> "인천대교" -> "경수고속도로(용인-서울고속도로)" -> "서울-춘천고속도로" 순서이다. 만기가 도래하는 백양터널, 천안-논산고속도로, 서울-춘천고속도로, 인천대교중에서는 "천안-논산고속도로", "서울-춘천 고속도로", "인천대교"가 수익비중이 큰 순서 Top 5안에 껴있다.
그림 4.미레에셋증권 리서치센터
표1. 2021년의 피투자회사와의 거래내용 (출처: 맥쿼리인프라 2021년 감사보고서)
맥쿼리인프라의 투자포트폴리오 기준 인천대교가 가장 투자비중이크다. 천안-논산고속도로도 마찬가지로 투자비중이 높다. 특히, 천안-논산고속도로는 투자비중도 크지만, 벌어들이는 이자수익, 배당수익도 제일 크다.
잔존 MRG가 있는 자산 별 MRG 보장내역
앞서 잔존 MRG가 있는 자산들이 실제로 주무관청으로부터 손실보전을 받고있는지 알아볼 필요가 있다고 했다. 이 섹션은 백양터널, 천안-논산 고속도로, 서울-춘천고속도로, 인천대교의 MRG의 기준대비 어느정도 벌고 있는지 파악한 내용이다.
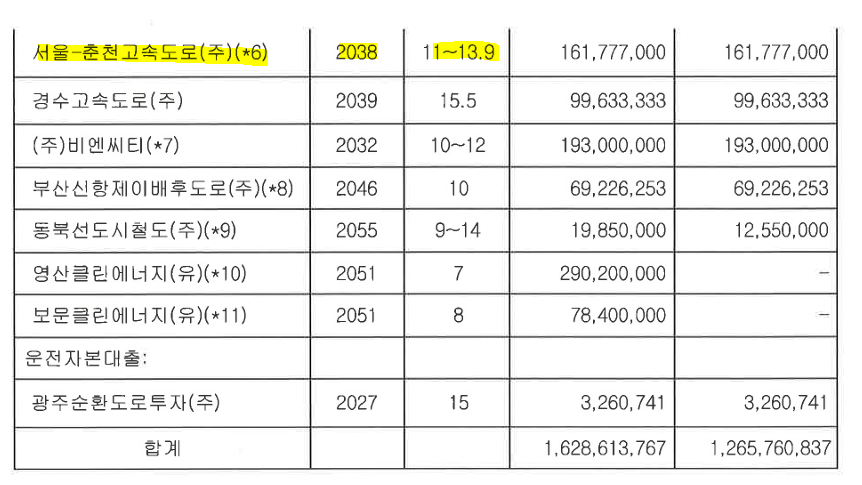
1. (주) 서울-춘천고속도로: (주) 서울-춘천고속도로는 지분 15.83%(6억), 대출 1,618억정도를 투자하고 있다 (자산 포트폴리오 규모중 8.9%). (출처: 맥쿼리한국인프라투융자회사 공시, 2020년 12월 22일). (주) 서울-춘천고속도로의 대출금을 1,618억을 빌려주고, 아래의 표와 같이 이자 11~13.9%로 대출이자를 받고있다 (표-맥쿼리인프라 대출금). 이 대출금으로부터, 매해 11% 이상의 수익율 벌고 있다. 단순 계산으로만해도 1600억을 넣어서 매해 200억을 번다. (주) 서울-춘천고속도로가 파산만 하지 않는다면, 이 대출금을 매번 갚아나가고 만기가 되면 상환하면 투자자로서 안심이다. 따라서, (주) 서울-춘천고속도로가 MRG가 끝나고도 재무적으로 디폴트가 날지 안날지가 주요 포인트가 될 수 있다. 안타깝게 (주) 서울-춘천고속도로의 재무표를 찾을 수는 없었다. 하지만, 디폴트를 간접적으로 계량할 수 있는 자료(=현금흐름이 안정적인지)로 공시를 하나 발견했다. 2020년 12월 22일에 발간한 공시에 따르면, 서울-춘천고속도로 사업의 실시협약에서 추정한 통행량의 99.4%의 수준을 기록하고 있다고 한다. 따라서, MRG을 받을 것도 아니며, 어느정도의 수익을 내고 있다고 할 수 있다.
최근 공시인 2020년 12월 24일 "서울-춘천고속도로(주) 사업재구조화"에 따르면, 2020년 12월 24일부터 통행료를 28%로 감소했는데, 이로 인한 (주) 서울-춘천고속도로의 수입이 감소하는 부분(=통행료수입 차액)은 신규 대주단의 장기 대출로 전액 보전하기로한다고 공시되어있다. 쉽게 말해, 또 다른 쩐주를 구해서 쩐주돈으로 통행료수입 차액을 보전하겠다는 것이다. 그리고, 실시협약기간이 기존에 2039년까지였는데, 2054년으로 15년 연장되었다 (서울-춘천고속도로(주) 사업재구조화: 서울-춘천 고속도로 재협약내용 (2020년 12월 22일)). 어찌 되었든 투자한 회사로부터 안정적인 현금흐름을 가져갈 수 있을 것으로 기대한다. 추가로, 2018년에 8개의의 민자고속도로 감사보고서에 평균 당기순이익 218억이며, 적자인 민자고속도로는 맥쿼리가 가지고 있는 자산이 아님을 알 수 있다 (참고: https://www.womancs.co.kr/news/articleView.html?idxno=60073)
(주) 서울-춘천고속도로로 부터 얻는 이자수익맥쿼리인프라 대출금 (출처: 맥쿼리 인프라 감사보고서, 2021년 결산내용). 11~13.9%의 이자로 표현된 것은 대출이 2회 이상으로 실시된 것으로 파악됨.
서울-춘천고속도로(주) 사업재구조화: 서울-춘천 고속도로 재협약내용 (2020년 12월 22일)
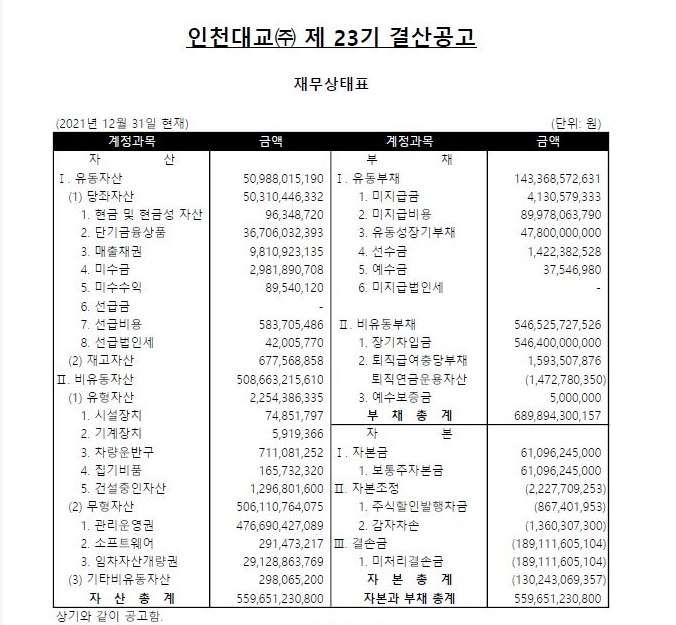
3. (주) 인천대교: 해당 사업시행자는 꽤 맥쿼리에게 큰 빚을 지고있다. 2,410억을 후순위로 12%의 이자를 납부하고 있다. 2017년만해도 900억정도 대출금이 있었는데, 전액조기상환했다. 그리고 다시 신규후순위대출금으로 2,410억을 대출해주었다. (주)인천대교의 지분 64.05%을 가지고있고, 금액으로는 580억원이다(시장성 없음). 원래는 한국민간인프라투자(주)가 있었고, 이 회사가 인천대교의 주식을 들고있엇던 것으로 파악된다, 이 회사의 지분을 들고있었는지 청산하면서, 재산분배로 직접취득하게되었다. 그 금액이 580억이다. 안타깝게 인천대교로부터 배당수익은 받지못하고, 이자수익을 360억정도를 받는다 ((2410억 * 12%)하면 290억정도인데.... 실제로는 모종의 이유로 360억을 받는듯..?)
인천대교의 부채중에서 비유동부채(만기가 37년이기에...)항목을 보면 5,460억정도가 장기차입금이다. 그 중에, MKIF대출이 2,400억정도 있을것으로 파악된다. 안타깝게도 손익계산서, 현금흐름표는 없어서... 손익계산서항목의 금융비용, 현금흐름표 투자활동의 내역을 살펴보진 못하였다. 대신 23기(21년), 22기(20년)의 재무상대표를 참고하여, 인천대교의 재무건전성을 아주 대략적이나마 볼 수 있겠다.
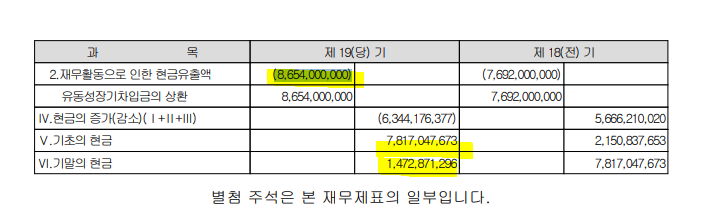
4. 경수고속도로(=서울-용인고속도로): MKIF은 위와 마찬가지로 경수고속도로에 후순위대출을 했다. 총 규모는 996억, 이자율은 15.5%이다. 매해 지급되는 이자수익은 220억정도이다(996억 15.5%= 154억아인가.. 이것도 모종의 이유가 있는듯..). 지분은 43.75%이며, 규모로는 520억이다.
유효이자율은 서울용인고속도로의 감사보고서를 찾을 수 있었다. 매해, 재무활동현금흐름 865억의 비용으로 나가는 것을 파악할 수 있는데, 꽤 과한 금융비용이 나가는게 아닌가 싶은데, 이중에 220억정도는 MKIF로 흘러들어가는 것으로 파악된다.
투자회사중에 미수가 꽤 발생하면 상당히 위험할 수 있다. 채권단에 속하는 맥쿼리인프라가 현재 현금흐름이 좋다고해도 지속적으로 미수를 줄이지못하면, 디폴트시 원금도 못받을 위험이 있기 때문이다. 100억이상의 미수이자가 발생한 투자회사들은 경수고속도로(약 110억), 인천대교(약 360억, 올해 360억을 이자로 받았어야 했는데 고스란히 못받은듯), 부산항만((주)BNCT, 400억, 미수이자가 원금을 초과했다.) 2020년에도 연체이자 492억을 을 뒤늦게 수령한적도 있고 ,만기연장 및 원금상황 일정조정으로 유동성을 틔여놓은 상태이다(2020년 베인씨티 자금재조달하이라이트).
맥쿼리인프라의 현재 주당 순자산가치는? (=사업가치 제외, 재무적가치)
맥쿼리인프라 2021년 결산의 감사보고서에는 자본이 2조 5,335억, 부채가 2,892억이다. 순자산만 따지면 약 2조 2443억정도이다. 사업가치는 고려하지않고, 재무상의 가치만 따지면 5,543원이된다. 현재 주가가 12,000원이니 PBR 2.0배를 넘게 받고있다. 그만큼 시장의 매력적인 회사로도 풀이해볼 수 있다.
본 글은 투자를 유도하는 글이 아닙니다. 이 글에는 개인 의견이 있을 수 있습니다만, 투자에 대한 책임은 투자를 실행한 각자에게 있습니다.
쿠버네티스는 오프젝트라는 개념으로 각 오프젝트를 정의해놓는다. 쿠버네티스내에서 사용되는 오브젝트는 가장 기본적인 구성단위를 의미한다. 즉 쿠버네티스를 돌리는 것은 이 오브젝트들의 조합으로 이루어 진다..오프젝트는 쿠버네티스에서 쓰이는 단위이다. Pod은 컨테이너의 집합이다. 네임스페이스는 논리적인 분리의 단위로, 네임스페이스 내에 각 리소스들을 할당해서 관리할 수 있다. 가령 클러스터내에 개발, 운영, 테스트의 각각의 네임스페이스를 두어, 자원을 원하는 만큼만 할당할 수 있다.
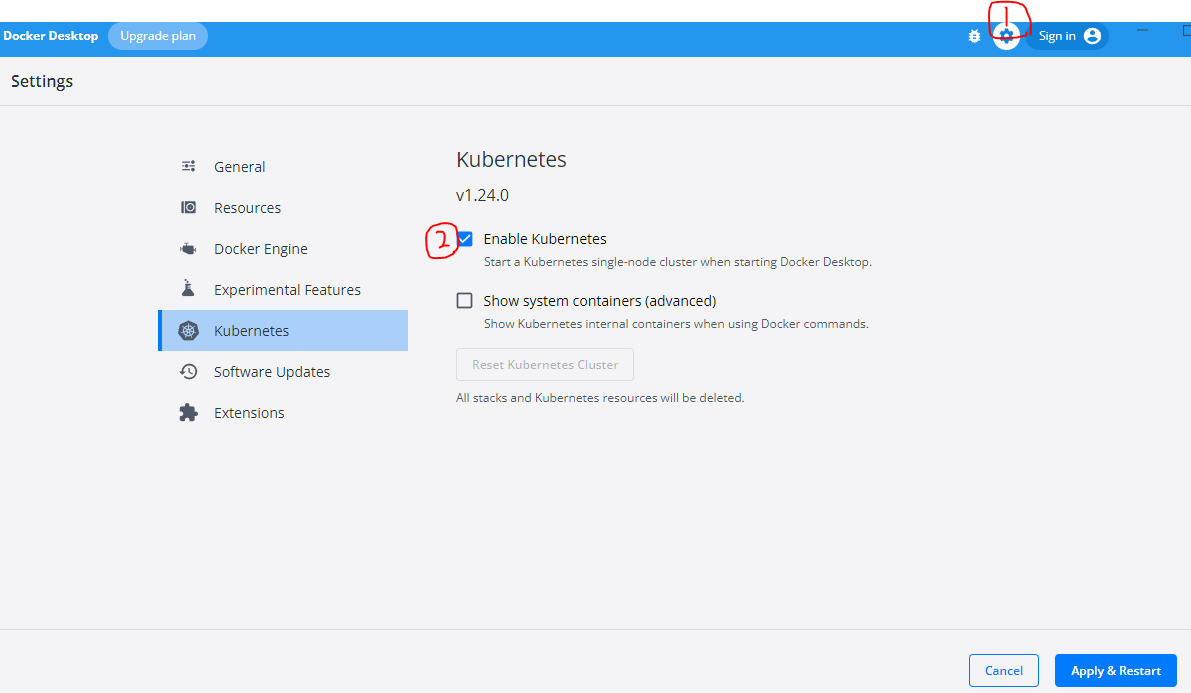
도커 데스크탑에서는 설정화면에서 쿠버네티스를 활성화하여 바로 쓸 수 있다.
아래와 같이 쿠버네티스 내의 어떤 오브젝트인지 확인 할 수 있다. 엄청 많지만 이를 다 외울 필요는 없고 가장 중요한 Namespace, Pod, Deployments, Replicaset 정도만 이해하고 나머지는 차근차근 이해하는 것이 권장된다.
클러스터 내 자원을 각기 그룹 짓기 위한 논리적인 분리단위이 네임스페이스다. 군대를 다녀온 사람이면, 이해되는 비유일 수 있는데, 1중대, 2중대와 같은 개념이다. 이 1중대, 2중대가 네임스페이스면, 중대 안에 실제로 일을하는 소대(Pod) 소대 안에 여러 컨테이너(기간병)정도로 이해할 수 있다. 즉, Pod, Service, Deployment을 하나로 묶어 네임스페이스를 구성할 수 있다. 쿠버네티스가 마스터노드 외에 워커노드들이 있는데, API을 기준으로해서 이런 클러스터가 여러개 있는 것처럼 사용하기위해 쓰는 것이다.
중대 하나가 네임스페이스에 비유할 수 있다고 했다. 1중대 내에 1소대가 2개 있을 수 있을까? 없다. 1소대가 2개 있으면 소대의 구분이 어렵기 때문이다. 따라서, 네임스페이스 내에서는 독립적인 이름을 가진 오브젝트를 생성할 수는 없지만, 서로 다른 네임스페이스에서는 같은 이름을 가진 오브젝트를 생성할 수 있다. 그림으로보면 아래와 같다. 이 싱글 클러스터에서 네임스페이스에 자원을 할당할 때도, 그룹단위로 자원을 할당할 수도 있다. 네임스페이스 A는 운영용이어서 풍부한자원을 위해 CPU 100, MEM:100GB, 네임스페이스 B에는 테스트용이어서 CPU:20, MEM:16GB을 줄 수 있다. 군보급을 중대 1, 중대 2에 맞춰서 보급하는 것과 유사하다!
쿠버네티스의 싱글 클러스터는 군대의 대대급정도로 이해할 수 있다.
이제 중대에 해당하는 네임스페이스를 하나 만들어본다. 네임스페이스는 보통 YAML파일을 이용해서 다음과 같이 생성한다. 아래와 같이 vim으로 yaml파일을 작성한다. 그리고 kubectl apply 을 이용해서 생성한다. -f 옵션은 yaml파일의 경로를 직접 지정해줄 때 사용한다.
이렇게 만든 네임스페이스는 다음의 명령어로 조회가 가능하다. "kubectl get [오브젝트 타입]"명령어로 조회할 수 있고 pod, namespace, 등등을 쓸 수 있다. 아래와 같이 네임스페이스를 조회하여 NAME이 myfirst-test인 네임스페이스를 만들어 낼 수 있다.
파드(Pod)는 쿠버네티스에서 생성하고 관리할 수 있는 배포 가능한 가장 작은 컴퓨터 단위이다. 파드(=고래 떼, 영어로는 Pod of whales임)라고 불리는 것은 하나 이상의 컨테이너를 포함한다. 아래의 그림처럼 각각의 고래를 도커 이미지로부터 만든 도커 컨테이너라면, 파드는 이렇게 만든 컨테이너들의 집합이 된다. 1고래 = 1컨테이너, N고래 = 파드가 된다.
1고래 = 1컨테이너, N고래 = 1파드의 예시. 1개의 파드에서는 N개의 컨테이너로 구성할 수 있다.
파드를 구성하면 무엇이 좋은가요라는 질문을 할 수 있는데, 한번에 여러컨테이너를 그룹단위로 컨트롤이 가능하다. 파드내의 컨테이너는 클러스터의 동일한 물리에서 자동으로 같은 위치에 배치되고, 함께 스케줄된다. 즉 리소스와 의존성을 고유하고, 통신할 수 있다. 즉, 파드는 기본적으로 파드에 속한 컨테이너에 네트워킹, 스토리지가 공유된다. 공식 문서에서는 "네트워크 네임스페이스를 공유한다"라고 표현하는데, 쉽게 말해 파드 내의 주소는 IP가 동일하다는 것이다. 따라서, localhost로 서로 통신이 가능하다. 또한, 같은 파드내에서는 모든 컨테이너들이 공유 볼륨을 갖는다. 파드 A안에 컨테이너1과 컨테이너2가 서로 같은 물리적인 공간에 있기 때문에, 같은 디스크 공간에 접근해서 사용할 수 있다. 예를 들어, 컨테이너 1이 작성한 txt파일을 컨테이너2가 쓸 수 있는 것 이다 (=볼륨이 동일하다라고 표현한다).
아래와 같이 파드내에 'ngnix'을 실행하는 컨테이너를 띄울 수 있다. apiVersion은 단순히 V1이라는 것이고, 유심히 봐야할 것은 kind: Pod인 것이다. metdata내에는 name: nginx라는 이름으로 pod을 띄운다는 것이며, spec내의 내용들이 컨테이너로 띄워진다. 아래와 같이 작성한 pod의; yaml파일이 있으면 kubectl apply -f <pod을 작성한 yaml파일주소>로 실행하면된다.