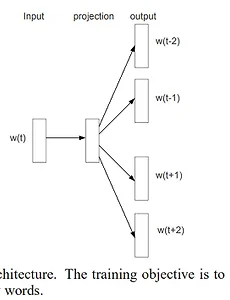
 Word2vec (Distributed Representations of Words and Pharses and their compsitionality)
2013년에 인공신경망 분야의 유명한 컨퍼런스인 신경정보처리시스템(NIPS, Nueral information processing systems)에 소개된 논문입니다. 단어나, 진단명, 음식명 등과 같이 어떤 개념들을 임베딩할 때 사용할 수 있을 것 같아, 공부겸 아래와 같이 국문번역을 진행해봤습니다. 원문: Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems (pp. 3111-3119). Requ..
2019. 9. 12.
Word2vec (Distributed Representations of Words and Pharses and their compsitionality)
2013년에 인공신경망 분야의 유명한 컨퍼런스인 신경정보처리시스템(NIPS, Nueral information processing systems)에 소개된 논문입니다. 단어나, 진단명, 음식명 등과 같이 어떤 개념들을 임베딩할 때 사용할 수 있을 것 같아, 공부겸 아래와 같이 국문번역을 진행해봤습니다. 원문: Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems (pp. 3111-3119). Requ..
2019. 9. 12.
