의외로 다른 IT 프로젝트와 달리, 특히 AI 프로젝트의 성공율이 15%정도라고 한다. 왜 15%밖에 안되는 것인가? 해당 보고서에는 아래와 같이 설명하고 있다.
- ML은 아직 리서치 단계(연구단계)의 작업들이다. 따라서, 애초에 프로젝트 시에 무조건 된다는 버려야 한다.
- 기술적을 불가능한 문제를 푸려고 한다.
- 프로덕션 단계를 고려하지 않는다.
- ML 프로젝트의 성공여부가 불분명하다.
- 팀 관리가 안된다.
Lifecycle (생애주기)
ML project의 생애주기는 ML 프로젝트에 각각 무엇이 수행될 수 있는지에 관한 내용이다. 크게는 프로젝트 계획하기-> 데이터 수집 및 라벨링 -> 모델 학습 및 디버깅 -> 모델 적용 및 테스트로 구분된다. 이 단계가 무조건 1, 2,3,4의 순차적인 단계로 실행되는 것은 아니고, 진행하던 단계가 문제에 봉착했는데 풀 수 없을 경우는 이전, 또는 더 이전단계로 돌아가서 계획부터 다시 할 수 있다는 것을 알아야 한다.
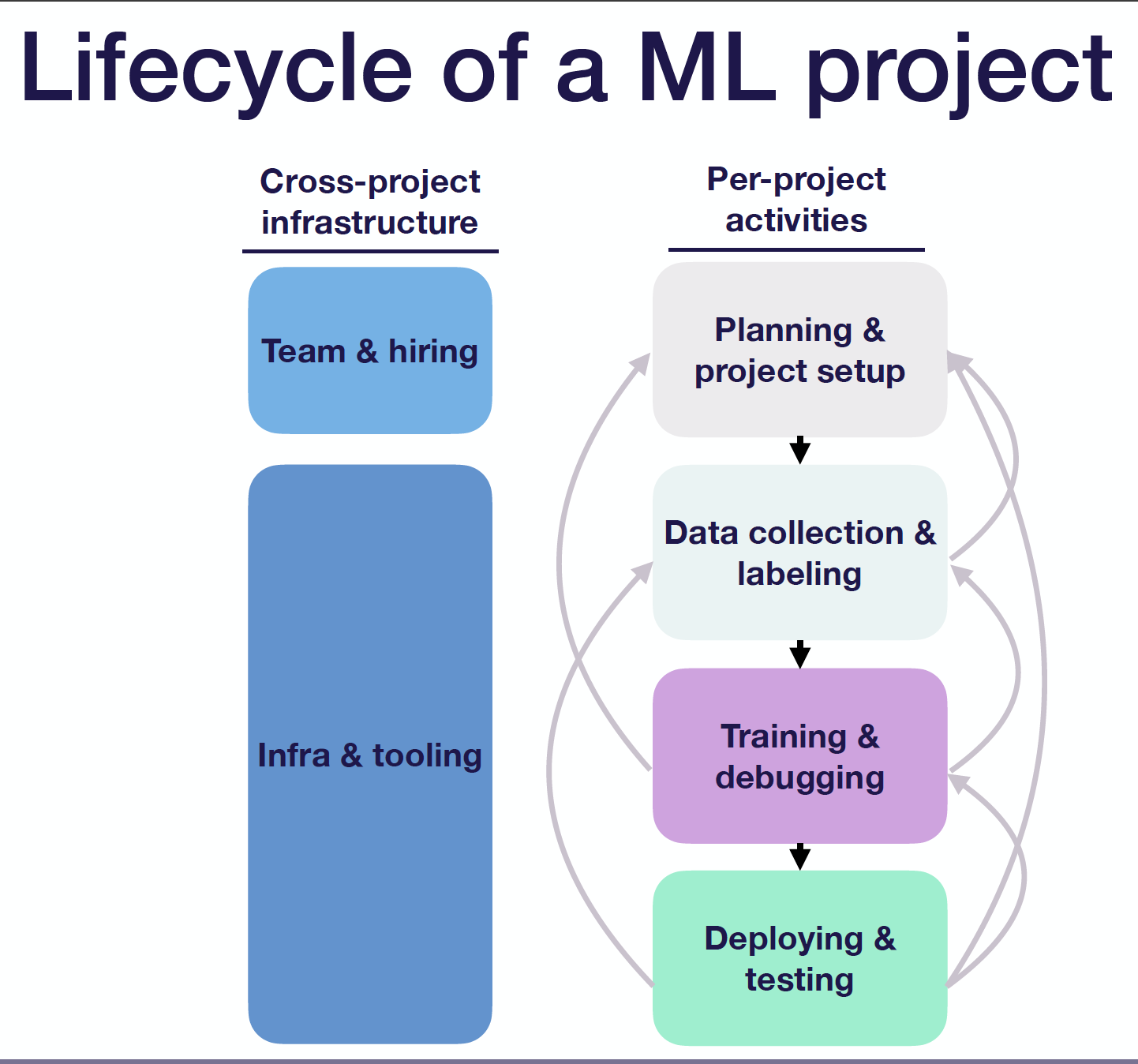
- 프로젝트 계획하기(Planning and Project setup): 실제 문제를 풀어 나갈 것인지, 목표는 무엇인지, 리소스는 어떤 것들이 있는지 파악하는 단계이다.
- 데이터 수집 및 라벨링(data collection and labeling): 훈련용 데이터를 수집하고, ground truth(실제 참이라고 할 수 있는 라벨)을 이용하여 데이터를 라벨한다. 만일 이 단계에서 뭔가 문제가 있거나 데이터를 구하기 어려우면 프로젝트 계획부터 다시 실행하는 것을 권장한다.
- 모델 학습 및 디버깅(Model traning and debugging): 이 단계에서는 베이스 라인 모델을 빨리 적용해놓고, 가장 좋은 모델들을 찾아서 성능을 높혀나가는 것을 의미한다. 그리고 이 단계에서는 뭔가 라벨링이 이상하거나 데이터가 더 필요한 경우는 이전 단계인 "데이터 수집 및 라벨링" 단계로 돌아간다. 혹은 문제가 너무 어려워서 풀지 못할 것 같거나, 프로젝트 요구사항에서 밀릴 경우는 프로젝트 게획하기 단계부터 다시 실행한다.
- 모델 적용 및 테스트(ML Deploying and Model testing): 이 단계에서는 파일럿 모델을 연구실 환경에서 한번 돌려보고, 잘되는지 확인하고, 실제 프로덕션 단계로 적용한다. 만일, 성능이 애초에 안나오는 경우, 모델 학습 및 디버깅 단계로 돌아간다. 또는 데이터가 더 필요하거나, 훈련데이터랑 실제 데이터랑 너무 안맞는 경우 데이터 수집 및 라벨링 단계로 간다. 마지막으로 실제 환경에서 잘 동작하지 않거나, 사용자의 사용 환경과 너무 안맞는 결과들이 나올 경우에는 계획부터 다시해야할 수도 있다.
프로젝트의 우선순위 결정하기(Priortizing projects)
ML프로젝트를 실행하기전에, 이 프로젝트가 얼마나 비지니스 모델에 영향을 줄 것인지? 아래의 그림처럼, 가능한 실현가능성도 높고, 실제 비지니스에 영향을 줄만한 프로젝트를 하는 것이 중요하다. 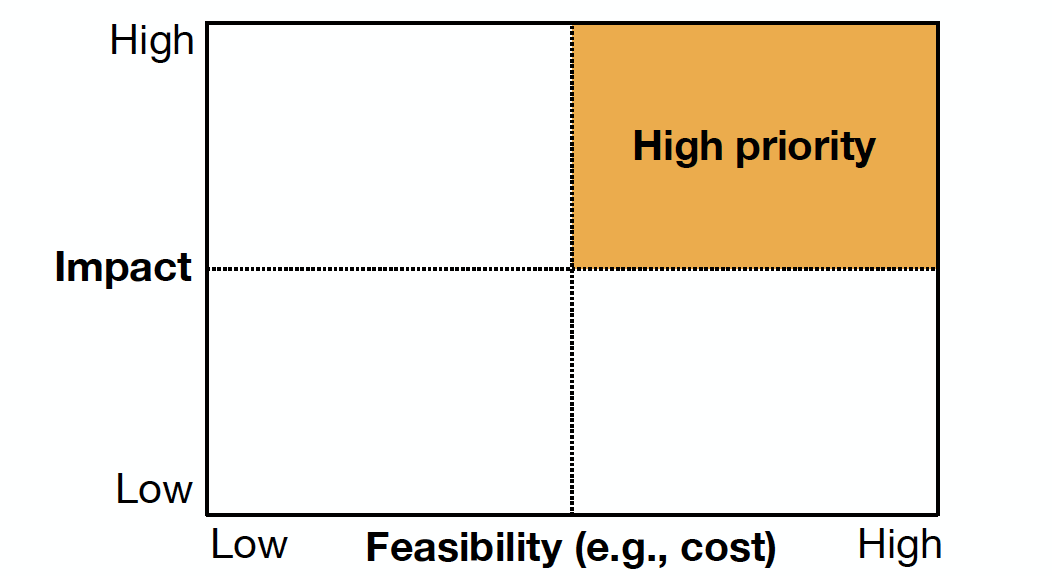
영향도 평가: 니즈(Needs). 니즈를 파악하는 것은 얼마나 의사결정 과정에서 마찰을 경험하고 있는지를 파악해보는 것이다. ML의 장점(Strength)은 Software 2.0(데이터가 많아질 수록 성능이 강력해지는 소프트웨어)과 데이터가 실제 복잡한 규칙기반의 소프트웨어이며, 이 규칙이 데이터로 학습할 수 있는 지를 의미한다.
실현가능성 평가(Feasibiltiy): 실현 가능성을 평가하는 것들중에 비용이 많이 드는 순서로 문제의 난이도 -> 요구되는 모델의 정확성 -> 사용가능한 데이터순으로 높다. 첫 째로 가장 문제가되는 데이터는 "데이터가 많은지", "얻기 쉬운지?", "얼마나 많이 필요할지" 등이다. 흔히 생각할 수 있는 내용이다. 둘 째로, 모델의 정확도 요구사항은 혹시 모델이 틀렸을 때 얼마나 비용이 많이 드는지, 어느정도 정확해야 쓸만한지, 윤리적인 이슈는 없는지에 관한 내용이다. 마지막으로 문제의 난이도는 "문제가 잘 정의도리 수 있는지", "이전에 해결한 문제들은 없는지" 컴퓨팅 요구사항"은 되는지, 사람이 할 수 있는일인지에 관한 내용이다.
아키텍처(Archetypes)
ML 프로젝트의 메인 카테고리로, 프로젝트 관리 및 구현을 어떻게 할 것인지에 관한 내용이다. 이 챕터는 그 원형(Archetypes)에 대한 얘기로, 크게 3가지로 분류되며, Sofware 2.0, HITL(Human in the loop), Autonomous system이다. 본인이 풀고자하는 문제들이 어느부분에 해당하는지, 어떻게 구현되는지 개념적으로 명확히 이해하는데 도움을 줄 수 있다.
- Software 2.0: 소프트웨어의 성능이 데이터가 많아질 수록 강력해지는 것을 의미한다. 기존의 규칙기반 시스템을 능가하는 것을 의미한다.
- HITL: 사람의 컨펌하에 쓰는 소프트웨어이다. 가령, 구글 이메일 작성시, 오토 컴플릿되는 것을 의미한다.
- 자동화 시스템: 사람 손을 안타는 시스템이다.
평가지표(metrics)
위의 내용처럼 어떻게 구현하겠다라는 가이드가 잡히면, 실제로 어떤 지표를 삼아야 성공여부를 달성했는지, 효율적으로 평가할지를 알 수 있다. 당연하겠지만 평가도구는 모델의 성능을 평가할 수 있는 지표를 삼아야한다. 처음에는 모델을 성능을 단순히 평가할만한 하나의 지표로 삼다는다. 그 후에, 안정화되면, 여러 평가지표를 복합적으로 쓸 수 있다. 가령, 평균적인 모델의 성능은 어느정도가 되어야하는지지표(average)와 지표를 넘는지 안넘는지 임계치(Threshold)로 계산해볼 수 있다. 가령 임계치는 모델 몇 MB이하여야한다 정도로 써볼 수 있다.
베이스라인 모델 구하기
실제 ML프로젝트를 하다보면 무조건 SOTA(State of the Art)부터 가져와서 적용할라다보니까, 어렵다. 그리고, SOTA을 적용하다가 너무어려워서 다 따라가지도 못하고 접는 경우도 생긴다. 그리고 SOTA부터 적용하니까 어느정도가 적정한 모델 성능인지 파악하기 어렵다. 베이스라인 모델을 구해서 적용해보는 것은 위의 내용을 파악하는데 도움을 준다. 베이스라인 모델은 대강 우리의 모델이 어느정도 성능이 나올 것이다하는 바로미터로 써볼 수 있다. 예를 들어, 질병 추천시스템의 Top 5 Recall이 대충 선형회귀로 해도 80%가나오면 이문제는 어느정도 풀만한 모델이고, 잘만하면 90%도 나올 수 있다는 것을 알 수 있다.
'Data science > MLOps' 카테고리의 다른 글
| 쿠버네티스 오류 해결: The connection to the server localhost:8080 was refused - did you specify the right host or port (0) | 2022.07.26 |
|---|---|
| [Kubernetes] Controller 이해하기 (0) | 2022.07.26 |
| Kubernetes: Pod 이해하기 (Init container, livenessProbe, Infra container, static pod) (0) | 2022.07.15 |
| 쿠버네티스 클러스터 구성 / 실습 (0) | 2022.07.10 |
| Kubernetes Namespace, Pod, Service ,Replicaset 설명 (0) | 2022.06.23 |



