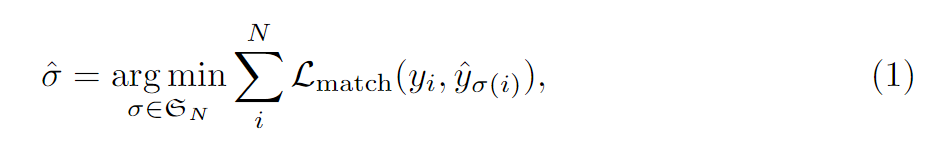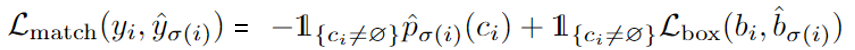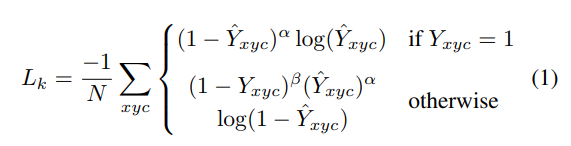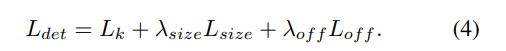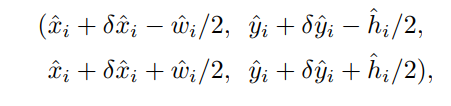일반적으로 딥러닝이 텍스트나, 이미지 데이터셋에서의 고성능을 보이지만, 정형데이터(Tabular dataset)에서 성능이 우월한지는 잘 밝혀지지 않았습니다. 오히려 안좋은 경우도 있습니다. 이 논문은 실제로 그런지 딥러닝과 트리기반모델(RF / XGBoost)을 비교했고, 뉴럴넷(NN)이 성능이 그렇지 좋지 못하였다는 실험결과를 보여줍니다. 그리고, 이 이유에 대해서는 아래와 같이 설명합니다.
정보량이 별로 없는 특징값에 대해서도 강건하다는 것(robust)
데이터 방향(orientation을 유지해서) 학습이 잘 되도록 한다는 것
비정형적인 함수도 쉽게 학습이 된다는 것입니다(딱딱 끊기는 함수도 학습이 잘됨).
Preliminary
Inductive bias: 훈련되어지지 않은 입력에 출력을 예측하는 것. 학습을 한적이 없지만, 그간 보아왔던(학습했던)데이터를 이용하여(=귀납적 추론), 알고리즘이 예측하도록하는 가정입니다. 예를 들어, CNN은 Locality & Translational invariance, RNN은 Sequntial & temporal invariant, GNN은 permutational invariant 입니다.
도입
트리기반 모델은 대체로, 인공신경망보다 정형데이터에서 많이 성능의 우월함을 보였습니다. 아쉽지만, 이렇게 좋은 트리 기반모델은 미분이 불가능하기 때문에, 딥러닝과 혼합하여 사용하기 어렵습니다. 이 논문은 왜 트리기반 모델이 정형데이터에서 딥러닝 보다 우월한지를 보여주는 논문입니다.
방법론: 45개의 데이터셋에서, 딥러닝모델과 Tree기반 모델의 비교
OpenML에서 총 45개의 데이터셋을 만들었습니다. 이 데이터셋은 다음과 같은 선정기준으로 뽑혔습니다.
Heterogenous columns: 컬럼이 매우 이질적일 것.
Not high demiensional: 컬럼수가 행수에 비해서 1/10미만일것
Undocumented dataset: 너무 정보가 없는 경우는 제외.
IID: 이전 데이터가 직전데이터의 예측에 연관된 경우(예, 타임시리즈 제외)
Realworld data: 합성데이터 아닐 것 6. Not too small: 너무 적지 않을 것 (특징값 <4 , 행수 <3,000)
벤치마크에서 분류든, 예측이든 트리기반모델이 더 고성능을 보였습니다. (Figure 1, Figure 2). Figure 1은 연속데이터만 있는 경우, Figure 2은 연속+카테고리데이터 둘다 있는 데이터입니다. 두 종류의 여러 데이터에서도 트리기반이 더 우수했습니다.
Dicussion:왜 Tree 모델이 Tabular데이터에서는 더좋은가? 3가지 이유
Discussion왜 더 좋을까? 크게 3가지 이유 때문에 좋다고 주장합니다.
뉴럴넷은 smooth solution 을 inductive bias을 갖기 때문에: 연구자들이 훈련데이터를 가우시안 커널을 이용하여 조금더 soothing하게 펼친 데이터를 만들고, 트리기반모델과 신경망모델을 비교했습니다. 신경망모델은 성능이 적게 떨어지는 반면, 트리기반모델은 급격히 떨어집니다 (Figure3). 이는 트리 기반모델이 예측시에 비선형 if, else등으로 자잘하게 쪼개는 반면, 뉴럴넷은 부드럽게 예측구분을 나눠주기 때문이라는 근거의 결과가 됩니다 (Figure 20).
인공신경망은 별로 정보량없는 데이터에대해 영향을 많이 받음: 정형데이터는 꽤 정보량없는 특징값이 많습니다. 랜덤포레트를 이용하여, Feature importance가 작은순으로 특징값을 제외시켜나가면서, GBT(Gradient boosting Tree)을 학습시켜나갔더니, 특징값이 꽤 많이 없어질때까지 좋은 성능을 냅니다 (Figure 4).인공신경망에서도 비슷한 패턴이보이긴합니다 (Figure 5). 하지만, 불필요한 정보를 특징값으로 넣는 비율이 클수록, 트리기반 모델보다 급격히 성능이 하락합니다 (Figure 6)
인공신경망은 데이터를 rotation해도 비슷한 성능을 낸다고 합니다. [Andre Y. Ng, 2004]. 딥러닝자체가 rotationally invariant하다는 것인데, 데이터를 회전시켜도 학습이 잘된다는 말입니다. 즉, 메트릭스 중에 행 또는 열을 일부를 제거한다고해도 , 딥러닝알고리즘은 rotation에 맞게 학습한다는것입니다. Tabular 데이터는 실제로 돌리면 다른 데이터인데, 인공신경망은 학습을 이렇게 해왔기 때문에, 성능이 감소한다는 것입니다. 실제로 데이터를 돌려서 학습시켜도 다른 모델에 비해서 성능이 하락하지 않습니다 (Figure 6).
DERT(Detection TRansofmer, 2020)은 객체검출(=Object detection)을 시항 할 때, 복수의 객체를 동시에(=페러렐하게) 예측하는 방법론을 고안한 모델입니다. DERT은 모델이 고정되어 있는 것이 아닌, 하나의 파이프라인으로 동작할 수 있고, 이 파이프라인에서는 NMS와 같은 후처리 공정이 들어가지 않게 고안된 파이프라인이라는 점이 특징입니다. 이 DERT은 Anchor free로 동작하고, 복수의 오브젝트를 예측하고, 각각의 실제 객체에 할당할 수 있도록 하도록 고안한 손실함수(Set-based global loss)을 이용하여 학습합니다.
사전 개념(Preliminary): Anchor-free, Set prediction
1. Anchor basevsAnchor free: 앵커는 이미 정의된 오브젝트의 중앙점 또는 박스를 의미합니다. 영어로는 Pre-defined bounding box라고도 합니다. 이를 이용하여 예측을 하는 경우, Anchor based object dection이라고 합니다. 예를 들어, 아래의 그림과 같이 파란색이 앵커라고하면, 사실 이런 파란색 앵커들이 훨씬 이미지에 많습니다. 그 다음에 가장 IOU가 높은 앵커를 찾고, 이 앵커를 조정하여 객체인식을 하는 방식입니다. 아래의 그림(Figure 1의 좌측 그림)은 여러 앵커중에, IOU가 높은 앵커를 선택하고, 이 앵커를 조정하여 ground truth을 조정하는 방식입니다. [1], [2]. 반면 Anchor free 은 이러한 사전정의된 박스없이, 오브젝트의 중앙점, 가로, 세로를 바로 예측하는 접근 방법론을 의미합니다.
Figure 1. Anchor based vs Anchor Free의 비교 시각화: 이미지 출처 Wang, C., Luo, Z., Lian, S., & Li, S. (2018, August). Anchor free network for multi-scale face detection. In 2018 24th International Conference on Pattern Recognition (ICPR) (pp. 1554-1559). IEEE.
2. Set prediction: 복수의 객체를 동시에 예측하는 것을 의미합니다. 객체를 하나하나 예측하는 방법과 대비되는 개념입니다.
Introduction (도입부): 여태까지는 Set prediction을 할 때, 후처리 성능의 의존적이 었음 => 후처리 없애고, End-to-End로 예측하는 모델을 만들어봄
Set prediction이 없던 것은 아니었습니다. 다만, 여태까지는 Set prediction을 간접적인 방법으로 예측 또는 분류를 하고 있었는데, 이러한 방법들은 오브젝트에 바운딩박스가 여러 개가 예측될 때, 후처리하는 방식에 성능이 영향을 많이 받았습니다. 본 모델은 이러한 후처리 방식을 없애고 End-to-End로 이미지를 입력받아, 객체검출을 하는 방식의 파이프라인입니다. 파이프라인이라 한 것은 이 모델에 백본(backbone)으로 쓰이는 모델들을 충분히 변경하며 다양한 아류들을 만들어 낼 수 있기 때문입니다.
Method: 1) 백본으로 이미지 특징값을 뽑아, Transformer 전달하여 이미지의 객체를 예측, 2) 오브젝트와 실제오브젝트를 매칭하기 위한 Bipartite matching
아래는 DERT가 Set predcition을 진행하는 과정의 전체적인 파이프라인을 보여줍니다. 한 이미지가 들어오면, Pretrained model(본문에서는 Backbone 등으로 표현)모델로 추론을 합니다. 그렇게 얻어진 이미지 특징값들을 Transformer에 전달합니다. 이 transformer 내의 decoder에서 반환되는 예측치가 오브젝트의 예측치로 생각하는 것입니다.
위의 그림을 보면, 크게 1) Backbond, 2) encoder, 3)decoder, 4) Feedforward network(prediction)으로 구성됩니다.
1. Backbone: CNN(convolution neural network)으로 이미지의 특징값을 압축합니다. 보통 3채널의 이미지가 들어오면, CNN을 통과시킨다음에, feature 채널수가 2,048개, 가로, 세로는 원래 H/32, W/32만큼으로 축소하여 전달합니다.
2. Transformer encoder: 1x1 CNN을 이용해서 2,048의 특징값채널을 d채널로 까지 압축시킵니다. 그렇게 만들어낸 특징은 z0입니다. (d,H,W)의 차원을 갖습니다. 이렇게보면, 이미지가 3 x H, W을 넣어서 d x H x W가 되었습니다. 이렇게 된 H, W은 각각 의미가 있습니다. 각 픽셀이 원래 위치하고 있는 위상들이 각각 의미가 있다는 의미입니다. 따라서, Positional encoding을 더합니다. 이는 Transformer에서 위상정보를 추가로 덫대어 학습시키기 위한 전략인데, 이미지에서도 마찬가지로 쓰일 수 있습니다. 트렌스포머 아키텍처는 입력의 순서에 상관이 없는 (Permuational invariant)하기 떄문에, 포지셔널 인코딩을 더한다라고 생각하시면 됩니다.
3. Tansformer decoder: 디코더는 인코더의 출력과, 오브젝트 쿼리(Object queries), 포지셔널 인코딩을 입력으로 받습니다. 오브젝트쿼리가 좀 생소한데, 0,0,0,0값을 넣는것은 아니고, N개의 오브젝트를 무조건 반환한다고 했듯이, N x 임베딩(d)의 차원을 가진 traininable parameter에 해당합니다. 이를 입력 값으로 받아, 멀티헤드어텐션을 이용하여 각 N개의 상호작용을 함게 학습합니다. 이전 Transformer와의 차이점도 있는데, 주요 차이점은 원래 Transformer은 반환되는 값을 다시 Transformer decoder에 넣는다는 점인데, 본 DERT은 그렇지 않습니다. (*쿼리 오브젝트는 Embedding 레이어의 weight을 사용하여 구현합니다.)
4. FNN(feed forward networks): 마지막레이어에 해당됩니다. Fully connected layer 3개와 각각 ReLU을 중첩하여 사용합니다. 각각은 아래의 그림과 같이 Class 라벨예측, Bounding box예측에 사용됩니다.
Transformer을 사용하는 이유? 이 파이프라인은 Transformer을 썼는데, Self-attention을 모든 Sequence에 대해서 NxN으로 계산하여, 상호작용을 다 계산할 수 있듯(all pairwise interaction) 이미지에서도 각 객체의 예측치가 중복되지 않을 것이다라는 예상을 하고 Transormer을 사용하는 것입니다. 저자들도 이 점을 방점으로찍습니다.
DERT의 가장 중요한 점은 1) set predition loss을 이용해서, 학습당시에 예측치의 객체가 실측치의 객체에 중복할당되지 않도록 유도하는 것이고, 2) 하나의 파이프라인으로 오브젝트끼리 관계를 학습해서, 한번에 오브젝트를 예측하는 것입니다. 아래와 같이 정확한 기술사항을 작성해봤습니다.리 정의되어야하는 것은 N입니다. N은 예측할 오브젝트의 개수. DERT은 어떤이미지가 주어지더라도 N개의 오브젝트를 반환합니다. 다만 N개 중에 confidence가 낮은 것만 제거하면 됩니다. 통상, 예측하고자하는 오브젝트보다 큰 숫자를 설정하면 됩니다.
Bipartite matching cost
- 필요성: 위의 사항은 한 문제를 야기하는데, 예측하는 오브젝트의 개수가 무조건 N개만 반환되고, 실제 오브젝트가 이보다 작은 K개라면, 중복이 될 수도 있고, 남는 예측치는 어떻게 할 것인가에 관한 문제입니다. 이를 해결하기위해서 Bipartite matching cost을 정의합니다.
Notations:
y: ground truth 오브젝트의 집합. 이 집합이 N보다 작으면 패딩($\phi$ = 오브젝트가 없음을 의미)할 수 있음
$\hat{y}$: 모델이 예측하는 N개의 오브젝트의 집합
다시 식을 보면, 앞에 $\sigma$ 은 예측치에 대한 순열이며, N개니까 N!만큼 순서가 의미가있는 조합이 생깁니다. 가장 이상적인 예측치는 아래 그림과 같습니다. 각 원은 실제 벡터입니다. 단순히 벡터라고 생각하지않고, 모델이 예측한 예측치1이 실측치1에 상응하게되면, 둘의 차이가 가장 줄고, 예측치K이후부터는 모든 값이 0인 경우가 오차가 가장 적을 것입니다. 이러한 조합을 여러번 계산하는 이유는 Transformer에서 반환되는 오브젝트의 순서가 의미가 없기 때문입니다. 이 의미없는 오브젝트의 예측에서, 실측치에 하나씩 상응시키기위해 이러한 작업을 합니다. 이 작업은 앞서 경우의수가 N!이나 된다고 했습니다. 컴퓨터로도 계산하기 너무 많은 양이지만, 다행스럽게 헝가리안 알고리즘(Hungarian algorithm)을 이용하면 계산식의 부담을 줄일 수 있습니다. 이 알고리즘은 본 포스팅에서 다루지 않습니다.
Figure 2. Matching cost가 가장 낮은 경우에서의 이상적인 예측치 및 실측치의 구성.
식은 위와 같습니다. L matching은 클레스라벨, 오브젝트의 중앙부, 폭, 높이가 얼마나 차이나는 지를 계산하는 것입니다. y 및 $\hat{y}$ 내의 원소에 해당하는 값들은 실제 튜플 또는 벡터로 표현해볼 수 있고, 총 값은 5개로 표현됩니다. $y_{1}=(c_{i}, b_{i})$. c은 라벨을 의미하며, b은 중심점의 x,y, 높,너이입니다. 그리고 L_match의 앞에텀은 클레스가 맞았는지, L_box은 예측한 오브젝트가 실측의 오브젝트와 거리가 가까운지를 측정하는 손실함수입니다. 당연히 ground truth가 패딩된 것이 아닌 것에 대해서만 계산합니다. Bounding box loss은 GIOU을 사용합니다.
결과(Results)
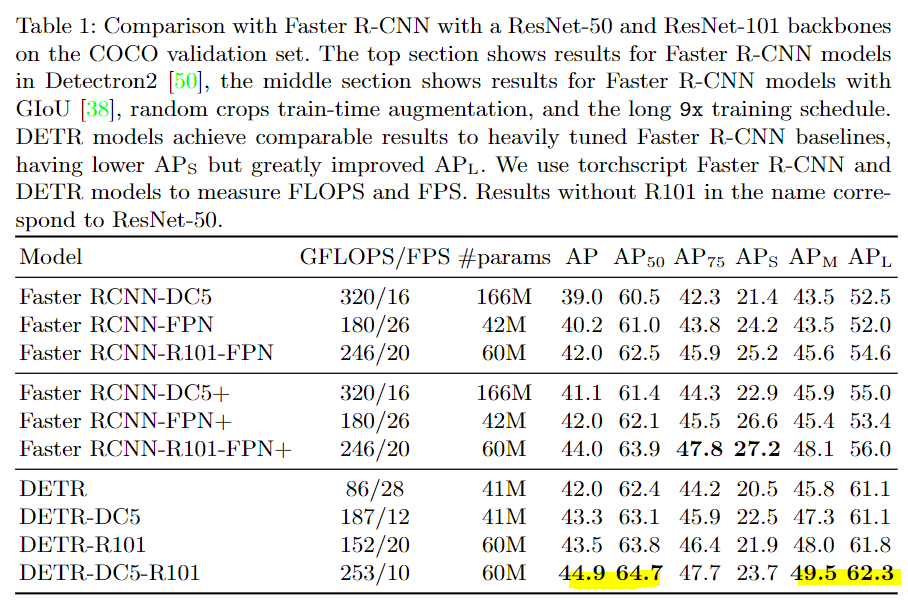
첫 번째 결과로는 Faster R-CNN과 2개의 백본으로 실험한 DERT와의 성능비교입니다. 데이터셋은 COCO이며, DC은 Dilate C5입니다. DERT-DC5-R101의 아키텍처가 가장 우수한 성능으보이며, 파라미터수도 적었습니다.
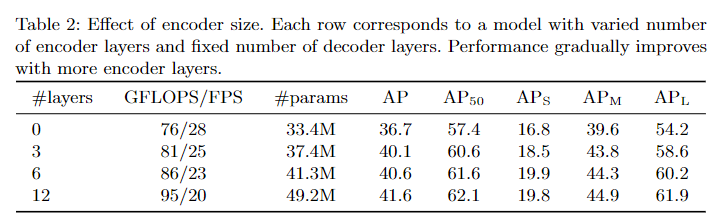
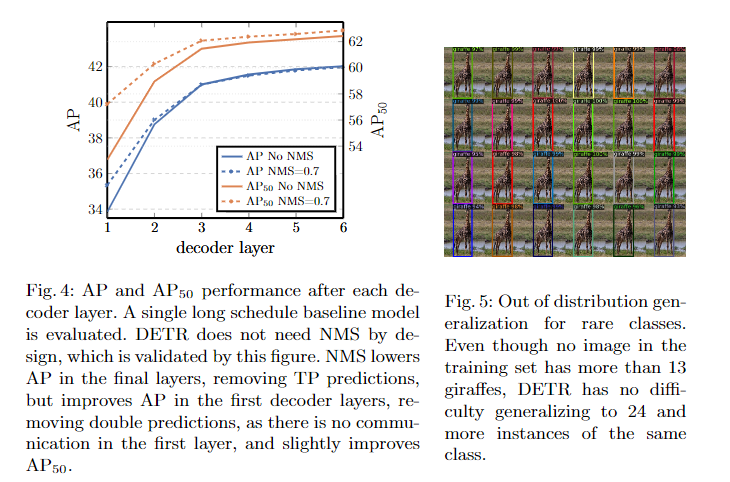
2) 인코딩레이어가 어느정도 성능을 내고있음. 인코딩레이어의 수를 0으로하면, 추론속도를 빠르게할 수있지만 AP가 감소함.
3) 디코더 레이어도 어느정도 성능에 필요함: 디코딩레이어의 수를 없앨수록 성능이 저하됨.
4) 인코더부분의 self-Attention시각해보니, 각객의 개별인스턴스를 잘 예측하도록 Attention map이 구성되어있었다. = 각 인스턴스를 예츠갛도록 Attention이 동작하고있다는 것을 보여줍니다. 언어학에서 중요한 토큰을 보여주듯, 각 인스턴스에 대해서 토큰을 보여주는 형태라고 생각하면 됩니다.
5) GIOU + L1로스를 같이 쓰는 경우가 성능이 제일 좋았다는 결과입니다.
6) 디코어의 attention을보면 각각의 attention score(=attention weight * features)가 경계면에 가중치를 두는 것을 볼 수 있습니다. 즉 바운딩박스를 만들기에 중요한 경계를 보고잇다라고 주장하는 근거입니다.
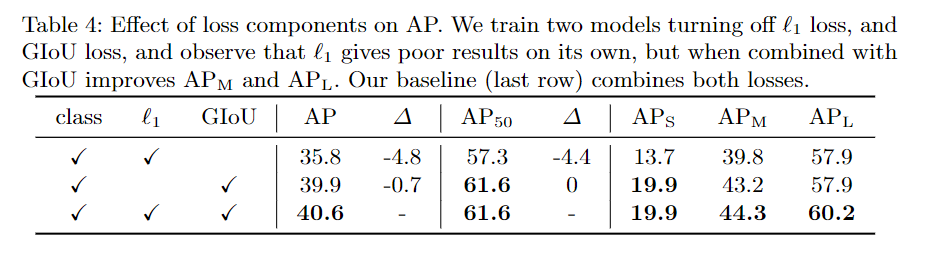
7) 각각의 예측하고자하는 오브젝트쿼리에 따라서, 주로 보는 영역들이 다르다는 것을 보여주는 그림입니다. 해석: 녹색점은 각 예측치에 해당하는 점입니다. 작은 점은 매우 넓은 분포를 가지고있습니다. 반면, 빨간점은 가로로 긴 박스의 예측치의 중앙부입니다. 가로로 길기 때문에, 이미지내에서는 보통 중앙부에 있을 것입니다. 각 예측치의 크기에따라 어느부분을 중점적으로 관찰하는지에 대한 시각화라고 볼 수있습니다.
참조(References)
[1] Wang, C., Luo, Z., Lian, S., & Li, S. (2018, August). Anchor free network for multi-scale face detection. In2018 24th International Conference on Pattern Recognition (ICPR)(pp. 1554-1559). IEEE.
Non maximal supression(NMS)은 예측된 오브젝트의 바운딩박스(bounding box)가 중복으로 여러 개가 할당 될 수 있을 때, 중복되는 바운딩박스를 제거하는 기술입니다. 기계적으로 무엇인가 학습하여 처리하는 것이 아닌, 사람이 고아낸 로직대로 제거하는 방식이기 때문에, 휴리스틱한(또는 hand-craft)한 방법으로도 논문에서 주로 소개가 됩니다.
Figure 1. 한 오브젝트(포메라니안)에 다수의 바운딩박스가 예측된 예시. NMS은 이러한 여러박스 중에 최적의 박스남기는 작업이다.
NMS을 구현하는 방식은 아래와 같습니다.
각 바운딩 박스별로 면적(area)을 구합니다.
특정 박스를 하나 정하고, 정해진 박스외에 나머지 박스와의 오버렙 비율을 구합니다.
두 박스의 x_min, y_min중에 최대를 구하면, 아래의 박스(//)의 좌상단 좌표를 구합니다.
두 박스의 x_max, y_max중에 최소를 구하면, 아래의 박스(//)의 우하단 좌표를 구합니다
교집합의 박스와, 다른 박스들과의 오버렙 비율이 특정값(cutoff)이상을 넘기면, 1에서 지정한 박스를 삭제합니다(=인덱스를 제거합니다)
이를 계속 반복합니다.
가령 아래와 같이 COCO 포맷(좌상단X, 좌상단Y, 가로, 세로)의 바운딩박스가 예측되었다고 생각합시다. 그러면, 첫 번째 [317, 86]의 바운딩박스에 대해서, 첫번째 바운딩 박스를 제외하고, 모든 바운딩박스와의 오버렙을 계산하면 됩니다.
Information content (IC)은 언어학에서 나왔던 개념으로,문맥상에 어떤 개념이 나타내면, 이 개념이 나타내는 것은 정보의 양을 나타냅니다. 주로, 추상적인 개념(상위 개념)일수록 정보량이 많지 않기 때문에, IC값이 낮아지도록 표현이 되고, 구체적인 개념을 일컫을 수록 IC값이 높아지게 됩니다. IC값을 적절하게 설계했으면, 각 개념(또는 단어)가 얼마나 모호한지(=상위개념인지)를 알 수 있습니다. 그리고, 이러한 IC값을 온톨로지들 간의 유사도로 사용할 수 있습니다.
IC의 정의는 아래와 같습니다. 온톨로지 상에서 존재하는 모든 개념($C$)내에 특정 개념($c$) 은 $c \in C$이며, 0과 1사이 값을 가진다고 합니다[0, 1]. 그리고, 특정 두 개념이 IS-A 관계라고 하면, $c_{2}$가 상위텀이라면, $p(c_{1}) <= p(c_{2})$여야 합니다. 그리고, 최상위노드가 하나라면, 이 최상위 노드의 확률값은 1이 되게도록 확률을 정의합니다 [1]. 이때 IC값은 다음과 같습니다.
$IC = -log p(c)$
예를 들어, WordNet의 말뭉치내에, 아래와 같은 분류체계가 있다고합시다. 분류체계내에 하위텀으로 갈수록, 구체적이기 때문에, 빈도가 적게나오고 정보도 많을 것입니다, 반대로 상위텀일수록 추상적이 많이 나온 개념이기에, 위로갈수록 확률은 높아집니다. 이러다 극단적으로 최상위개념이면, 모든 개념을 포함하기에 확률을 1로 합니다. IC값은 logP(c)이므로, [0과 1]의 p값이 클수록 (=0.99999)에 가까울수록 0으로 수렴합니다. 반대로 0에 가까울수록 값이 엄청나게 음수가됩니다. 이 음수가된 것을 다시 -을 취하니 값은 커지게 됩니다 (Figure 2).
Figure 1. 자료. https://www.ijcai.org/Proceedings/95-1/Papers/059.pdfFigure 2. Log fucntion. (https://saylordotorg.github.io/text_intermediate-algebra/s10-03-logarithmic-functions-and-thei.html)
Resnik의 semantic similarity (1995)
1995년에 Resnik은 IC을 이용해서 두 개념이 의미론적으로 얼마나 유사한지를 측정할 수 있게 했습니다. 두 개념의 유사도를 측정하기위해서 아래의 공식을 사용합니다 [2].
where S(c_{1}, c_{2}) is the set of concepts that subsume both $c_{1}$ and $c_{c2}$
위의 개념에서 subsume은 "포함하다"를 의미합니다. 즉, c1, c2을 포함하는 집합을 의미하므로, 두 개념을 포함하는 상위개념들의 집합을 의미합니다. 두 개념을 포함하는 상위집합중에서 가장 IC가 높은것을 의미하므로, "두 개념을 포함하는 상위 개념중에 가장 아래에 있는 개념(=구체적인 개념)"을 의미합니다.
Figure 1에서 S(nickel, dime)은 COIN, CASH, MONEY, MEDIUM OF EXCHANGE...등을 포함하고, 두 개념의 유사도에 쓰이는 c은 이 중에거 가장 하위에 있는 것이기 때문에, COIN이 됩니다. 즉 COIN의 -logP(c)을 구하면됩니다. 이 P(c)은 문제마다 다르므로 구체적인 내용은 스킵합니다. 단, 이를 구하는 예시를 하나 들어보자면, 일반적인 자연어처리문제라면, 전체 corpus가 있을 것이고, 이 corpus에 단어가 전체 K개가 있다고 합시다. 그리고 워드넷이라는 taxonomy에 들어있는 개념이 h개 라면, 전체 N은 각 h가 corpus에 얼마나 있는지를 세어보면 알 것입니다. 그리고 N중에 실제 각 개념 c들이 얼마나 있는지 상대적인 빈도로 제시합니다.
Figure 3. Resnik의 WordNet에서의 IC계산 사례
[1] Ross, S. M. (2019).A first course in probability. Boston: Pearson.
[2] Resnik, P. (1995). Using information content to evaluate semantic similarity in a taxonomy.arXiv preprint cmp-lg/9511007.
master node에 쿠버네티스를 세팅하고, 각 노드랑 연결해보려고합니다. 쿠버네티스로 클러스터를 구성하는 것은 1) control-plane을 설치해야합니다(단일 control-plane또는 복수의 control-plane도 가능), 2) 또한, 각 워커노드들을 등로갛여 파드들의 네트웍이 클러스터내에서 잘 통신되게 하는 것입니다.
시작전에 앞서
kubeadm을 이용해서 쿠버네티스를 세팅해보려고합니다. kubeadm으로 쿠버네티스를 세팅하는 것이 쿠버네티스 공식홈페이지에서도 "best practice"라고 설명되어있습니다. kubeadm은 쿠버네티스를 간단히 설치해서 사용해보기에 용이합니다.
사용 전 확인사항
쿠버네티스를 사용하기전에 장치에 아래의 스펙요구사항을 만족하는지 확인해야합니다.
A compatible Linux host. The Kubernetes project provides generic instructions for Linux distributions based on Debian and Red Hat, and those distributions without a package manager.
2 GB or more of RAM per machine (any less will leave little room for your apps).
2 CPUs or more.
Full network connectivity between all machines in the cluster (public or private network is fine).
Unique hostname, MAC address, and product_uuid for every node. Seeherefor more details.
Certain ports are open on your machines. Seeherefor more details.
Swap disabled. YouMUSTdisable swap in order for the kubelet to work properly
마지막의 swap을 끄라고 되어있는데 이는 "kubelet"이라는 데몬이 정상적으로 돌게하기위함이라고 합니다. "kubelet"은 파드에서 컨테이너들이 "선언적으로 정의한"(=내가 세팅한 그대로 현 상태를 유지해주는 것)대로 실행되게끔 해주는 데몬입니다.
본 포스팅에서는 카카오클라우드를 이용해서 private network로 구성된 클러스터를 구성해볼 예정입니다. 사설 IP로 구성된 노드들은 아래와 같습니다.
MAC address가 유요한지 product uuid가 각 노드에서 유니크한지 확인합니다. 아래의 명령어를 이용해서, 각 노드에서 MAC adresss, product_uuid가 유일한지 확인해봅니다. 일단은 마스터노드만 확인해봅니다.
ubuntu@k8s-master:~$ ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback [.........]
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether [..........]
ubuntu@k8s-master:~$ sudo cat /sys/class/dmi/id/product_uuid
[...........]
K8S을 설치하기전에 필수로 설치해야할 것이 docer가 있습니다. Docker은 다음의 링크로 설치하시길바랍니다 [1]
kubeadm, kubelet, kubectl을 설치할 것입니다. 각 기능은 아래와같습니다.
kubeadm: 클러스터를 구축하고 실해나는 과정을 의미합니다 (=cluster bootstrap). control-plane, worker nodes을 구성하고 각 노드들끼리 올바른 정보들을 가지고있는지, 통신이 한지를 확인합니다. [2]
kubelet: 선언적으로 정의한 대로 파드를 시작하거나, 컨테이너를 시작해주는 기능을 합니다.
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
# 하단의 명령어는 적을 수 있다면 잘 기록하시길 바랍니다.
kubeadm join 172.16.2.231:6443 --token y24p4r.7itfeqy96rkjof8q \
--discovery-token-ca-cert-hash sha256:5e9e43eadba4eb7858033de6fbb4d99cc811f7d49d96f3637435370463c087e
클러스터의 실행을 위해서 위의 나온 메시지대로 $HOME/.kube/config 파일을 설정합니다. (일반사용자로 전환후)
// 명렁어로 토큰 출력
# kubeadm token list
// 아래의 명령어로 해시 출력
# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
control-plane에서만 deployment을 실행하면 파드가 생성되지않음을 확인할 수 있습니다. deployment에는 replicas 수를 3으로 지정해놓았는데요. 할당할 worker노드가 없기 때문에 pending으로 나온 것으로 판단됩니다. 실제로 하나의 파드의 상태를 추적해보면 아래와 같습니다.
root@k8s-master:/home/ubuntu# kubectl apply -f controllers-nginx-deployment-yaml
deployment.apps/nginx-deployment created
# watch "kubectl get pods"
Every 2.0s: kubectl get pods k8s-master: Sun Jan 8 09:00:15 2023
NAME READY STATUS RESTARTS AGE
nginx-deployment-85996f8dbd-98xlx 0/1 Pending 0 118s
nginx-deployment-85996f8dbd-d9bhg 0/1 Pending 0 118s
nginx-deployment-85996f8dbd-kjk8t 0/1 Pending 0 118s
root@k8s-master:/home/ubuntu# kubectl describe pod nginx-deployment-85996f8dbd-98xlx
Name: nginx-deployment-85996f8dbd-98xlx
Namespace: default
Priority: 0
Service Account: default
Node: <none>
Labels: app=nginx
pod-template-hash=85996f8dbd
Annotations: <none>
Status: Pending
IP:
IPs: <none>
Controlled By: ReplicaSet/nginx-deployment-85996f8dbd
Containers:
nginx:
Image: nginx:1.14.2
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-h2w8s (ro)
Conditions:
Type Status
PodScheduled False
Volumes:
kube-api-access-h2w8s:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 49s default-scheduler 0/1 nodes are available: 1 node(s) had untolerated taint {node-role.kubernetes.io/control-plane: }. preemption: 0/1 nodes are available: 1 Preemption is not helpful for scheduling..
root@k8s-test:/home/ubuntu# kubeadm join 172.16.2.231:6443 --token 8yxfot.ktr4irill5hqw6h7 --discovery-token-ca-cert-hash sha256:bd91d60981b5774add11106cd42e1f8d6db18b241b5fd529b0d638e713522494
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
control-plane (master node)로 돌아가, 파드가 정상적으로 실행되는지 확인합니다. nginx 서버 3개가 정상적으로 돌아가는 것을 확인할 수 있었습니다.
root@k8s-test:/home/ubuntu# curl localhost:30052
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
localhost말고, 외부에서 해당 노드로도 요청을 보내봅니다.
// 마스터노드에서 노드1의 사설IP:30052포트로 요청
ubuntu@k8s-master:~$ curl 172.16.2.253:30052
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
CenterNet은 기존의 Two stage detection방법(=한 객체에 대해서 여러 bounding box을 찾고, bounding box이 겹치는 영역을 줄이는 방법)이 비효율적인 것에 Motivaiton이 있습니다. 따라서, CenterNet은 효율적은 예측을 위해서 한 객체에는 하나의 Anchor(=center point, keypoint)만 있다고 가정하고, 이를 예측하는 문제로 바꿉니다. 일단 Anchor 을 찾고난 다음, 문제가 3D size, pose estimation이면 Anchor로부터 사이즈가 얼마인지 등을 추가로 예측하는 문제를 추가로 도입합니다. 모델 구조는 1) Heatmap: 각 객체의 Centerpoint 예측하는 출력층, 2) offset: Heatmap을 만드는 단계에서 Anchor와 원래사이즈에서의 Anchor을 보정하기위한 출력층, 3) size 예측: 각 객체의 Centerpoint으로부터, 객체의 사이즈를 예측하는 출력층으로 구성되어있습니다. [1]
Motivation (introduction): Two stage detection방법에 제한이 있어, One stage dection으로
현재 컴퓨터 비전에서 쓰는 대부분의 개체인식(Object detection)은 각 개체에 bounding box로 표현하는 것입니다. 보통 하나의 bounding box로 표현하기보다는 잠재적으로 될만한 bounding box을 다 찾습니다. 이 과정을 거치고나면, 하나의 객체에는 여러 bounding box가 생깁니다. 따라서, 최적의 bounding box(개체와 가장 근접하도록 작은 사이즈의 bounding box만 남김)을 만드는 작업을 합니다. 이러한 방법은 "Two stage dectecor"라고 합니다. 계산을 여러 번 하게되는 작업들을 아래와 같이 진행합니다 (Figure 3).
recompute image feature for each potential box: 잠재적으로 개체가 될만한 박스들을 다 계산하여 그립니다.
then, classify those feature: 이 박스들이 background일지 object일지 분류를합니다.
Post-processing (Non maximal supression): 최적의 박스만 남기는 작업을 진행합니다. bounding box의 IoU값을 계산하여 한 개체에 겹치는 부분이 있으면 해당 내용만 씁니다. 특히 이러한 후처리는 미분도, 학습도 어려워서 end-to-ent 모델에 담기가 어렵습니다.
그래서 나온것이 "One stage detection"입니다. 말 그대로 위의 단계를 하지않고, 하나의 단계로만 진행합니다. 이 단계는 가능한 하나의 bounding box을 만드는 것입니다. 이 하나의 bounding box의 중심을 anchor라고도 부릅니다. 일단 각 개체에 대해서 Anchor을 찾고나면, bounding box을 어디까지 그려야할지(size), 3D extent, orientation, post등은 중심점으로 부터 다 예측하겠다는 것입니다. 각 개체에 Anchor 만 찾고나면, 나머지는 부수적으로 예측하여 얻어낼 수 있다는 것을 상정하고 만든 모델입니다.
CenterNet은 어떤 로직? (method) : Heatmap, Offeset, Sizes 을 예측하기위해서 end-to-end로모델을 결합
CenterNet은 단순히 CNN으로만 이뤄져 있습니다. 구성은 인코더-디코더로 되어있는데, 디코더가 3개로 되어있습니다. 우선, 문제의 정의를 아래와 같이합니다.
입력 이미지: $ I \in \mathbb{R}^{W\times H\times 3}$. 가로의 크기가 W, 세로의 크기가 H인 이미지가 입력으로 주어진다고 가정합니다.
결과물 (heatmap): $\hat{Y} \in [0, 1]^{W/R \times H/R \times C}$. R은 stride, C은 키포인트 타입(클레스 타입)을 의미합니다. 즉 이미지가 STRIDE 떄문에 좀 작아지더라고 각 개체가 C클레스에 중심점이 될만한지 heamap을 찍는 것을 의미합니다. 예를 들어, C은 human pose 라면 관절 개수인 17개을 씁니다. stride인 R은 기본적으로 4을 씁니다. 그렇게되면 이미지가 작아지는(=downsampling)됩니다. 만일 예측치 $\hat{Y}_{x,y,c}=1$라면 keypoint을 의미합니다(=예측된 x좌표, y좌표에서 c클레스일 확률이 1이라면 그 부분이 중심점일 것이다) 반대로 0이라면 배경을 의미합니다(Figure 1).
Figure 1. Keypoint estimation 과 heatmap의 관계. STRIDE $R$ 때문에 downsampling된 heatmap의 예시. C가 80이라면 heatmap은 약 80개가 만들어지고, 각 C(클레스)가 될만한 heamtpa을 다 찍는다. 그중에 확률이 높은 클레스가 해당클레스일 것이다. 예를들어 dog class가 80번에 있다면, C=80인 heatmap에 $\hat{y}=1$인 지점이 2개일 것이다. 그리고 그 주변부에는 1에 가까운 수치들이 많을 것이다.
각 디코더의 역할을 아래와 같이 기술합니다.
Figure. CenterNet 아키텍처, 반환값 및 Ground truth, 및 loss의 관계
1. Heatmap 예측을 위한 decoder: CNN은 heatmap이라는 것을만드는데, heatmap에서의 중앙부가 개체의 중심부가 되도록 예측합니다. 즉 개체가 3개라면 가장 높은 점수가 3개(=본문 내 피크)가 있어야하는 것입니다. 그리고 각 이미지의 피크를 이용하여 bounding box의 가로, 세로도 예측합니다. 그리고 keypoint을 예측하는 과정에서 Stacked hourglass, up-convolutional residula network(ResNet0, deep layer aggregation (DLA)을 dencoder-decoder로 묶어서 사용합니다.
C 클레스가 될만한, heatmap의 정답은 [x, y]좌표로 2차원의 데이터로 표현할 수 있을 것입니다. 원래 이미지 사이즈를 heatmap에 맞추어야합니다. 이 과정을 위해서 원좌표 [x.y]을 아래와 같이 R로 나누어 floor만 씁니다. 예를들어 중심점의 좌표가 512, 512을 4로 나눴다면 딱 나눠떨어져서 128, 128이되겠지만, 중심점의 좌표가 총 512,512이미지의 중심점의 좌표가 111,111, R=4이라면 [27, 27] (27.75에서 0.75버림)으로 만든다는 것입니다.
이렇게 각 클레스 C에 맞춰 라벨을 heatmap에 맞춰 만듭니다. $Y \in [0, 1]^{\frac{W}{R}\times\frac{H}{R}\times{C}}$
그리고, 히트맵에 가우시안 커널을 적용하는데, 이는 keypoint가 단일의 점 [x,y]인 것에 비해서 예측치점이 $\hat{x}, \hat{y}$이기 때문에, 딱 하나의 점으로는 표현하자면 너무 예측이 어렵기에, ground truth keypoint주변으로 예측치가 어느정도 맞으면 가만할 수 있게끔 뿌려주는 역할을합니다. 가우시안 커널의 공식은 다음과 같습니다. 아래의 가우시안 커널에서 $\sigma^{2}_{p}$은 오브젝트 사이즈에 따라서 달라질 수 있다고합니다.
정리하면, 예측할 heatmap은 STRIDE R이 적용된 리사이즈된 heatmap($\hat{Y} \in [0, 1]^{W/R \times H/R \times C}$), 예측치도 같은 사이즈의 가우시안 커널이 적용된 이미지($Y \in [0, 1]^{\frac{W}{R}\times\frac{H}{R}\times{C}}$)입니다. 그럼 로스만 적용하면됩니다.
로스는 아래의 (식 1)과 같이 작성합니다. Focal loss을 적용합니다. 흔히 focal loss은 클레스불균형이 심할때 사용합니다. 예를 들어, 보험사기자, 신용사기자처럼 다수의 정상적인 사용자가 있고, 가끔 발생할 수 있는 사기의심자를 한 둘을 맞춰야할 때, 이 사기의심자를 틀린 경우에 많은 패널티를 주기위해서 제곱항을주는 방식입니다 [2].
2. Discretization error 보정: Local offset
- 위의 예시와 같이 keypoint가 STRIDE (R)로 나눴을 때 나눠떨어지지 않는 경우, 약간의 오차가 발생했습니다(예, 111,111, R=4이라면 [27, 27] (27.75에서 0.75버림)). 이 에러를 보정하기위해서 Local offset이라는 개념을 만듭니다. 오프셋의 정의는 아래와 같습니다.
각 오브젝트가 어떤 클레스가 될지에 따라서 k가 달라질 수 있다는 것입니다. 하지만, 이 예측치를 계산하는데는 연산이 오래걸려서 그냥 단일의 개체의 사이즈로만 판단하도록 변경합니다. 그래서 사이즈을 의미하는 값의 차원이 다음과 같이 바뀝니다. $\hat{S} \in \mathbb{R}^{\frac{W}{R}\times\frac{H}{R}\times2}$.
그리고 아래와 같은 L1 로스를 줍니다. 실제 bounding box의 x,y, 가 중심점일때의 가로,세로의 길이를 예측하는 문제로 정의하는 것입니다.
그리고, 이를 joint learning하기위해서 모든 로스를 다음과 같이 합칩니다.
Anchor로부터 Bounding box예측하기
bounding box예측은 heatmap과 offset, size prediciton을 다 이용하면됩니다.
1. 일단 Anchor을 찾습니다. Anchor가 될만한것은 Heatmap에서 비교적 높은 값들을 찾으면 되거나, 일단 Anchor포인트로부터 8개의 좌표값들을 비교했을때 anchor보다 크거나 같은 경우 그부분을 중심점이라고 둡니다. 그리고 기본적으로 CenterNet은 100개의 피크값을 뽑아냅니다. 최대 오브젝트가 100개라고 보는것이죠. 몇 개인지까지는 예측을 못하니...
2. 그리고 각 예측치를 아래와 같이 구합니다. $\delta\hat{x}_{i}, \delta\hat{y}_{i} $은 offset prediction의 결과입니다. 예측한 heatmap의 좌표가 stride R때문에 실제 이미지에서 약간 이동될 수 있으니, 이를 보정하해줍니다. $\hat{w}_{i}, \hat{h}_{i}$은 사이즈 예측치입니다. 사이즈 예측을 위해서 중심점으로부터 좌측하단, 우측상단을 구하는 공식입니다. 총 4개의 좌표가 나옵니다. 이렇게 진행하면 딱히 non-maxima suppresion 또는 후처리가 필요가 없습니다. 그렇기에 one-stage detection입니다.
CenterNet 성능(Result)
Table 1은 backbone 모델을 어떤것을 쓰냐에따라서, 성능, 계산시간을 보여줍니다. AP(average precision)은 hourglass-104가 제일 성능이 좋았으나, 추론시간은 좀 오래걸린다. 초당 detection, 추론성능은 ResNet-18이 가장 빠릅니다. augmentation , flpi, multi-scale등을 추가로해볼 수 있는데 각각에 대한 성능표입니다.
Table 2: coco dataset에서 대부분 알려진 모델들에서의 성능입니다. 위의 5개의 모델은 two-stage, 아래 모델들은 one-stage입니다. two-stage중에서는 MaskRCNN이 빠르내요. AP성능이 가장좋은것은 TridentNet입니다. 반면 one-stage에서는 Hourglass을 쓴 CenterNet이내요.
정리
엄청 월등한 성능의 예측력 또는 엄청난 계산효율은 둘다 보여준 것은 아니지만, one-stage 모델중에서는 준수한 성능과 빠른 계산량을 보여주는 모델이라고 할 수 있을 것 같습니다. key point estimation을 3가지 방식으로 loss을 주어 최적화하는 모델이어서 꽤 좋은 모델링인 것 같습니다.