요약
RandomForest 의 Feature importance은 여러가지가 있을 수 있지만 크게는 대표적으로 1) 불순도 기반 방식(Impurity based): tree을 나눌 때, 쓰이는 특징값으로 나눴을 때, 클레스가 잘 나뉘는 가 얼마나 변화하는지 측정하는 방식. 불순도의 변화가 크면 클수록 트리를 잘 나눴다는 것을 의미중요한 특징 값이라는 것, 2) 순열 기반 방식(Permutation based): 각 특징값을 데이터 포인터에 대해서 랜덤하게 순서를 바꿔서, 정확도가 떨어지는지 확인하는 방식. 정확도가 크게 떨어질 수록 중요한 특징값임을 가정하는 방식이 있다.
선행
랜덤포레스트는 이 포스팅에서 깊게 다루지는 않지만, 트리구조를 만들 때, 배깅(bagging) 중복을 포함해서 임의로 데이터를 N개씩 뽑고, Feature bagging (속성을 뽑을 때도 랜덤하게 K)만큼 뽑아서 각각의 트리를 만든다. 그렇게 만들어진 약한 분류기(Tree)을 여러개 만들고 분류모델이면 Voting하여 얻은 값을 반환한다.

Gini importance / Mean Decrease in Impurity (MDI)
이 방식은 Gini importance라고도 불리고, MDI라고도 불리는 방식이다. 의미하는 것은 모든 랜덤포레스트의 각각의 트리에서 해당 특징값으로 트리를 나눌 때, 감소한 불순도의 평균을 의미한다(For each feature we can collect how on average it decreases the impurity. The average over all trees in the forest is the measure of the feature importance[1]).
Gini impurity은 아래와같이 계산한다 (주의: Gini coefficient와 다른 내용이다).
$Gini impurity = 1 - Gini$
$Gini = p_{1}^{2}+p_{2}^{2}+...+p_{n}^{2}$
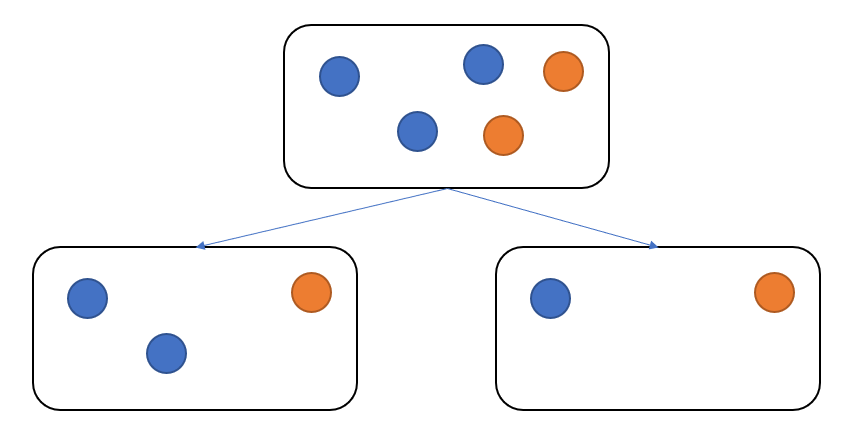
n은 데이터의 각 클레스를 의미한다. 가령 아래와 같이 주황색 데이터와, 파란색데이터를 구분하는 문제라면 n은 2가된다. 노드를 나누기전을 부모노드라고하면, 부모노드에서의 Gini은 파란색공이 5개중에 3개, 노란색이 5개중에 2개이므로 $Gini=(3/5)^{2}+(2/5)^{2}$가 된다. 따라서, Gini impurity은 $Gini impurity=1-(3/5)^{2}+(2/5)^{2}$이다. 그리고 나눈 후를보면, 좌측은 $Gini imputiry = 1- ((2/3)^{2}+(1/3)^{2}$. 우측은 $Gini imputiry = 1-((1/2)^{2}+(1/2)^{2})$ 이다. Gini impurity의 변화량이 얼마나 변화했는지를 파악하는 것이기 때문에, 다음과 같이 부모의 impurity - (자식노드의 imputiry의합)과 같이 계산한다.
$1-(3/5)^{2}+(2/5)^{2} - [(1- ((2/3)^{2}+(1/3)^{2}) - 1-((1/2)^{2}+(1/2)^{2})]$
위의 계산에서 중요한 것을 빠뜨렸는데 특징값 A에 대해서 위와 같은 과정을 진행했다고하면, 모든 노드 중에서 A을 이용한 분기에를 모든 트리에서 찾은다음에 평균낸 값이 Gini importance이다. 혹은, 어떤 방식에서는 나누려는 노드의 가중치를 곱해서 많이 나눴던 노드에서는 더 가중치를 주기도 한다.
아래의 그림을 보면 feature importances (MDI)라는 것이 표시되어있다. 이는 위의 과정(Gini importance)을 이용해서 각 노드를 나눴을때 불순도가 크게 변화하는 정도의 평균을 계산했다는 의미이다. (이 데이터셋은 타이타닛 데이터셋). 생존자와 사망자를 구분할 때, sex을 이용해서 구분했을 때, sex을 안썼을 때보다 평균적으로 더 트리구조가 깔끔하게 나뉘어져나갔다는 것을 의미한다.

Permutational importance / Mean Decrease in Accuracy (MDA)
Permutation importance은 트리를 만들때 사용되지 않았던 데이터들 OOB(Out of bagging, 랜덤포레스트의 각 트리를 만들 때, 랜덤으로 N개의 데이터를 중복을 포함하여 뽑는데, 그 때 사용되지 않았던 데이터들)을 이용하여, OOB인 데이터들에 대해서 해당 특징값을 랜덤하게 섞은후에 예측력을 비교한다.
아래와 같이 a,b,c,d,e,의 특징값을 가진 1,2,3,4,5번 데이터가 있다고하자. 모델을 빌딩할 때, 랜덤으로 뽑은 데이터가 1,3,5였고, 안타깝게 2,4번은 중복을 포함혀어 뽑았지만 뽑히지 않았던 데이터라고 하자.
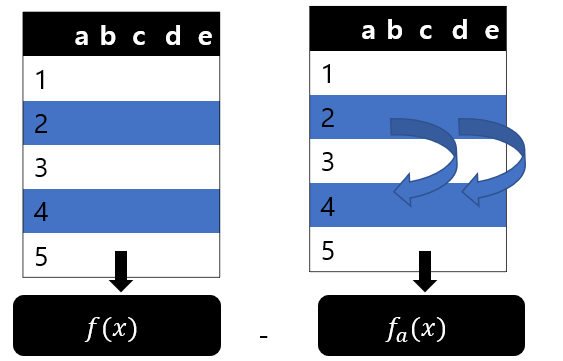
이 때, 특징값 a에 대해서 1,2,3,4,5번의 a특징값의 순서를 랜덤하게 바꿔버리고 원래 데이터셋으로 만든 모델과 성능을 비교한다. 성능차이가 크면 클수록 랜덤으로 돌리지 말았어야할 중요한 별수라는 것이다. 또는 2번과 4번의 데이터 또는 바꿔서 차를 계산해도 이론상 큰 차이는 안날 것이다. 이렇게 특징값a에 대해서, 순서변경 전후의 성능을 비교하고, b,c,d,e,f에 대해서도 비교하면 permutation feature importance가 계산된다.
아래와 같이 permuation importance을 계산하면 성별이 나온다. boxplot으로 나온 이유는 random forest의 각 tree에서의 틀린정도의 분포를 그렸기 때문이다. 해석은 다음과 같다. 테스트 세트에서 생존여부를 맞추는 정도는 sex을 랜덤하게 바꿀 경우 가장 많이 성능이 떨어졌다는 것을 의미한다. 각 트리별로 고려했을 때, 평균적으로 0.25정도 성능이 떨어졌음을 의미한다.반대로 random_num, age등은 어떤 tree에서는 빼나 안빼나 구별력차이가 없었던 것을 의미하기도 한다 (box plot에 0에 맞닿아있다 (이는 랜덤으로 뽑은 데이터셋이 운이 안좋게 구별을 못한 경우일 수도 어서 0이 나왔을 수도있다.




