Motivation
- MIL은 명시적인 인스턴스라벨이 없기에 상대적으로 데이터요구량이 많은데
- NLP에서는 Transfer learning을 이용하는데 데이터 요구량이 적을 때도 많이 사용됨
- MIL aggregator의 Transfer을 해볼 순 없나?
- 이게 된다면 Aggregator도 foundation model이 생기는
Methods
- MIL 방법론 11개를 이용하여 실험
- end-to-end 튜닝
- 슬라이드 임베딩 성능을 확인(frozen feature)
- 사전학습(s->t)을 한 경우와 안 한 경우(random->t)의 비교
- 서로 다른 사전학습(s, s')을 이용한경우 둘 다 성능이 다를까?
- 같은 사전학습일 때, 서로 다른 MIL 방법론에서 성능이 다를까?
Results
1. 어떤 사전학습이 중요한가? In-domain, out-domain 둘 다에서 성능이 올라감. PC-108, PC-43보면 꽤 많이 올라감

2. MIL 아키텍처가 transfer learning에 성능에 영향을 주나? ABMIL 성능이 꽤 올라감

3. Few shot 성능 비교 (데이터가 부족할 때 도움되는가?): KNN으로 각 성능을 비교할 떄, PC-108을로 사전학습하는게 좋았고, 모든 MIL 방법론에서 좋았음. 데이터가 부족할 때 꽤 도움됨

4. 대형 MIL방법일떄도 도움되나? MIL파라미터가 적든 크든 꾸준히 도움 됨. 파라미터를 극단적으로 많이 키워도 성능저하가 크게 안일어나는거 봐서는 오버피팅이 잘 안됨

5. slide level foundatiaon model과 MIL을 전이학습시키는게 성능이 유사할 수 있을까? 사전학습시키는게 꽤 좋은 경우가 많음.
- CHIEF, GigaPath 등 슬라이드 집계방식
- PC-108은 사전학습
- Base은 초기화

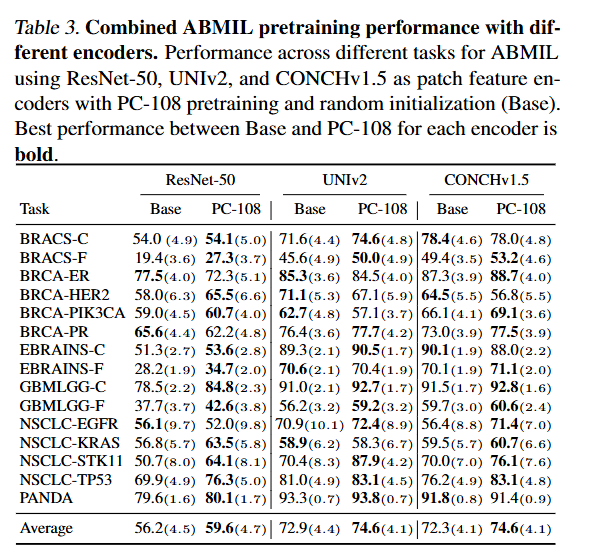
6. 패치인코더가 사전학습성능에 영향을 주나?
- Pan-cancer(PC)로 사전학습하는게 좋긴함.
반응형
'Digital pathology' 카테고리의 다른 글
| Creating an atlas of normal tissue for pruning WSI patching through anomaly detection (0) | 2025.06.23 |
|---|---|
| AI-Based Anomaly Detection for Clinical-Grade Histopathological Diagnostics (0) | 2025.06.23 |
| HistoGPT (0) | 2025.06.15 |
| Stomach histology: H.pylori (0) | 2025.04.02 |
| An Interpretable Multilabel Deep Learning Framework for theSimultaneous Assessment of Multiple Indicators (0) | 2025.03.04 |



