Motivation
- GAN을 이용한 경우, 여전히 분산이 큰 이미지는 진짜/가짜 이미지의 구분이 쉬운 편 (분산이 크다?= 이미지가 매우 heterogenous한 특성이 있다=다양한 요소의 이미지. 예, 교회(스테인드글라스,문,건축양식)
- Discriminator의 문제: 실제 데이터에 대한 학습을 간접적으로 하다보니 특징이 일반화가 안됨 (Discrimiator 입장에서는 실제 데이터 $P_{data}$을 진짜 학습하기보다는, 실제데이터 분포 $P_{data}$ 와 가짜데이터 $P_{fake}$ 사이의 차이를 구분하는데 집중하기 때문)
- Generator 이용시 Attention의 효과에 대한 의문: CNN기반으로 이미지를 학습할 때, 먼거리의 이미지끼리 중요도를 고려하는 Long-range depdency을 처리하기 어려움. Atttention을 도입하기도 했지만, StyleGAN2이후로는 Attention없이 SOTA 성능을 달성해서, 진짜 attention 이 중요한지 확인이 필요.

Methods
[Reference (real)] ─┐
├─► Siamese encoders → Reference-Attention → Real/Fake 판별
[Query (real/fake)] ┘- 대략 위와 같은 구조.
- Input: 2장의 이미지 (Reference image: 항상 real data, Query Image: real or fake)
- Encoder: 샴 인코더 (parameter sharing)
- Reference-attention: Discrimiator내에 있는 장치로, query image가 진짜인지 가짜인지 reference 기준으로 판단할 수 있게 도와줌.
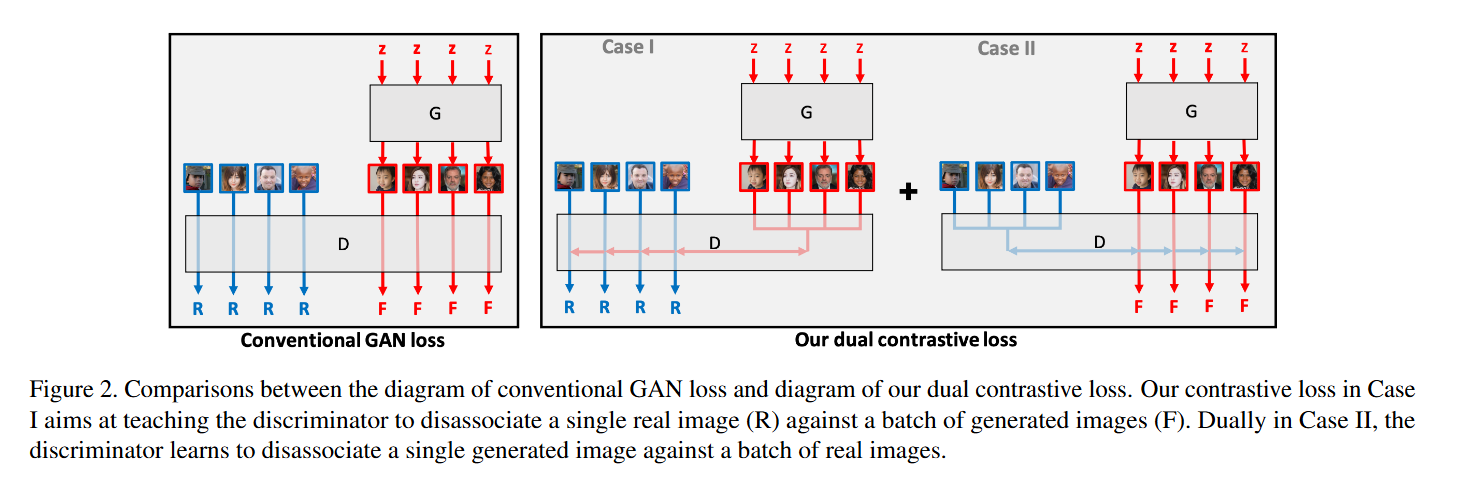
- Contrastive learning: 대조학습을 주 학습목적으로 사용. Contrastive learning을 할 때, Anchor을 아래의 2경우로 나눠 학습
- Case 1: Anchor가 실제이미지인 경우. 배치 내에서, Positive (real, 1) vs Negatives(다수)로 계산
- Case 2: Anchor가 Fake이미지인 경우, 배치 내에서, Negative (fake, 1장) vs Positives(다수)로 계
손실함수
아래와 같이, 생성된 이미지($z ~ N(0, I_{d})$) 다수에 대해서, 하나의 진짜데이터 ($x \~ p(x))$)을 구분하는 과정
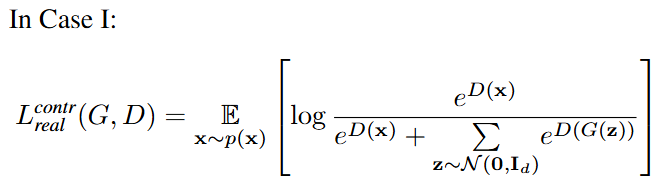
아래와 같이, 실제 이미지($x\~p(x)$) 다수에 대해서, 가짜 데이터 ($G(z)$)을 구분하는 과정
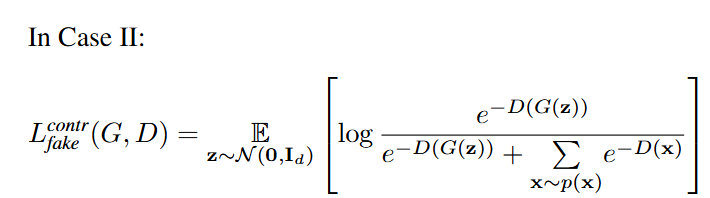
이 둘의 총합으 총 로

Reference-attention
- 참조이미지(reference image)와의 관계를 반영해서, 주이미지(primary image)의 특징이 조정된 텐서
- Input: $T \n \mathbb{R}^{h \times w \times c}$
- Query, Key, Value을 추출: 1x1 conv + leaky ReLu (형태는 유지+channel 축소)
- Q픽셀에 대해서, Key은 인접픽셀모두을 혼합. V도 인접픽셀 모두하여, 원소별곱후 합친 것을 attention weight로 하여 Value(T)와 더하여 사용(residual version).

반응형
'Data science > Computer Vision' 카테고리의 다른 글
| 이미지 흐림 측정 방법 (2) | 2024.10.14 |
|---|---|
| 극좌표계(Polar coordinates) 및 픽셀유동화 (0) | 2024.08.20 |
| [5분 컷 리뷰] Matthew's correlation coefficient loss (0) | 2024.07.25 |
| Segmentation loss (손실함수) 총정리 (3) | 2024.07.22 |
| [5분 컷 이해] DICE score의 미분 (0) | 2024.07.17 |


