import mlflow
from setting import parent_run_id
mlflow.set_tracking_uri(TRACKING_URI)
child_run_ids = list()
for run in client.search_runs(experiment_ids=[6]):
if "mlflow.parentRunId" not in run.data.tags:
continue
if run.data.tags["mlflow.parentRunId"] != parent_run_id:
continue
child_run_ids.append(run.info.run_id)
에지(엣지, edge)은 서로 다른 물체의 경계면에 나타내는 경계선을 의미합니다. 이 경계 주변이 픽셀들의 분포를 생각해보면, 명암의 급격한 변화가 있게 됩니다. 아래의 강아지 사진을 보면, 강아지의 눈을 주변으로 경계는 명암차이가 극명합니다(Figure 1). 이러한 명암차이로, 흰색강아지털과 검은색 눈동자의 경계면을 사람도 인식할 수 있습니다. 에지 검출알고리즘은 이렇듯 명암차이가 극명하게 나는 지점을 추출하기 위한, 여러 연산자(+알고리즘)을 사용하는 것이 공통적입니다.
Figure 1. 포메라니안 강아지
미분을 이용한 에지의 검출
에지의 검출은 명암변화가 급격히 일어나는 지점을 찾는 것이라고 했습니다. 수학적으로는 변화가 급격하게 일어나는 지점을 찾는 것은 미분을 이용합니다. 하지만, 디지털영상에서는 변화가 급격하게 일어나는 지점을 찾으려면 어떻게 해야할까요? 미분을 이용하고 싶지만, 아래와 같이 미분연산에서 극한을 취급할 수 없습니다. 왜냐하면, 디지털영상은 이산형이이기 때문에(=연속이 아님), 미분을 취급하기 어렵습니다. 따라서, 아래와 같이 옆 픽셀과의 차이로 계산합니다.
$f'(x)=\frac{df}{dx}=\frac{f(x+1)-f(x)}{\Delta x}=f(x+1)-f(x)$ (픽셀위치차이를 1로 고려하여)
함수 식은 위와 같고, 이를 영상에 적용려면, 필터(연산자, 커널)를 하나 정할 수 있습니다. 바로 [-1, 1]커널 입니다. 아래와 같이 f(x+1), f(x)인 박스(픽셀)에 [-1, 1] 어레이를 곱하면, 미분값을 구할 수 있습니다.
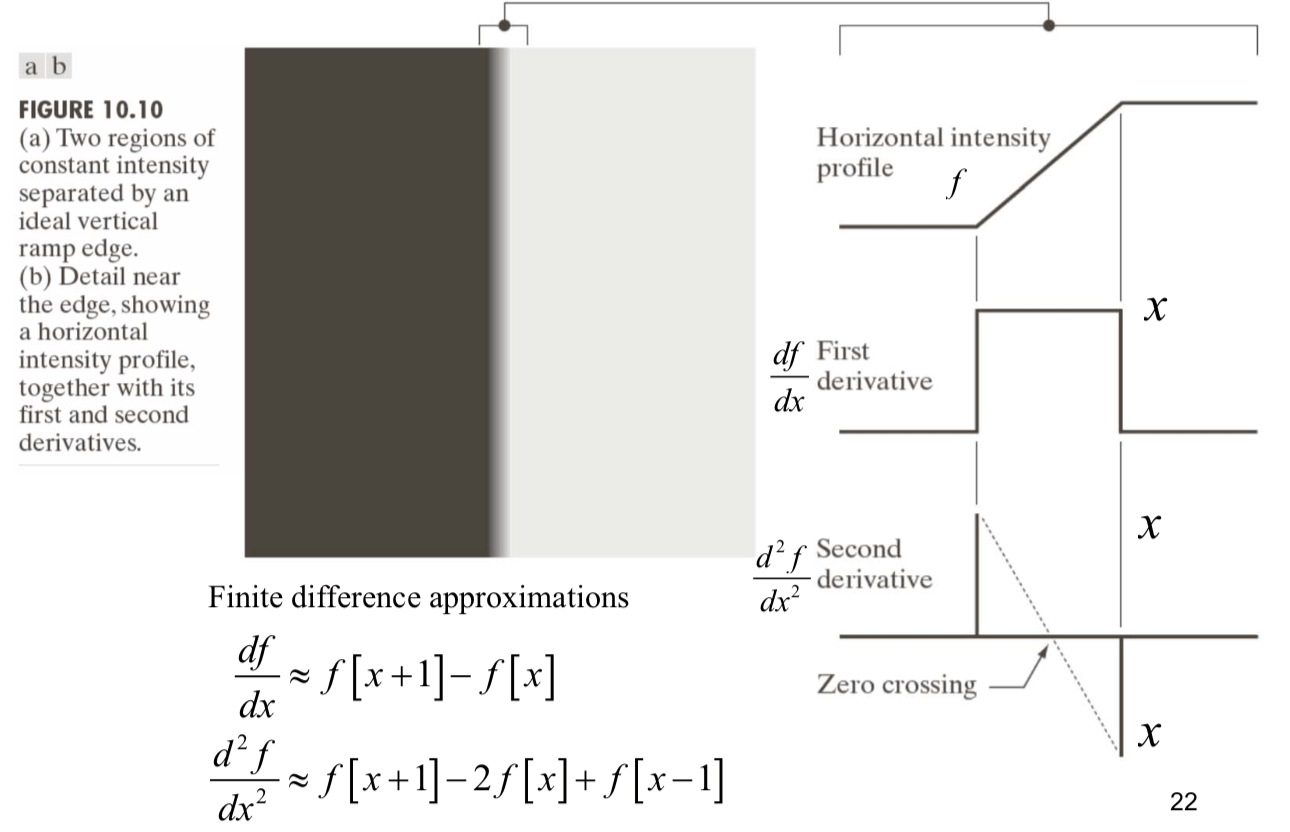
하지만, 현실세계에서는 이와 같이 경계면이 확확 바뀌지않습니다. 위의 식으로 아래의 그림(figure 3)의 좌측을 계산한다면, 엣지가 f(x+1), f(x)의 차이가 커서 구분이 잘되겠지만, 우측의 램프엣지(ramp edge)의 형태인 경우는 램프엣지 구간의 명암차이가 일정하게 나타날 것입니다. 그래서, 이 방법론으로는 한계가 있습니다.
Figure 3. 이상적인 엣지(계단형 엣지)와 램프엣지의 형태 (10.14445/22312803/IJCTT-V23P110)
하지만, 1차미분이아닌 2차미분을 이용하면 램프엣지(ramp edge)에서도 경계면을 찾을 수 있습니다. 아래의 그림의 좌측(Figure 4), 램프엣지가 있다고할 때, 이 명암의 크기는 우측상단의 그림처럼 보여질 것 입니다. 그리고 이를 1차미분하면 위의 블록이 하나 있는 것처럼 보이는 봉우리가 나타날 것입니다. 그리고, 여기서 한번 더 미분한 (2차미분) 값을 구하면, 1차미분에서 봉우리의 시작점, 출발점 사이의 가상의 선이 무조건 0을 지나게됩니다. 즉, 2차 도함수를 이용하여, 영교차(zero-crossing)하는 지점을 찾으면, 램프엣지에서도 경계선을 찾을 수 있습니다.
위의 영상은 1차원의 공간에서 명암을 기준으로 했기에, 이제 2차원으로 확장해봅니다. 단순히 1차원을 2차원으로 확장하면, x, y축에서의 미분값을 구하면됩니다. 그 식은 아래와 같습니다. 1차도함수 먼저 정의하고, 1차도함수를 2번사용하면 2차도함수를 구할 수 있습니다.
하지만, 실제로는 잡음이 있어서 위와 같이 픽셀 하나차이의로만은 노이즈가 있어, 두 픽셀 사이로 영교차 이론을 적용합니다. 그렇기에 실무적으로 쓰이는 공식은 아래와 같습니다. 이렇게 되면 실제 마스크(kernel)은 [-1, 0, 1]와 같은 커널을 적용할 수 있습니다.
현실세계에서는 필터를 적용할 때, 이미지의 픽셀이 노이즈가 많기 때문에 이를 리덕션해줄 필요가 있습니다. 가우시안 필터는 이러한 경우 흐릿하게하는 블러(blurring)에 사용되는데요. 소벨필터는 이 가우시안 필터와 x,y 축별로의 그레디언트를 혼합하여 사용하는 필터입니다. 그렇기에 상대적으로 노이즈에 덜 민감한 편입니다.
Sobel filter 및 분해
Prewitt operation: 평균필터 + x,y 미분
프레윗 연산은 소벨과 다르게, 평균으로만 스무딩필터를 적용합니다. 그 결과 아래와 같은 커널을 얻을 수 있습니다.
AWS Identity and Access Management (IAM)은 Amazon Web Services (AWS)에서 제공하는 서비스로, AWS 리소스에 대한 액세스를 관리하고 보안을 강화하는 데 사용됩니다. IAM을 사용하여 AWS 계정에 사용자, 그룹 및 역할을 생성하고, 이러한 엔터티에 대한 권한을 정의하여 AWS 리소스에 대한 액세스를 제어할 수 있습니다. 본 과정에서는 github action으로 AWS 리소스(ECR, EC2)을 제어 하기 위함입니다.
3. Github secrets 설정: 리포지토리 내, Settings-Security 내 Secrets and variable - Actions 등록
Action secrets는 GitHub Actions 워크플로우에서 사용되는 민감한 정보를 안전하게 저장하고 관리하기 위한 기능입니다. Secrets는 암호화되어 안전한 저장소에 저장되며, 워크플로우 실행 시에만 필요한 환경 변수로 사용할 수 있습니다. Action에서 사용하게되는 변수들을 repository에서 안전하게 저장하고, action에서 사용하는 yaml파일에서 접근이 가능합니다.
다음과 같이 등록이 필요합니다.
AWS_ACCESS_KEY_ID: AWS(Amazon Web Services) 계정에 액세스하는 데 사용되는 액세스 키의 ID 부분입니다. AWS API에 액세스할 때 사용
AWS_SECRET_ACCESS_KEY: AWS(Amazon Web Services) 계정에 액세스하는 데 사용되는 액세스 키의 시크릿 키 부분입니다. AWS API에 액세스할 때 사용
AWS_REGION: AWS 리소스가 위치한 지역(region)을 지정하는 변수. 참고로 ap-northeast-2=아시아 태평양(서울)입니다.
REPO_NAME: ECR 리포지토리에 접근하는 데 사용되는 계정 ID 또는 별칭입니다. ECR에 도커 이미지를 푸시하거나 불러올 때 사용
EC2_PRIVATE_KEY: AWS EC2 인스턴스에 SSH로 접속할 때 사용되는 개인 키(private key). EC2의 pem키의 내용을 그대로 copy & paste하시면 됩니다. "--benign", "--end"을 포함하여 plain text로 복붙하시면됩니다!
github actions secret이 등록된 화면
4. ECR 생성하기: dockerhub을 이용하셨다면, 같은 기능을 하는 AWS의 dockerhub라고 보셔도 무관합니다.
AWS 검색화면에서 ECR을 검색하여 다음과 같이, 리포지토리(repository)을 생성합니다. 아래와 같이 private으로 설정할 수 있습니다. 그리고, Repository name에보면, "숫자".dkr.ecr.ap-northeast-2.amazonaws.com 으로 나열되는데 "숫자"에 해당하는 부분이 aws_account_id이고, ap-northeast-2가 region입니다[1]. aws_account_id도 secret_key로 본 포스팅에서는 등록하였습니다.
1. Action yaml파일 생성: github/workflows 디렉토리에 새 워크플로우 파일을 생성합니다. 예를 들어, deploy.yml 파일을 만들 수 있습니다. 아래와 같이 "set up a workflow yourself"을 눌러 workflow(yaml파일)을 처음부터 작성할 수 있습니다.
Actions 클릭 후 화면"set up a workflow yourself" 을 클릭 후 화면
그리고, 아래와 같이 yaml파일의 초반부를 작성합니다.
name: Deploy to EC2 with ECR
on:
push:
branches:
- main # 배포할 브랜치를 선택합니다. 원하는 브랜치로 변경 가능
env:
EC2_USER: ubuntu
EC2_HOST: <EC2의 IPv4 공개IP>
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v2
AWS 자격증명: AWS 액세스 키와 시크릿 키, 그리고 지정한 AWS 리전을 사용하여 AWS 자격증명을 설정합니다.
Docker 이미지 ECR로 푸시: 이미지를 ECR로 푸시하기 위해 해당 이미지를 태깅하고, ECR에 로그인한 뒤 이미지를 푸시합니다. 위의 단계에서 만든 "my-image:latest"의 이미지를 ECR로 푸시하기위해서, ECR에 로그인하고, ECR리포지토리에 맞게 테그명을 변경합니다. 만일 ECR의 URL가 "000000000.dkr.ecr.ap-northeast-2.amazonaws.com/my-image" 였다면, 이미지도 재 태그하여 "000000000.dkr.ecr.ap-northeast-2.amazonaws.com/my-image:<버전테그>" 형식어야합니다. 즉 "/????"의 이름도 같아야합니다.
EC2 인스턴스로 SSH 접속: EC2 인스턴스에 접속하기위해서 ".pem"파일의 내용을 sercrets 변수로부터 stdout을 "key.pem"을 작성을 합니다. 이를 이용하여 ssh -i <pem파일경로> 로 접속합니다. 그리고, SSH에 접속후에 ECR로부터 이미지를 pull 받고, 이미 띄워져있는 컨테이너가있다면 중단, 삭제하고, 새로운 이미지를 컨테이너로 구동합니다. 그리고 마지막으로 pem키를 삭제합니다.
그러나 두 함수 사이에는 몇 가지 차이점이 있습니다. 데이터가 복사가 되는지 여부와, 데이터 유형이 변화되는지 여부의 차이가 있습니다.
차이점 비교
복사 여부 - np.array(): 기본적으로 배열의 복사본을 생성합니다. - np.asarray(): 배열의 복사본을 생성하지 않고, 가능한 경우에는 입력 배열의 뷰(view)를 반환합니다. 즉, 입력 배열과 반환된 배열이 메모리를 공유할 수 있습니다.
데이터 유형 변환:
- np.array(): 입력된 데이터의 유형에 따라 새로운 배열의 데이터 유형이 결정됩니다. 필요에 따라 데이터 유형을 명시적으로 지정할 수도 있습니다. - np.asarray(): 입력된 배열과 동일한 데이터 유형을 갖는 배열을 생성합니다. 따라서 입력 배열의 데이터 유형을 유지합니다.
코드 비교
간단한 예제로 두 함수의 동작을 살펴보겠습니다. 아래의 예제에서 np.array()를 사용하여 배열 arr1을 생성하고, 이를 np.asarray()로 배열 arr2를 생성합니다. 그런 다음 arr1의 첫 번째 요소를 변경하면 arr2도 동일하게 변경됩니다. 즉, np.asarray()는 입력 배열과 같은 데이터를 참조하므로 변경 사항이 반영됩니다. 즉, arr1의 0번 인덱스만 변경했음에도, np.asarray은 array을 데이터를 그대로 참조하며, 뷰를 생성하므로 arr1을 변경함에따라 arr2도 변경됩니다.
요약하자면, np.array()는 항상 복사본을 생성하며, 데이터 유형 변환을 수행할 수 있습니다. np.asarray()는 가능한 경우에는 복사본 대신 입력 배열의 뷰를 반환하며, 데이터 유형 변환은 수행하지 않고 입력 배열의 데이터 유형을 유지합니다.
GrabCut 알고리즘은 이미지 분할 알고리즘 중 하나로, 이미지에서 객체를 분리하는 기술입니다. 이 알고리즘은 Microsoft Research에서 2004년에 개발되었으며, 이미지 분할에서 높은 성능을 보입니다.
방법론
GrabCut 알고리즘은 기본적으로 그래프 컷(Graph Cut) 알고리즘을 기반으로 하며, 다음과 같은 단계로 이루어집니다.
초기화: 입력 이미지에서 전경(foreground)과 배경(background)을 구분할 수 있는 초기 마스크(mask)생성:. 예를 들어, 사용자가 수동으로 객체를 지정하거나 또는 머신러닝 알고리즘 등을 사용하여 초기 마스크를 생성할 수 있습니다. 초기 마스크에는 전경, 배경, 그리고 불확실한 영역이 있습니다. 불확실한 영역은 전경인지 배경인지 확실하지 않은 영역입니다.
가우시안 혼합 모델(Gaussian Mixture Model) 적용: 전경과 배경의 색상 분포를 추정하는 가우시안 혼합 모델(GMM)을 적용합니다. 전경과 배경은 각각 다른 GMM으로 모델링됩니다. 불확실한 영역에 대해서는 두 GMM을 혼합한 모델을 사용합니다.
에너지 함수 계산: 각 픽셀의 전경일 가능성과 배경일 가능성을 기반으로 에너지 함수를 계산합니다. 에너지 함수는 전경과 배경에 속할 가능성이 높은 픽셀에 대해서는 에너지가 작게, 그렇지 않을 경우에는 에너지가 크게 계산됩니다.
그래프 컷(Graph Cut) 수행: 그래프 컷 알고리즘을 사용하여 전경과 배경을 분리합니다. 그래프는 노드(node)와 엣지(edge)로 이루어져 있으며, 각 픽셀은 노드에 대응되고, 인접한 픽셀 간에는 엣지가 존재합니다. 엣지에는 가중치가 부여되는데, 이 가중치는 인접한 노드의 색상 및 에너지 함수를 기반으로 계산됩니다. 그래프 컷 알고리즘을 적용하여 전경과 배경을 구분합니다.
반복 전경과 배경이 충분히 분리될 때까지 단계 2에서 4를 반복
코드: Python3
1. Grabcut할 이미지를 불러옵니다.
import cv2
import numpy as np
# 입력 이미지 로드
img = cv2.imread('input_image.jpg')
2. 초기화: 초기 마스크, 전경 후경의 모델(Gaussian mixture model)에 사용되는 특징값 저장.
# 초기 마스크 생성 (전경, 배경, 불확실한 영역)
mask = np.zeros(img.shape[:2], np.uint8)
bgdModel = np.zeros((1,65), np.float64)
fgdModel = np.zeros((1,65), np.float64)
3. ROI 계산
# 전경과 배경 좌표 지정
rectangle = (365, 362, 44, 37)
# 또는 전경과 배경 지정 (마우스로)
rectangle = cv2.selectROI(img)
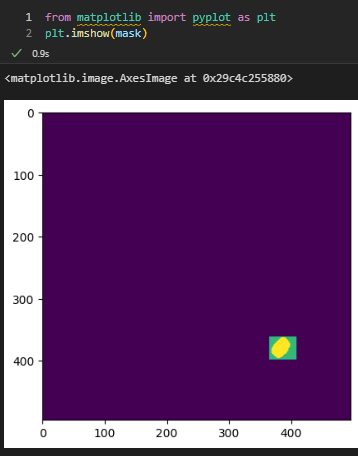
5. 결과 출력: "np.where((mask==2)|(mask==0), 0, 1)"는 NumPy의 where() 함수를 사용하여 마스크에서 전경에 해당하는 부분을 추출하는 코드입니다. mask는 GrabCut 알고리즘을 적용한 결과 생성된 마스크이며, 마스크의 값은 0, 1, 2, 3 네 가지 값으로 구성됩니다. 이 중에서 값이 0과 2는 배경을 나타내고, 값이 1과 3은 전경을 나타냅니다. 따라서, mask==2 또는 mask==0인 부분은 배경에 해당하므로 0으로, 그 외의 부분은 전경에 해당하므로 1로 변환하여 반환합니다. 이를 통해 전경 부분을 추출할 수 있습니다.
# 결과 출력
mask2 = np.where((mask==2)|(mask==0), 0, 1).astype('uint8')
result = img * mask2[:, :, np.newaxis]
cv2.imshow('Input Image', img)
cv2.imshow('GrabCut Result', result)
cv2.waitKey(0)
cv2.destroyAllWindows()
전체코드
// 마우스로 좌표측정방식
import cv2
import numpy as np
# 입력 이미지 로드
img = cv2.imread('input_image.jpg')
# 초기 마스크 생성 (전경, 배경, 불확실한 영역)
mask = np.zeros(img.shape[:2], np.uint8)
bgdModel = np.zeros((1,65), np.float64)
fgdModel = np.zeros((1,65), np.float64)
# 전경과 배경 지정 (마우스로)
rect = cv2.selectROI(img)
# GrabCut 알고리즘 적용
cv2.grabCut(img, mask, rect, bgdModel, fgdModel, 5, cv2.GC_INIT_WITH_RECT)
# 결과 출력
mask2 = np.where((mask==2)|(mask==0), 0, 1).astype('uint8')
result = img * mask2[:, :, np.newaxis]
cv2.imshow('Input Image', img)
cv2.imshow('GrabCut Result', result)
cv2.waitKey(0)
cv2.destroyAllWindows()