SimCLR에서는 Instance discrimiation이 학습목적으로 원본이미지를 서로 다른 증강방법을 이용해도, 서로 같은 임베딩이 되게끔 유도한다. CSI은 SimCLR방법과 매우 유사한데, 원본이미지를 증강한 경우만 OOD(Out Of Distribution)으로 학습하는 방법이다.
이미지 증강방법들의 집합 $S:=\{S_{0}, S_{i}, ..., S_{K-1}\}$
동일 이미지 반환: $I=S_{0}$
여러 이미지 증강방법S로부터 하나를 뽑아, 이미지 모든 이미지를 증강하고(원본반환 포함)이를 SimCLR을 돌림. 이 과정을 여러 증강방법에 대해서 반복함.
추가적인 학습 테스크로, 증강된 이미지가, 어떤 증강방법으로 이용되었는지를 분류하는 방법도 진행
최종학습 Objective은 증강에 따른 이미지를 OOD Image로 SImCLR하는 목적과 증강방법론 분류모델을 혼합하여 예측하게 됨
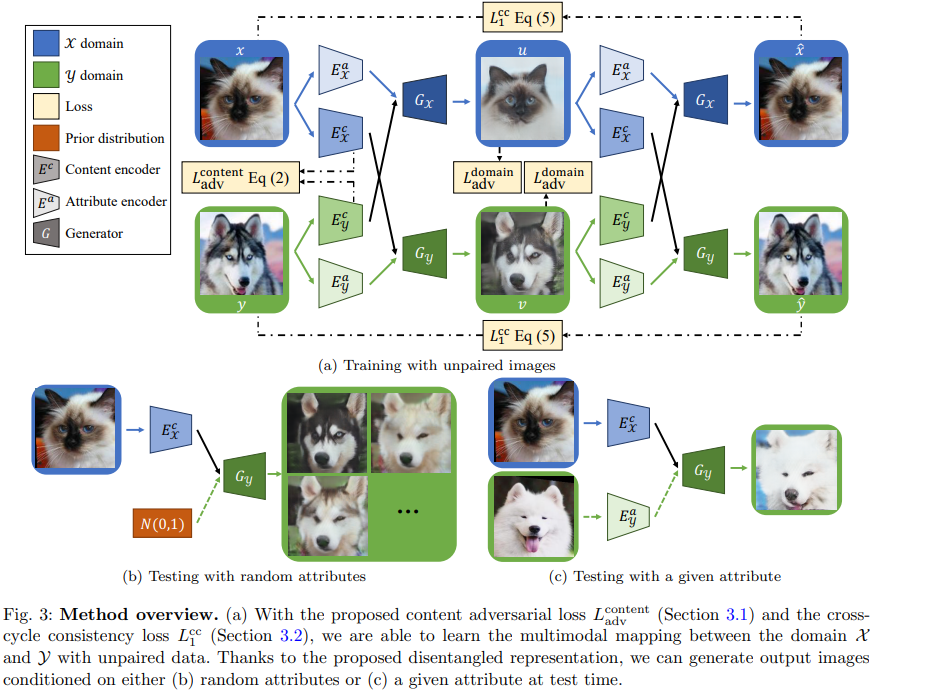
Image to image translation은 두 이미지 사이의 연관성을 학습하는 방법입니다. 보통은 1) 두 이미지의 짝을 지은 데이터가 가 구하기 어려워서 image to image을 하기 어렵고, 2) 한 이미지를 꼭 반드시 하나의 이미지에만 짝을 지을 필요가 없어 데이터 구성이 매우 어렵습니다.
위의 1), 2)의 예시인데, 이렇게 이미지를 짝을 지어야하는 경우에 이 데이터를 짝짓기도 어렵고, 짝을 짓더라도 다양한 경우가 많아서 golden standard로 짝을 지었다고 보장하기 어렵습니다.
방법론
DRIT++은 2개의 임베딩을 나눠 만들어내는데, 1) domain invariant content space, 2) domain-specific attribute space 을 나눠 만들어냅니다.
구성은 크게 3파트입니다.
컨텐츠 인코더(content encoder): domain invariant content space을 만들어내는 인코더가 하나 필요합니다.
속성 인코더(Attribute encoder): 속성 인코더도 하나 필요합니다. 속성 인코더가 만드는 임베딩 벡터는 컨텐트 임베딩 벡터와 공유하지 않습니다. 단, X 도메인, Y도메인에 쓰이는 인코더는 동일 합니다(shared).
제너레이터(Generator): 컨텐츠 인코더가 만든 벡터와, 속성인코더가 만든 벡터를 입력으로하여 이미지를 생성합니다.
판별부(Domain discrimator): 합성된 이미지와 진짜 이미지를 판별하는 모듈입니다.
- 뉴털네트워크를 이용할때, 엔트로피(entropy)가 낮은 경우를 패널티를 줘서 over-confidencence 문제를 해소를 보임.
- 2가지 패널티 방법론을 제시: 라벨스무딩, Confidence penality
- 이미지 분류, 언어모델, 번역, 등의 다양한 문제에서의 이 방법론을 적용하여 해소됨을 보임.
Figure 1. 논문에서 제시한 2가지 방법론을 사용한 경우의 MNIST 데이터에서의 model confidence 분포. 첫번째그림에서는 예측값의 분포가 0아니면 1이 었는데, 컨피던스의 정규화과정을 거치면서 무조건 0,1이기보다는 중간값을 제시하여 불확실성에 대한 수치를 반영함.
사전지식(Preliminary)
*엔트로피가 낮다= 0 또는 1로만 모델이 분류하여 예측이 이분화(dichotomy)된 것을 의미합니다. 하지만, 세상의 모든예측이 확실할수만은 없죠.
이 수식이 의미하는 것은 Loss = (negative log-likelihood) - (beta * negative entropy) 입니다. 즉, 손실값 = 오분류 오차 - (가중치 * 분포도)을 의미하는 것이죠. 추가로 beta 가 들어가 있는데, beta을 줘서 너무 강하게 한쪽으로만 에측하지 않도록 패널티을 추가하는 형식입니다.
위 식에서는 엔트로피가 타우($\tau$)보다 큰 경우만 패널티를 주는 수식으로 변경했습니다. 이렇게하는 이유는 지도학습의 경우에는 학습 초반에 빨리 파라미터가 수렴하는 것이 좋은데, 이럴려면 초반에는 패널티가 좀 적어야하고, 학습후반에 패널티를 키워야합니다.즉, 패널티를 초반에는 안주고, 후반에는 줘야합니다. 따라서, 이를 구현하기위해서 힌지로스(=>max(0, tau - 함수값))을 써서 다음과 같이 구현했습니다.
- 방법론 2. 라벨 스무딩(Label smoothing)
사전 라벨의 분포를 사용하는 방법입니다. 사전 라벨이 균일하다면, 예측된 라벨의 분포도 균일하길 바라바면서 KL Divergence로 두 분포의 거리를 패널티로 주는 방법입니다.
일반적으로 딥러닝이 텍스트나, 이미지 데이터셋에서의 고성능을 보이지만, 정형데이터(Tabular dataset)에서 성능이 우월한지는 잘 밝혀지지 않았습니다. 오히려 안좋은 경우도 있습니다. 이 논문은 실제로 그런지 딥러닝과 트리기반모델(RF / XGBoost)을 비교했고, 뉴럴넷(NN)이 성능이 그렇지 좋지 못하였다는 실험결과를 보여줍니다. 그리고, 이 이유에 대해서는 아래와 같이 설명합니다.
정보량이 별로 없는 특징값에 대해서도 강건하다는 것(robust)
데이터 방향(orientation을 유지해서) 학습이 잘 되도록 한다는 것
비정형적인 함수도 쉽게 학습이 된다는 것입니다(딱딱 끊기는 함수도 학습이 잘됨).
Preliminary
Inductive bias: 훈련되어지지 않은 입력에 출력을 예측하는 것. 학습을 한적이 없지만, 그간 보아왔던(학습했던)데이터를 이용하여(=귀납적 추론), 알고리즘이 예측하도록하는 가정입니다. 예를 들어, CNN은 Locality & Translational invariance, RNN은 Sequntial & temporal invariant, GNN은 permutational invariant 입니다.
도입
트리기반 모델은 대체로, 인공신경망보다 정형데이터에서 많이 성능의 우월함을 보였습니다. 아쉽지만, 이렇게 좋은 트리 기반모델은 미분이 불가능하기 때문에, 딥러닝과 혼합하여 사용하기 어렵습니다. 이 논문은 왜 트리기반 모델이 정형데이터에서 딥러닝 보다 우월한지를 보여주는 논문입니다.
방법론: 45개의 데이터셋에서, 딥러닝모델과 Tree기반 모델의 비교
OpenML에서 총 45개의 데이터셋을 만들었습니다. 이 데이터셋은 다음과 같은 선정기준으로 뽑혔습니다.
Heterogenous columns: 컬럼이 매우 이질적일 것.
Not high demiensional: 컬럼수가 행수에 비해서 1/10미만일것
Undocumented dataset: 너무 정보가 없는 경우는 제외.
IID: 이전 데이터가 직전데이터의 예측에 연관된 경우(예, 타임시리즈 제외)
Realworld data: 합성데이터 아닐 것 6. Not too small: 너무 적지 않을 것 (특징값 <4 , 행수 <3,000)
벤치마크에서 분류든, 예측이든 트리기반모델이 더 고성능을 보였습니다. (Figure 1, Figure 2). Figure 1은 연속데이터만 있는 경우, Figure 2은 연속+카테고리데이터 둘다 있는 데이터입니다. 두 종류의 여러 데이터에서도 트리기반이 더 우수했습니다.
Dicussion:왜 Tree 모델이 Tabular데이터에서는 더좋은가? 3가지 이유
Discussion왜 더 좋을까? 크게 3가지 이유 때문에 좋다고 주장합니다.
뉴럴넷은 smooth solution 을 inductive bias을 갖기 때문에: 연구자들이 훈련데이터를 가우시안 커널을 이용하여 조금더 soothing하게 펼친 데이터를 만들고, 트리기반모델과 신경망모델을 비교했습니다. 신경망모델은 성능이 적게 떨어지는 반면, 트리기반모델은 급격히 떨어집니다 (Figure3). 이는 트리 기반모델이 예측시에 비선형 if, else등으로 자잘하게 쪼개는 반면, 뉴럴넷은 부드럽게 예측구분을 나눠주기 때문이라는 근거의 결과가 됩니다 (Figure 20).
인공신경망은 별로 정보량없는 데이터에대해 영향을 많이 받음: 정형데이터는 꽤 정보량없는 특징값이 많습니다. 랜덤포레트를 이용하여, Feature importance가 작은순으로 특징값을 제외시켜나가면서, GBT(Gradient boosting Tree)을 학습시켜나갔더니, 특징값이 꽤 많이 없어질때까지 좋은 성능을 냅니다 (Figure 4).인공신경망에서도 비슷한 패턴이보이긴합니다 (Figure 5). 하지만, 불필요한 정보를 특징값으로 넣는 비율이 클수록, 트리기반 모델보다 급격히 성능이 하락합니다 (Figure 6)
인공신경망은 데이터를 rotation해도 비슷한 성능을 낸다고 합니다. [Andre Y. Ng, 2004]. 딥러닝자체가 rotationally invariant하다는 것인데, 데이터를 회전시켜도 학습이 잘된다는 말입니다. 즉, 메트릭스 중에 행 또는 열을 일부를 제거한다고해도 , 딥러닝알고리즘은 rotation에 맞게 학습한다는것입니다. Tabular 데이터는 실제로 돌리면 다른 데이터인데, 인공신경망은 학습을 이렇게 해왔기 때문에, 성능이 감소한다는 것입니다. 실제로 데이터를 돌려서 학습시켜도 다른 모델에 비해서 성능이 하락하지 않습니다 (Figure 6).
테스트 이미지(좌측 Label 7)을 예측하는데 있어, 가장 안좋은 영향력(harmful)한 데이터를 influence function을 이용하여 찾은 결과
요약
흔히, 딥러닝모델을 예측치에 대한 설명이 되지않아 블랙박스 모델이라고 한다. Influnence function은 특정 테스트 데이터포인트를 예측하는데 도움을 주었던, 도움을 주지 않았던 훈련데이터를 정량적으로 측정할 수 있는 방법이다. 즉, 훈련데이터에서 특정데이터가 빠진 경우, 테스트데이터를 예측하는데 어느정도 영향이 있었는지를 평가한다. 이를 쉽게 측정할 수 있는 방법은 모델에서 특정 데이터를 하나 뺴고, 다시 훈련(Re-training)하면 된다. 하지만 딥러닝 학습에는 너무 많은 자원이 소모되므로, 훈련후에 이를 influence function으로 추정하는 방법을 저자들은 고안을 했다.
Influence function 계산을 위한 가정
훈련데이터에 대한 정의를 다음과 같이 한다. 예를 들어, 이미지와 같이 입력값을 $z$라고 한다.
훈련데이터 포인트(개별 하나하나의 데이터)를 $z_{n}$라고 한다.
이 훈련 데이터 포인트에 개별 관측치는 입력값 x와 라벨y로 이루어져 다음과 같이 표기한다 $z_{i}=(x_{i}, y_{i})$
그리고, 모델의 학습된 파라미터를 $\theta$라고 한다.
주어진 파라미터한에서, 데이터포인트 z를 주었을 때의 loss 값을 $L(z,\theta)$ 라고한다.
학습과정을 통해 얻어진 파라미터가 위의 empirical loss을 가장 줄일 수 있게 학습된 파라미터를 $\hat{\theta}=argmin_{\theta\in\Theta}1/n\sum_{i=1}^{n}L(z_{i}\theta)$
Influence function 의 종류
Influence functiond은 training point가 모델의 결과에 어떤 영향을 주었는지 이해하기위해서 3가지 방법론을 고안했다. 1. 해당 훈련데이터포인트가 없으면, 모델의 결과가 어떻게 변화하냐? (=가중치가 어떻게 바뀌어서 결과까지 바뀌게 되나?) = 이 방법론은 loss가 얼마나 변화하냐로도 확인할 수 있다. 연구에서는 이를 up-weighing 또는, up,params이라는 표현으로 쓴다. up-weighting이라는 표현을 쓰는 이유는 특정 훈련데이터가 매우작은 $\epsilon$ 만큼 가중치를 둬서 계산된다고하면, 이 $epsilon$을 0으로 고려해서 계산하기 때문이다. 또는 이를 loss에 적용하면 "up,loss"라는 표현으로 기술한다. 2. 해당 훈련데이터포인트가 변경되면(perturnbing), 모델의 결과가 어떻게 변경되나?
Influence function 의 계산(up,loss)
아래의 계산식에서 좌측($I_{up,loss}(z,z_{test})$)은 예측값 $z_{test}$을 예측하는데있어, 특정 훈련데이터포인트 $z$가 얼마나 영향을 주었나(=loss을 얼마나 변화시켰나)를 의미한다. 마지막줄의 각 계산에 들어가는 원소는 다음 의미를 갖는다.
$-\nabla_{\theta}L(z_{test},\hat{\theta})^{T}$: 특정 테스트 z포인트를 넣었을 때, 나오는 loss을 학습파라미터로 미분한 값이다. 즉
$\nabla_{\theta}L(z,\hat{\theta})^{T}$: 특정 훈련데이터포인트 z를 넣었을 때, 나오는 loss을 학습파라미터로 미분한 값이다.
위의 세 값을 다 계산하여 곱해주기만하면 특정 훈련데이터z가 테스트데이트를 예측하는데 로스를 얼마나 변화시켰는지 파악할 수 있다.
여기서 문제는 해시안 메트릭스($H_{\hat{\theta}}^{-1}$)를 계산하는 것이 매우 오래걸린다는 것이다. 따라서 저자들은 아래와 같이 추정방법으로 해시안메트릭스의 역행열을 구한다.
Influence function 계산의 어려움(비용)
Influence function 계산이 어려운 부분(계산비용이 큰 이유) 2부분 때문이다.
해시안 메트릭스의 역행렬을 구해야함: 해시안 메트릭스는 각 행렬에 파라미터의 개수가 p개라고 하면, $O(np^{2}+p^{3})$의 계산량이 든다는 것이다.
훈련 데이터 포인트에 대해서 모든 데이터포인트를 다 찾아야한다는 것. 예측에 도움이 안되는 데이터포인트를 찾으려면 훈련데이터가 n개면 n개의 데이터포인트를 찾아야한다.
다행이도 첫 번째 문제인 해시안 메트릭스이 역행렬을 그하는 것은 잘 연구가 되어있어서 해결할 수 있다. 명시적으로 해시안의 역행렬을 구하는것 대신에 해시안 역행렬과 손실값을 곱한 Heissan-vector product(HPV) 을 구하는 것이다
Inversed hessian matrix 구하기(HPV구하기, 중요)
조금더 구체적으로는 저자들은 해시안메트릭스의 역행열을 구하기보다는, 해시안메트릭스의 역행렬과 loss에 해당하는 vector($\nabla_{\theta}L(z_{test},\hat{\theta})^{T}$)을 한번에 구하는 방법을 소개한다. 이는 책 또는 github코드에서 주로 Inversed hessian vector product (inversed HVP)라고 불린다.
이를 구하는 2가지 방법이 있다.
Conjugate gradient (CG)
Stocahstic estimtation
저자들은 주로 Stocahstic estimation 방법으로 이를 해결하려고 한다.
다음의 서술은 위의 HVP을 구하는 방법에 관한 것이다.
훈련 데이터 포인트 전체 n개에서 매번 t개만을 샘플링 한다.
HVP의 초기값은 v을 이용한다 (이 때, v은 $\nabla_{\theta}L(z_{test}, \hat{\theta})^{T}$을 사용한다. 테스트세트에 대한 로스값의 gradient이다.)
$\tilde{H_{j}}^{-1}v=v+(I-\nabla_{\theta}^{2}L(z_{s_{j}, \hat{\theta}})\tilde{H}_{j-1}^{-1}v$ 을 계속한다.
위의 과정(1-3)을 반복한다.
위와 과정을 충분히 반복하고, t을 충분히 크게 뽑는 경우 HVP값이 안정화되고 수렴된다고 한다. 이 방법이 CG방법보다 빠르다고 언급이 되어있다.
하이라이트 결과
Leave one out 방법과 유사하게 Influence function이 loss값의 변화를 추정한다.
개인적으로 아래의 Figure 2가 제일 중요해보인다. 훈련데이터를 하나 뻈을때(leave-one-out)의 방법과 Inlfuence function으로 예측한 예측값이 거의 정확하다면 선형을 이룰것이다. 아래의 그림은 이를 뒷받침하는 결과로 사용된다.
손실함수를 미분할 수 없는 경우도, 손실함수를 대략적으로 추정(Smooth approximation) 한 경우 추정할 수 있다.
아래의 결과는 Linear SVM을 이용하여 예측한 loss의 값과, 실제 retraining한 경우의 예측값을 보여주고 있다. Linear SVM 자체에서는 Hinge 값이 쓰이는데 (ReLU와 유사하게) 미분이 불가능하다. 따라서, 저자들은 0에서 미분불가능할 때 smooth하게 변경하기위해서 아래와 같이 smooth hinge라는 것을 만들어서 어느정도 추정한 값을 쓰고 있다($smooth ~hinge(s,t)=tlog(1+exp((1-s)/t)$). 즉 이 함수는 t가 0이되면 0이될수록 미분이 불가능한 hinge loss와 동일해진다. 이렇게 적용했을 때 결과가 (b)와 같다. 미분불가능한 함수를 미분 가능하게 조금 수정한다면, (b) 와 같이 t=0.001인 경우, t=0.1인 경우와 같이 어느정도 influence function이 데이터를 빼고 재학습한 것과 같이 추정이 가능하다는 것이다)
Influence function의 유즈케이스
아래는 influence function을 언제 쓰는지에 관한 것이다.
1. 모델이 어떤 방식으로 행동하는지를 알 수 있다.: 아래의 그림 (Figure 4)은 SVM과 Inception(CNN기반)에서의 물고기 vs 개의 분류문제이다. 이 Figure 은 여러가지를 우리에게 알려준다.
우리의 직관은 "SVM은 딱히 이미지의 위상정보을 이용하지 않으니, 이미지의 거리(L2 dist)가 클수록 분류에 도움이 안될 것"으로 생각할 수 있다. Figure 4을보면 x축이 Euclidean dist인데, 400이상인경우 influcen function의 크기가 0에 가까워지는 것을 볼 수 있다.
녹색의 데이터포인트는 물고기의 학습데이터이다. 물고기를 예측하는데 있어, 물고기의 이미지만 도움을 주는 것으로 파악할 수 있다.
반대로, Inception 은 딱히 위상정보가 아니어도, 이미지의 외형(contour)을 잘 학습하기 때문에, 거의 모든 이미지가 분류에 영향을 주는 것을 알 수 있다. 즉 물고기의 예측하는데 있어서, 일부 강아지 이미지가 도움을 줄 수 있다는 것이다.
RandomForest 의 Feature importance은 여러가지가 있을 수 있지만 크게는 대표적으로 1) 불순도 기반 방식(Impurity based): tree을 나눌 때, 쓰이는 특징값으로 나눴을 때, 클레스가 잘 나뉘는 가 얼마나 변화하는지 측정하는 방식. 불순도의 변화가 크면 클수록 트리를 잘 나눴다는 것을 의미중요한 특징 값이라는 것,2) 순열 기반 방식(Permutation based): 각 특징값을 데이터 포인터에 대해서 랜덤하게 순서를 바꿔서, 정확도가 떨어지는지 확인하는 방식. 정확도가 크게 떨어질 수록 중요한 특징값임을 가정하는 방식이 있다.
선행
랜덤포레스트는 이 포스팅에서 깊게 다루지는 않지만, 트리구조를 만들 때, 배깅(bagging) 중복을 포함해서 임의로 데이터를 N개씩 뽑고, Feature bagging (속성을 뽑을 때도 랜덤하게 K)만큼 뽑아서 각각의 트리를 만든다. 그렇게 만들어진 약한 분류기(Tree)을 여러개 만들고 분류모델이면 Voting하여 얻은 값을 반환한다.
이 방식은 Gini importance라고도 불리고, MDI라고도 불리는 방식이다. 의미하는 것은 모든 랜덤포레스트의 각각의 트리에서 해당 특징값으로 트리를 나눌 때, 감소한 불순도의 평균을 의미한다(For each feature we can collect how on average it decreases the impurity. The average over all trees in the forest is the measure of the feature importance[1]).
Gini impurity은 아래와같이 계산한다 (주의: Gini coefficient와 다른 내용이다).
$Gini impurity = 1 - Gini$
$Gini = p_{1}^{2}+p_{2}^{2}+...+p_{n}^{2}$
n은 데이터의 각 클레스를 의미한다. 가령 아래와 같이 주황색 데이터와, 파란색데이터를 구분하는 문제라면 n은 2가된다. 노드를 나누기전을 부모노드라고하면, 부모노드에서의 Gini은 파란색공이 5개중에 3개, 노란색이 5개중에 2개이므로 $Gini=(3/5)^{2}+(2/5)^{2}$가 된다. 따라서, Gini impurity은 $Gini impurity=1-(3/5)^{2}+(2/5)^{2}$이다. 그리고 나눈 후를보면, 좌측은 $Gini imputiry = 1- ((2/3)^{2}+(1/3)^{2}$. 우측은 $Gini imputiry = 1-((1/2)^{2}+(1/2)^{2})$ 이다. Gini impurity의 변화량이 얼마나 변화했는지를 파악하는 것이기 때문에, 다음과 같이 부모의 impurity - (자식노드의 imputiry의합)과 같이 계산한다.
위의 계산에서 중요한 것을 빠뜨렸는데 특징값 A에 대해서 위와 같은 과정을 진행했다고하면, 모든 노드 중에서 A을 이용한 분기에를 모든 트리에서 찾은다음에 평균낸 값이 Gini importance이다. 혹은, 어떤 방식에서는 나누려는 노드의 가중치를 곱해서 많이 나눴던 노드에서는 더 가중치를 주기도 한다.
Gini importance 예시
아래의 그림을 보면 feature importances (MDI)라는 것이 표시되어있다. 이는 위의 과정(Gini importance)을 이용해서 각 노드를 나눴을때 불순도가 크게 변화하는 정도의 평균을 계산했다는 의미이다. (이 데이터셋은 타이타닛 데이터셋). 생존자와 사망자를 구분할 때, sex을 이용해서 구분했을 때, sex을 안썼을 때보다 평균적으로 더 트리구조가 깔끔하게 나뉘어져나갔다는 것을 의미한다.
Permutational importance / Mean Decrease in Accuracy (MDA)
Permutation importance은 트리를 만들때 사용되지 않았던 데이터들 OOB(Out of bagging, 랜덤포레스트의 각 트리를 만들 때, 랜덤으로 N개의 데이터를 중복을 포함하여 뽑는데, 그 때 사용되지 않았던 데이터들)을 이용하여, OOB인 데이터들에 대해서 해당 특징값을 랜덤하게 섞은후에 예측력을 비교한다.
아래와 같이 a,b,c,d,e,의 특징값을 가진 1,2,3,4,5번 데이터가 있다고하자. 모델을 빌딩할 때, 랜덤으로 뽑은 데이터가 1,3,5였고, 안타깝게 2,4번은 중복을 포함혀어 뽑았지만 뽑히지 않았던 데이터라고 하자.
OOB인 데이터포인트 2,4가 있고, a,b,c,d,e 특징값이 있는 데이터의 예시
이 때, 특징값 a에 대해서 1,2,3,4,5번의 a특징값의 순서를 랜덤하게 바꿔버리고 원래 데이터셋으로 만든 모델과 성능을 비교한다. 성능차이가 크면 클수록 랜덤으로 돌리지 말았어야할 중요한 별수라는 것이다. 또는 2번과 4번의 데이터 또는 바꿔서 차를 계산해도 이론상 큰 차이는 안날 것이다. 이렇게 특징값a에 대해서, 순서변경 전후의 성능을 비교하고, b,c,d,e,f에 대해서도 비교하면 permutation feature importance가 계산된다.
아래와 같이 permuation importance을 계산하면 성별이 나온다. boxplot으로 나온 이유는 random forest의 각 tree에서의 틀린정도의 분포를 그렸기 때문이다. 해석은 다음과 같다. 테스트 세트에서 생존여부를 맞추는 정도는 sex을 랜덤하게 바꿀 경우 가장 많이 성능이 떨어졌다는 것을 의미한다. 각 트리별로 고려했을 때, 평균적으로 0.25정도 성능이 떨어졌음을 의미한다.반대로 random_num, age등은 어떤 tree에서는 빼나 안빼나 구별력차이가 없었던 것을 의미하기도 한다 (box plot에 0에 맞닿아있다 (이는 랜덤으로 뽑은 데이터셋이 운이 안좋게 구별을 못한 경우일 수도 어서 0이 나왔을 수도있다.