ICML 2023
Motivation
- SSL의 대부분(SimCLR)은 라벨없이 학습하고, 학습이 잘되었는지 아닌지를, 라벨/튜닝(라벨)에 의존했음
- 라벨을 이용해서, Linear probing으로 확인하는 작업을 주로 했고, 라벨없는 경우 확인하기 어려움
- 라벨없이도 표현의 품질을 가늠하고, 튜닝이 필요없는 지표를 제안
- "임베딩의 유효랭크"가 다운스트림 테스크에 영향
- 랭크(Rank, 계): 서로 독립인 축의 방향 (=SVD의 0이 아닌 특이값의 계수)
방법론
- 용어정리: Representation (인코더의 출력), 프로젝터(MLP). 프로젝터의 출력이 임베딩(embeddings)
- 입력: 데이터셋에서 임베딩 행렬 $Z \in \mathbb{R} ^{N \times K}$ (25,600개도 OK)
- Z의 특이값 계산 $\sigma(Z) = [\sigma_{1}, ..., \sigma_{m}]$.
- 특이값의 정규화: $p_{k} = \frac{\sigma_{k}(Z)}{||\sigma(Z)||_{1} + \epsilon}$
- Shannon entropy을 이용해서 지수형으로 계산: $RankMe(Z) = exp(-\sum_{k=1}^{m}(p_{k}logp_{k}))$
값의 범위가 1~K로, 값이 클수록 랭크가 높을수록 유요한 축(axis)이 고르게 존재한다는거니까 특징이 풍부하게 추출됨을 의미. 즉. 화이트닝(각 축이 상관이 없오, 분산이 1로 같아지는 것) $p_{k}$들이 균등할수록 엔트로피가 커져서 RankMe가 커지고, 좋은 특징추출기임을 보임
주요결과
- RankMe 수치가 높을수록, Top1정확도가 증가하는 추세. 일부 풀랭크에서는 떨어지는 경우도 있음.
- Oracle: ImageNet 검증라벨로 선형분류기를 학습해서 성능 제일 좋은 모델을 고른 것.

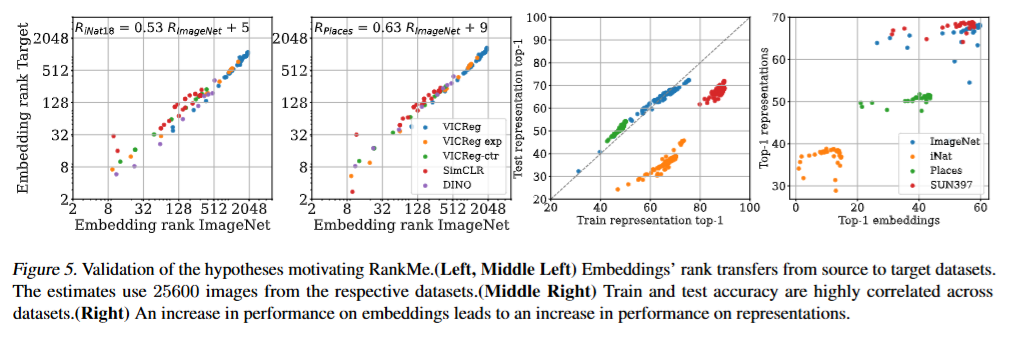
- 소스데이터셋에의 랭크가 커질수록, 타깃데이터의 랭크도 같이커지고, Test representation top1도 커짐
반응형



