Motivation
- Image-test dataset의 규모가 너무 적음: 웹사이트, 책에서 수집된데이터로 스케일을 키우는건 한정적.
- Image quality:압축하는 과정 때문에 이미지 퀄리티가 저하.
- image-text 의 퀄리티: text에 의미없는 정보 꽤 있음.
데이터 구성
큰 구성은 1)Agent Model 준비과 2) 데이터구성 파이프라인으로 나뉨
Agent model생성하기: 3개의 Agent을 생
- PathGen-CLIP-L: 문제점(병리트고하된 모델이 아님)
- PathCAP, Quilt-1M, OpenPath 데이터를 합쳐서 700K의 이미지의 데이터셋을 구성
- CLIP을 이용해서 병리에 특화된 CLIP모델을 생성.
- Description LLM Agent: 기존문제점(기존 캡셔닝은 너무 단순한 수준) -> 방법: GPT-4V에 이미지와 캡션을 전달하여, 원본 캡션을 더 정확하게 표현할 수 있도록 함. (LLaVA은 isntruction-following 성질이라 설명을 잘만듬)
- Dataset: Image-caption 10,000장을 얻음(PathCap, OpenPath, Quilt-1M)
- Caption 증강: 1.의 데이터셋을 이용해서 GPT4V에 넣어 증강 + 명세.
- LLaVA-v1.5-13B모델의 visual encoder을 PathGen-CLIP-L-init으로 교체
- Revised LLM Agent:문제점(다지선다, QA은 잘하는데 self-correction은 안됨)
- 데이터생성: Description LLM Agent가 설명을 생성 -> GPT4을이용해서 인위적인 오류 생성
- Revised LLM Agent 훈련: 입력:오류+오류카테고리, 출력: 오류교정 문
- Summarize Agent: 문제점(token 77개까지만 CLIP에서 받음)
- 데이터생성: GPT4에 description을 생성해서 요약해달라고함. (유료여서 그랬을듯..)
- Llama-2: 학습
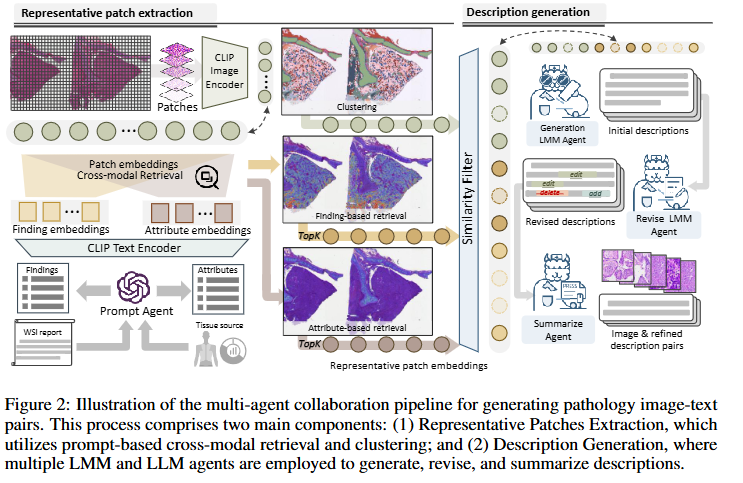
Dataset 구성하기
- 이미지: 7300 WSI TCGA을 이용.
- 텍스트: TCGA의 레포트를 GPT-4을 이용해서 diagnostic findings으로 정재
- Step1 (대표 패치 추출): WSI의 패치-레포트의 쌍으로 상위유사도 64개 생성(보고서기반(report based prompt) + K-means. 프롬프트기반은 병리적변화가 심한부분 + 정상패치 놓칠수잇음. 클러스터마다 균등하게 뽑음 (256개) => 최종 대표 패치: Step1 + step2을 합집합하여 사용
- Step 2 (유사 패치 필터링): Visual encoder (PathGent-CLIP init)으로 유사도 제거 (코사인유사도)
- Step 3 (설명생성): 패치마다 DescriptionLLM을 이용
- Step 4 (교정): 잘못된 생성문을 Revise LLM을 이용
- Step 5(설명요약): 설명이 너무 기니까, CLIP을 사용하기위해 (token77개이하)로 유지
결과



반응형
'Digital pathology' 카테고리의 다른 글
| Controllable Latent Space Augmentation for Digital Pathology (0) | 2025.09.16 |
|---|---|
| ReMix: A General and EfficientFramework for Multiple InstanceLearning Based Whole Slide ImageClassification (0) | 2025.09.04 |
| Yottixel, SISH, RCCNet (3) | 2025.07.23 |
| Similar image search for histopathology: SMILY (1) | 2025.07.21 |
| Cellpose: a generalist algorithm for cellular segmentation (1) | 2025.06.25 |



