요약
Motivation
1. 염색정규화(Stain normalization)은 타깃(target image, 또는 reference image)라고 불리는 이미지를 정하고, 이 타깃이미지에 맞춰서 소스이미지의 염색톤을 변화하는 것을 의미합니다.
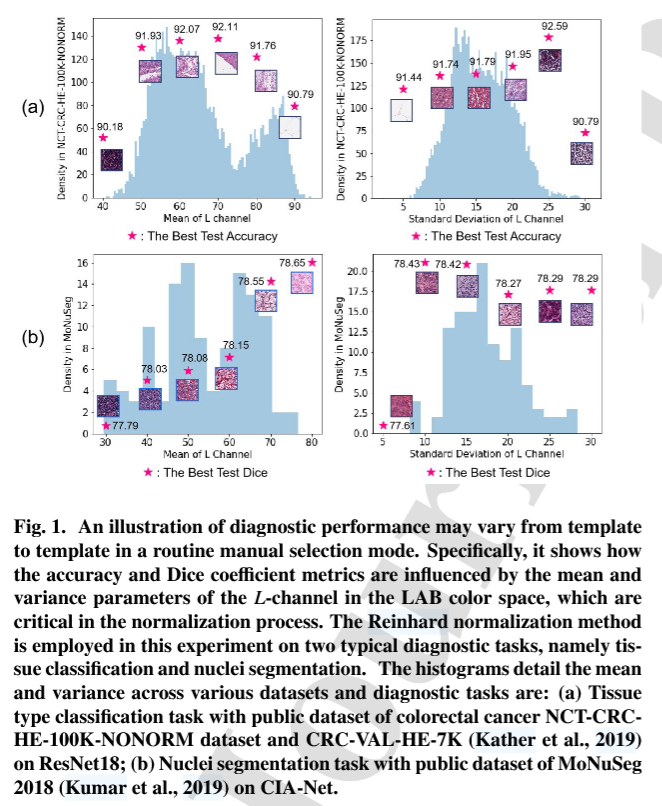
2. 그러나, 염색정규화에서 이런 타깃이미지를 선정하는 과정이 매우 작위적이고(=관찰자마다 다르며), 타깃이미지를 어떤 것을 고르냐에 따라 인공지능 모델의 성능이 크게 차이가 납니다(아래 Fig1은 어떤 이미지를 고르냐에따라서 성능이 크게 좌우된다는 예시를 표하기위한 그림입니다).
Method: 염색정규화과정에 필요한 trainable parameters을 인공지능 모델에 포함하여 학습
저자들은 데이터로부터 염색정규화에 필요한 파라미터를 모델에 추가합니다. 이 레이어명은 "LStrainNorm"이라고 합니다.
방법은 크게 "입력이미지 전달" -> "각 색공간에서 정규화" -> "다시 RGB로 변경" -> "집계" 입니다.
1. 입력이미지는 RGB 색상에 있는 이미지입니다. $\mathbf{x} \in \mathbb{R}^{H \times H \times 3}$
2. 색 공간에서 정규화
2.1. 색공간에서 정규화하기위해서, 임의의 색공간 $s$로 변환합니다. 논문내에서는 $\mathbf{x}'^{s} = Transform(\mathbf{x};s)$로 표기합니다.
2.2. 채널별로 정규화를 진행합니다. $\hat{x}'_{ijk} = \gamma _{k} \frac{x'_{ijk} - \mu_{k}}{\sigma_{k} + \epsilon} + \beta_{k}$
- 여기서 $\mu_{k}$은 채널별로 이미지의 평균 픽셀값을 의미합니다. 또한, $\sigma_{k}$도 픽셀의 표준편차값을 의미합니다.
- $\gamma_{k}, \beta_{k}$은 trainable parameter로 스케일(scale)과 값증감(shift)에 활용됩니다. Batch normalization에도 활용되는 값입니다.
- 이전의 염색정규화과정에서는 이런 값들은 타깃이미지를 정함으로써, 결정되는데 이 논문에서는 이 수치들이 학습가능하게됩니다.
- 단 완전히 학습값에만 의존하지 않도록 $\gamma_{k} = \gamma_{k}^{int} + \Delta \gamma_{k}^{opt}$로 분리합니다.
- 그리고, $ \Delta \gamma_{k}^{opt} $학습하여 조절할수 있도록 합니다. beta에 대해서도 동일히 작업합니다.
2.3. 스케일링을 합니다. 정규화한 값이 너무 크거나 작거나하지않도록 [0, 1] 사이의 값으로 clip합니다. (식 9)
3. 어텐션을 이용한 컬러 공강 앙상블
- 위의 과정을 컬러스페이스 s에 대해서 다양하게 진행합니다. 즉, 컬러공간(HSV, CEILAB 등)에 대해서 수행해서 Attention값을 구합니다.
- Attention 값은 $Att(Q^{s}, K^{s}, V^{s})= softmax(\frac{Q^{s} \cdot (K^{s})^{T}}{d})\cdot V^{s}$ 로 계산합니다.
- Self-attention을 계산할 때 사용되는 Q, K, V은 1x1 kernel을 2D conv하여 구합니다. 즉, 1x1으로 하니 채널축으로만 선형결합한 값입니다.
- $Q^{s} = Flatten \circ MaxPool \circ Conv_{1}^{s}(\hat{ \mathbb{x}^{s}})$ 으로 컬러공간별로 convolution을 따로둡니다. (식11~12)
- $K^{s} = Flatten \circ MaxPool \circ Conv_{2}^{s}(\hat{ \mathbb{x}^{s}})$: 마찬가지로 K도 컬러공간별로 convolution branch을 따로둡니다. 이 QK을 계산하면 patch내의 픽셀들사이의 global context을 얻는것입니다.
- $V^{s} = Flatten \circ MaxPool(\hat{ \mathbb{x}^{s}})$: Value은 풀링만하여 넣습니다. 위에서 계산한 global context와 곱합니다. 결과적으로 $(B, C, hw) \cdot (B, hw, hw)$을 하는모양입니다.
- 이 결과를 원본 (B, C, W, H)와 곱해주기위해서 unflatten(B, C, w, h) 후에 업샘플하여 사이즈를 맞춰주고 (B, C, W, H) 원소별 곱하여 정규화된 이미지를 구합니다.
- 이 이미지를 LAB, HSV 등 여러 이미지에 대해서 가중합을 하여 최종 정규화된 이미지를 획득합니다. 식(14)




