요약
Multi-task learning은 연관된 복수의 테스크를 하나의 모델에 학습시키면서, 추가적으로 성능이 올라갈 수 있어 종종 사용됩니다. 이 논문에서는 Multi-task learning시에 복수의 테스크들의 밸런스를 어떻게 주어야하는지, 불확실성(Uncertainity)을 기반으로 방법론을 제시합니다. 이 논문에서는 불확실성을 타나낼 수 있는 학습가능한 파라미터를 제시해서 손실함수에 함께 사용합니다.
Multi-task deep learning
아래의 이미지는 한 이미지로부터 서로 다른 3가지의 테스크을 수행하고, 3테스크의 손실함수를 합하여 최적화하는 일반적인 방법론입니다. 멀티테스크러닝(MTL)은 이런 유사한 테스크를 함께 사용하는 경우 하나의 테스크만 사용하는 것보다 더 높은 성능을 보일 수 있습니다.
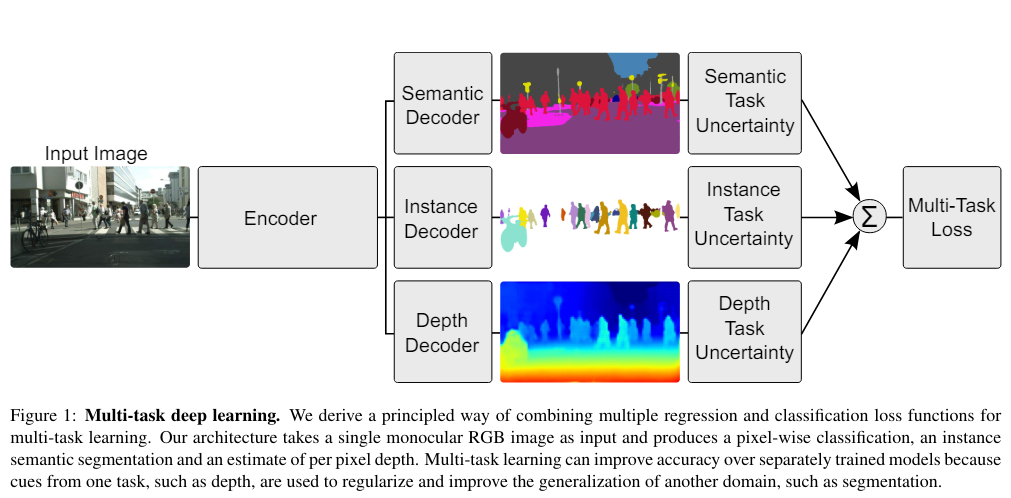
문제는 이 테스크들의 각각의 손실함수 1), 2), 3)이 있을텐데, 이 테스크를 어떻게 가중치를 주어야하는지에 대한 고민입니다. 1:1:1이 최적일까요? 아닐 수 있습니다. 보통 이 가중치(비율)을 휴리스틱하게 여러 번의 실험을 하면서 실험적으로 구하기에, 매우 비용이 많이듭니다. 본 논문은 MTL시에 가중치를 불확실성기반으로 최적화하는 방법을 제안합니다.
Methods
MTL은 테스크가 N개면 N개의 손실함수를 보통 갖습니다. 이 논문에서는 2개로 가정합니다. 아래의 (7)에서 표기들은 각각 아래와 같습니다.
- $\mathcal{L}(W,\sigma_{1},\sigma_{2})$: 최적화해야할 손실함수값입니다. $W,\sigma_{1},\sigma_{2} $각각의 인자에 따라서 값이 변화할 수 있음을 의미합니다.
- $\mathbf{W}$: 모델의 trainable parameter 입니다
- $\sigma_{1},\sigma_{2}$: 테스크 1, 테스크2에 대한 불확실성을 나타내는 trainable parameter입니다.
- $f^{ \mathbf {W}}(x)$: 모델의 output입니다.

(7)번식의 마지막 식을보면, 불확실성을 타나내는 파라미터가 각 테스크의 가중치로 있고, 마지막에 $log{\sigma_{1}\sigma_{2}}$에도 있습니다. 이는 불확실성($\sigma_{i}$)가 큰 경우 해당, 테스크의 손실함수를 별로 반영하지않기 위함입니다.
예를 들어보겠습니다. 1번 테스크의 불확실성이 큰 경우: $\sigma_{1}$이 커집니다. 따라서,$ \frac{1}{2\sigma_{1}^{2}}\mathcal{L}_{1}( \mathbf {W}) $은 작아집니다. 즉, 1의 불확실성이 큰 경우, 해당 테스크의 손실함수를 작게 반영합니다.
뒷항 $log{\sigma_{1}\sigma_{2}}$은 $ \sigma_{i}$가 무한히 커져 task1, task2의 손실함수($\mathcal{L}_{1}, \mathcal{L}_{2}$의 합이 무한이 작아짐을 방지하기위해서, log를 취하여 무한히 작아짐을 방지합니다.
Implementation
Pytorch Implementation이 있어, 이 깃헙의 주요 내용만 살펴보겠습니다.
- 16번: $\sigma$을 trainiable parameter로 만들기위해서, 몇개의 sigma을 만들지를 인자로 받습니다.
- 18번: 인자로 전달된 개수만큼 시그마를 1로 초기화합니다(=모든 테스크에 대해서 1로 초기화). gradient True로 최적화가 가능한 학습 가능한 변수로 합니다.
- 23~23번: 각 손실함수값에 대해서 loss와 trainable parameters을 이용해서 위의 (7)식을 계산합니다.
Results
손실함수의 값을 어떻게 조정하냐에 따라서, 아래와 같은 Table1의 표를 보여줍니다. unweighted sum of losss에 비해서 모든 테스크의 지표들이 향상됨을 확인할 수 있습니다.

'Data science > Deep learning' 카테고리의 다른 글
| Gradient accumulation (그레디언트 누적) (0) | 2025.01.22 |
|---|---|
| Pytorch DDP(Distributed Data Parallel), DP(Data Parallel) 비교 총정리 (0) | 2024.05.03 |
| [5분 컷 리뷰] Self-distillation 설명 (0) | 2024.04.11 |
| 분류문제: Cross entropy 대신에 MSE을 쓸 수 있나? + 역전파 및 MLE해석 (0) | 2022.11.23 |
| [5분 컷 이해] Multiple Instance learning 이란? (0) | 2022.11.08 |


