요약
확률 보정(Probability calibration)은 실제 데이터로 사건이 발생할(=분류할) 이벤트가 확률값처럼나오도록 하는 과정을 의미한다. 가령, 기상청에서 쓰는 강수확률모델이 강수확률이 80%이면, 기상조건이 같은 날짜만 모아서 예측한 경우, 80%만 비가왔어야한다. 이렇듯, 모델이 반환하는 확률값이 (정확히는 확률은 아니지만, 일종의 신뢰도 역할을 한다), 신뢰도 역할을 잘 잘 할 수 있도록 하는 작업을 확률 보정(Probability calibration)이라고 한다.
서론
Sklearn 공식 도큐먼트를보면 1.16에 Probability calibartion에 대해 소개가 되어있다 [1]. ML모델로 얻은 확률(.predict_proba로 얻은 확률)은 우리가 실제로 확률처럼 쓸수 있냐면? 그건 아니다. 이진분류라면, 모델이 반환한 확률값이 0.8이었다면(1=positive case), 실제 positive class중에 80%정도만 모델이 맞추었어야한다. 모델이 반환한 확률이 1이라면? 모델이 1이라고 찍은 데이터들은 100% positive case여야한다.
켈리브리에이션 커브(Calibation curves): 얼마나 확률이 신뢰도를 잘 대변하고 있는지 파악할 수 있는 다이어그램
아래의 그림을 Calibration curves (=reliabiltiy diagrmas)이라고 한다. 이는 확률 값이 실제로 이진분류상에서 얼마나 신뢰도를 대변할 수 있는지를 보여주는지를 알려주는 그림이다. X축은 모델이 각 평균적으로 내뱉는 확률값(구간화한값인듯), y축은 그 중에 실제 positive가 얼마나 있었는지를 의미한다. 확률이 잘 보정되었다면, 실제 positive case중에 모델이 예측한 케이스의 비율과 동일할 것이다. 즉 이 선은 기울기가 1인 점선처럼 나와야 한다.
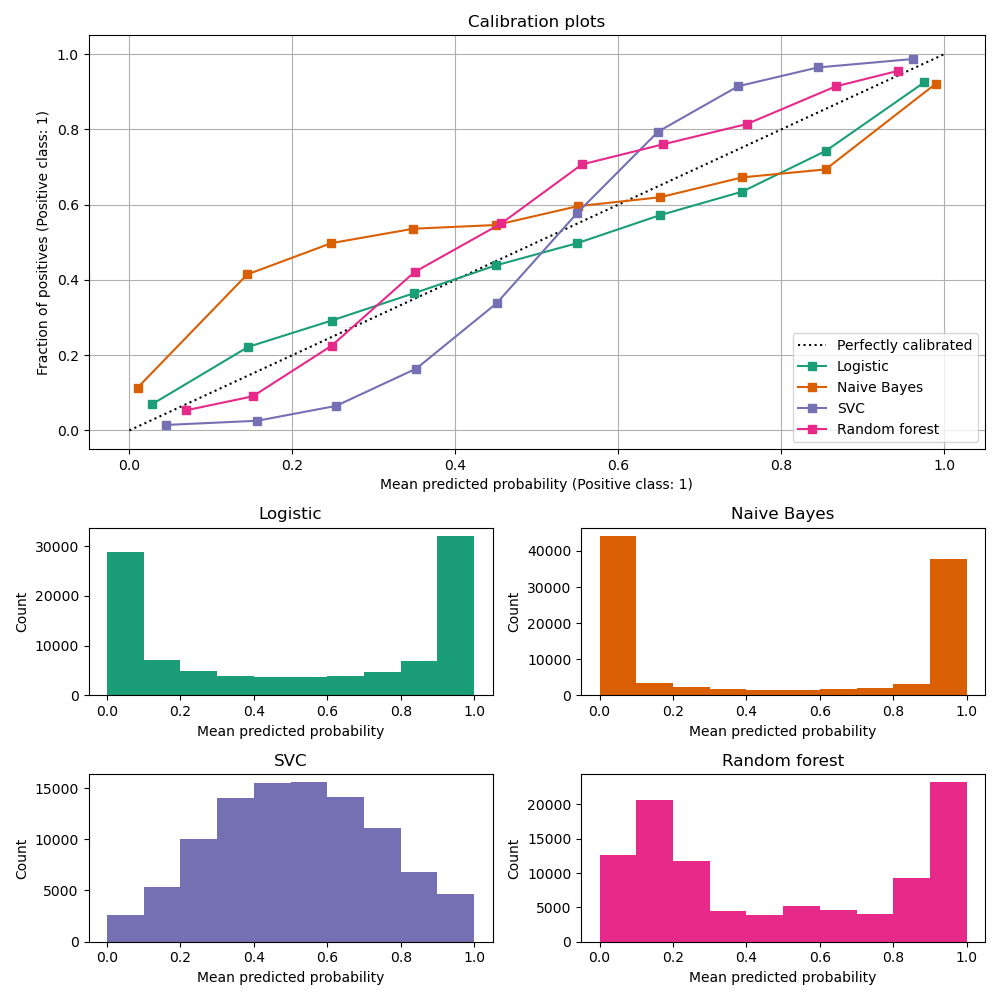
위의 그래프를보면, logistic 모델의 경우(녹색) 잘 보정이 되어있고, 다른 방법론들은 그러하지 못하다. GaussianNB은 대다수가 0, 또는 1에 가까운 확률을 내뱉는다. Random Forest의 경우에는 히스토그램이 0.2, 0.9에서 피크치고, Calibration curve에서도 S형을 보인다. 이에 대해서 한 연구자(Niculescu-Mizil and Caruana)가 다음과 같은 설명을 했다. Bagging 또는 random forest의 경우는 확률이 0 이나 1이 나오는 경우는, 유일하게 한가지로, 모든 random forest의 tree(앙상블방법들의 weak learner)가 다 0의 확률을 예측해야 한다. 사실상 조금 어려운 경우이고, 우리가 일부 RF에 노이즈를 주더라도 0에서 멀어질 수밖에 없다[2].
어떻게 확률를 조정(calibartion)할 수있나? 매핑함수를 하나 더 씌워본다
수식이 직관적이어서 바로 서두에 작성한다.
$p(y_{i}=1|f_{i})$ 을 해줄 후처리 함수하나만 만들면 된다.
국룰이 없다. 단, 모델을 훈련할 때 사용했던, 데이터로는 사용하지 말아야한다. 왜냐하면, 훈련데이터로하면 성능이 워낙 좋기때문에, test 데이터로 찍은 확률과 차이가 있을 수 있기 때문이다. 즉, 본인이 테스트할 데이터를 가지고 예측기에, 각 확률만큼 positive 케이스를 맞추도록 보정하여야한다. 이 보정은 어떤 함수여도 상관이 없다. Sklearn에서는 CalibratiedClassifierCV라는 툴을 제공해서 모델의 확률이 calibration되도록 만들어준다. 대표적으로 쓰이는 방법은 2가지인데, isotonic과 sigmoid 방법이다.
Isotonic: $\sum_{i=1}^{n}(y_{i}-\hat{f_{i})^{2}}$ where $ \hat{f_{i}^{2}} = m(f_{i}) + e_{i} $
- Isotonic 방법은 non-parametric 방법(학습할 파라미터가 없이)으로 확률값을 보정하는 방법이다. $y_{i}$은 $i$번째 샘플의 실제 라벨을 의미하고, $\hat{f_{i})^{2}}$은 calibration된 분류기의 출력을 의미한다. 즉, calibration 시키기위해서 단조증가 함수를 하나 씌워서 만드는 것이다.[3]. 여기에 해당하는 $m$을 하나 학습해야하는데, 이거는 iteration돌면서 윗 식을 최소화할 수 있는 m을 찾는다. 전반적으로 Isotonic이 아래의 Platt calbiration보다 성능이 좋다고 알려져있다.
Sigmoid (=Platt calibration) : $ P(y=1|f) = \frac{1}{1+exp(Af+b)}$
- 확률값(f)을 다시 A, B을 학습시켜서 학습할 수 있도록 하는 방법이다. 이 방법에서는 A, B을 찾기위해서 Gradient descent을 사용한다고 한다.
예제코드
아래와 같이 Calibration plot으로 실제 예측치 중에 몇의 positive case가 있는지 파악할 수 있다. prob_pred은 각 확률의 구간들을 평균낸 것이다. 예를들어 n_bins에 따라서, 하위구간의 확률을 가진 샘플 10개가 평균적으로 얼마의 확률을 가졌는지를 의미한다. 이에 해당하는 실제 positive data point의 수가 prob_true이다.
그렇게해서 아래와 같이 CalibrationDisplay함수를 이용해서 plot으로 확률이 어느정도 신뢰도를 대변할 수 있는지 파악할 수 있다 [3].
import sklearn
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
x, y = make_classification(
n_samples=10000, n_features=20, n_informative=2, n_redundant=10, random_state=42
)
x_train, x_test, y_train, y_test = train_test_split(x, y)
base_clf = SVC(probability=True)
base_clf.fit(x_train, y_train)
# Calibriation plot 그리기
from sklearn.calibration import calibration_curve, CalibrationDisplay
y_prob = base_clf.predict_proba(x_test)[:, 1]
prob_true, prob_pred = calibration_curve(y_test, y_prob, n_bins=10)
disp = CalibrationDisplay(prob_true, prob_pred, y_prob)
disp.plot()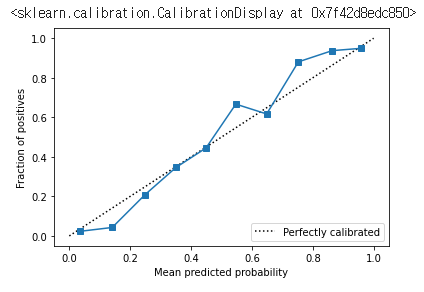
Calibration은 아래와 같이 진행한다.
from sklearn.calibration import CalibratedClassifierCV
calibriated_clf = CalibratedClassifierCV(base_estimator=base_clf, method="isotonic", cv=2)
calibriated_clf.fit(x_test, y_test)
pred_y = calibriated_clf.predict_proba(x_test)[:, 1]
prob_true, prob_pred = calibration_curve(y_test, pred_y, n_bins=10)
disp = CalibrationDisplay(prob_true, prob_pred, pred_y)
disp.plot()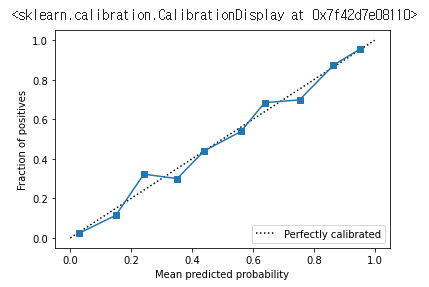
[1] https://scikit-learn.org/stable/modules/calibration.html#probability-calibration
[2] Predicting Good Probabilities with Supervised Learning, A. Niculescu-Mizil & R. Caruana, ICML 2005
https://www.cs.cornell.edu/~alexn/papers/calibration.icml05.crc.rev3.pdf
'Data science > Deep learning' 카테고리의 다른 글
| 분류문제: Cross entropy 대신에 MSE을 쓸 수 있나? + 역전파 및 MLE해석 (0) | 2022.11.23 |
|---|---|
| [5분 컷 이해] Multiple Instance learning 이란? (0) | 2022.11.08 |
| 5분 이해: 텐서플로우 역전파(Backpropagation) 사용 (0) | 2021.06.08 |
| Machine learning 분류 (0) | 2021.05.24 |
| Few shot learning 이란? (0) | 2021.04.28 |


