Doc2vec, Word2vec처럼 각각의 단어를 벡터로 표현하고자하는 시도가 꽤 있어왔다. 이런 벡터표현은 단순히 bag-of-words으로 표현하거나, one-of-k (흔히 one-hot vector)라고 부르는 방법으로 표현할 수 있다. 그러나 이러한 시도들은 여러 문제가 있었고, word2vec으로 더 밀도있는 표현방식(denser representation)을 사용했다. 한 단어를 doc2vec으로 임베딩하여 표현할 수 있었듯이, document 또는 paragraph을 벡터로 표현할 수 있는데 왜 supervised paragraph2vec가 필요한건가? 이에 대한 장점은 있는건가? 이에 대한 대답을 Supervised Paragraph Vector: Distributed representations of words, documents, and class에서 찾을 수 있다.
Supervised paragraph vector가 필요한 이유?
범용적인 임베딩모델(예, doc2vec, paragraph2vec 이하 PV)은 정말 단순한 알고리즘으로 hidden layer가 하나만 존재하여 매우 학습이 편하고, 쓰기도 편하지만, 임베딩에 다음과 같은 문제가 있다. word2vec의 CBOW(continous bag of words)을 생각하면, 단어벡터(word vector, 단어를 임베딩한 벡터)를 구문론적(syntactical)으로 학습하기도하고, 의미론적(semantic)적으로 학습하기도 한다. 예를 들어, "the cat sat on the mat"이라면, cat을 예측할땐, 주변단어인 the와 sat을 이용해서 예측한다. 따라서 유사한 단어가 동시에 많이 출현될수록, 같은 벡터로 표현될 확률이 높고, 주변단어의 쓰임이 비슷하게 나왔을 때도, 유사한 벡터로 임베되는 경향이 있다 (Figure 1. A). 하지만, 해결해야하는 문제가 감정분석(sentimental analysis)로, wonderful과 amazing이 같은 그룹으로, terrible, awful이 부정그룹으로 분리되서 해야한다면 어떨까? 동시출현 또는 유사한 단어가 많이 출현하는 것을 학습하여 임베딩하는 word2vec의 이런 학습방식은 특정테스크에 모두 걸맞게 쓰기가 쉽지가 않다. 이런 일반화된 분석방법으로는 이런 임베딩의 표현의 의사결정바운더리(decision boundary)을 긋기가 쉽지않다. 본 논문은 word2vec, paragraph2vec, doc2vec의 제한점을 해결하고자 시도했던 논문이다.
word2vec의 출력에이어의

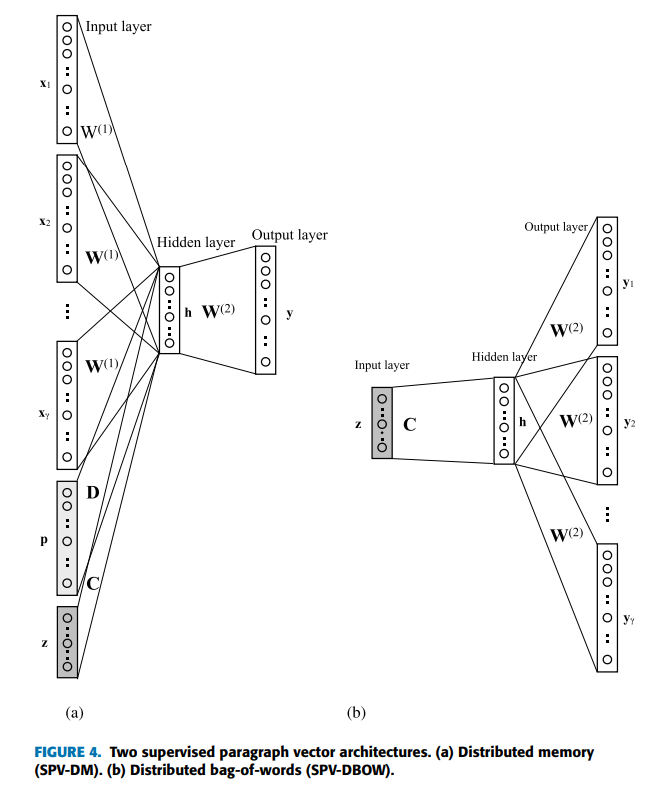
SPV의 핵심 아키텍처
해결방법은 다음과 같다. word2vec의 아키텍처와 같이 하나의 입력레이어, 하나의 히든레이어, 하나의 출력레이어로 구성한다(Figure 4-A). 좌측에 아키텍처의 구성을보면, $x1,..., x_{\gamma}$까지는 한 문단에 들어가있는 단어가 one hot vector로 변환된 벡터를 의미한다. 각각 one-hot vector로 표시할 때, 총 단어의 개수가 V라면, V개 원소의 개수를 가지고, 원소중 하나만 1인 벡터가 된다. 차이점이라면, 다음과 같은 벡터들도 입력값에 전달된다. 바로 도큐먼트의 one-hot vector인 $p$와 클레스의 라벨인 $z$가 추가로 전달된다는 것이다. 아래의 그림에서는 $p$은 전체 문서(documents)의 수를 의미한다. $z$은 클레스라벨을 의미해서, $M$개의 클레스가 존재한다고 했을 때, 각각 하나하나를 one-of-K(one-hot)벡터로 인디케이팅한 것을 의미한다. 그리고 h에 해당하는 히든레이어의 출력을 $\delta$개의 원소를 가진 벡터라고하자.
위와 같이 셋팅한 경우, $W^{(1)}$은 임베딩을 위한 dense layer의 가중치 메트릭스로 $\mathbb{R}^{V\times\delta}$가 된다(V개의 one-hot vector을 $\delta$개로 압축하는 fully connected layer 이기 때문). $W^{(2)}$은 출력레이어의 가중치로 W1의 전치행렬과 크기가 같다(왜냐하면, 출력해야하는 단어도 V개의 벡터여야 하기 때문이다).
위의 아키텍처에서 목적함수를 클레스라벨이랑 도큐먼트의 인덱스 단어에 최대한 학습할 수 있게 다음과 같이 정의하였다.
1. SPV-DM(여러 단어가 주어진 경우, 한단어를 예측하는문제): 아래의 우변의 시그마 내 첫 항은 "CBOW와 같이 주변단어가 주어졌을 때, 예측하고자하는 단어를 예측하기위한 손실함수", 두 번째 항은 "문서내에 해당 예측하고자 하는 단어가 있을 확률", 세 번째 항은 "문서의 라벨이 주어졌을 때, 해당 단어가 있을 확률"을 모두 더한 값이다.
$L_{SPV-DM} = \frac{1}{T}\sum_{t=1}^{T}\sum_{j=1}^{\gamma}log(p(w_{t}|w_{t+j})+log(p(w_{t}|d))+log(p(w_{t}|c)))$
2. SPV-DBOW(한 단어가 주어진 경우, 여러단어를 예측하는 문제)
$L_{SPV-DBOW} = \frac{1}{T}\sum_{t=1}^{T}\sum_{j=1}^{\gamma}log(p(w_{t+j}|c))$
논문에는 등장하지 않는 limitations
1. 본 모델은 word2vec에 사용되는 모델과 구조가 유사해서, OOV(out of vocabulary)의 문제를 그대로 갖고있다. 따라서 unseen data에 대해서는 모델이 강건하지 않을 수 있다.
'Best Paper review > Others' 카테고리의 다른 글
| [5분 요약] A deep quadruplet network for person re-identification: 해석 (0) | 2022.06.23 |
|---|---|
| Fasttext: Enriching Word Vectors with Subword Information 5분 컷 리뷰 (0) | 2021.12.07 |
| 자연어처리의 고전 BERT, 5분 컷 이해 (0) | 2021.10.25 |
| ICLR 2018: FEW-SHOT LEARNING WITH Graph 풀이 (0) | 2021.06.22 |
| 2019 best paper: Ordered Neurons 해석 (0) | 2021.06.21 |















