Out-of-distribution detection in digital pathology: Do foundation models bring the end to reconstruction-based approaches, Computers in Biology and Medicine, 2025
Motivation
- Foundation models(FM)이 분류문제에서도 도움이 꽤 되는데, OOD detection에서도 도움되지 않을까
- Difusion으로 Reconstruction based OOM은 계산비용이 크기에, latent difusion model (LDM)과 step을 줘보자
Methods
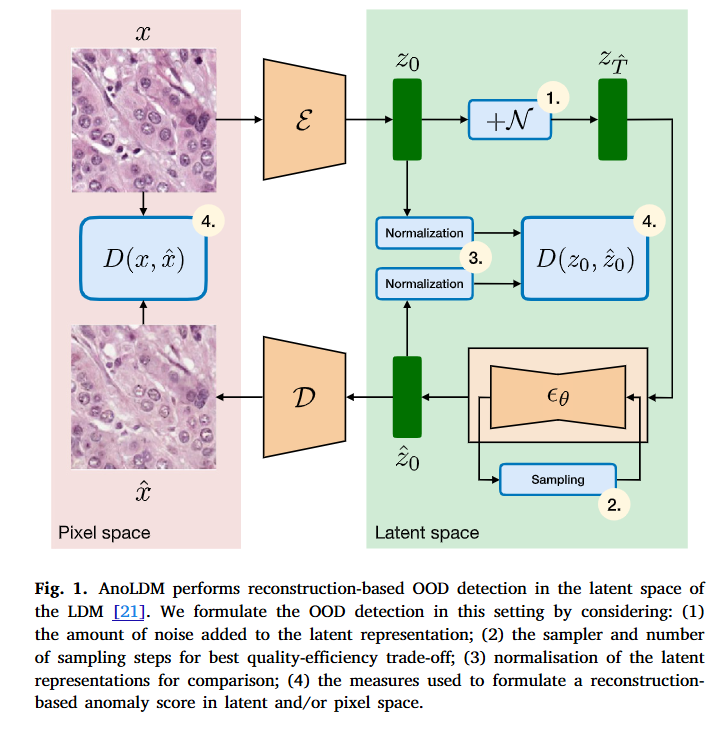
- LDM 모델
- 이미지를 임베딩: $z=\varepsilon(x)$ (인코더 파트)
- 노이즈를 추가: $z_{t}=z_{0}+\epsilon_{t}$
- ID data에 대해서만 디노이저가 학습했을 것이고, ID data에서 원본을 보존하면서 노이즈만 지우는 방식으로 학습되었을 것. 따라서, OOD data가 입력으로 들어온경우, 원본에 대한 이해가 없어서, 노이즈 뿐아니라 원본도 지우게 될 것. 따라서, 두 이미지의 거리를 비교하면
- 이미지에서 노이즈를 제거: $z_{t-1} = z_{t}-\epsilon_{\theta}(z_{t},t)$ (디코더 파트)
- 고려사항
- 노이즈 수준(noise level): 여러 스텝에서 노이즈를 주기 어려워서, step을 줄이자니 노이즈를 적절히 잘 주어야함.
- 샘플링: 노이징 + 디노이징 과정을 말함. Step을 줄여야해서 여러 샘플러들과의 조합을 확인.
- 잠재공간 정규화(Latent space normalization): feature space에서 각 값들이 열려있어서, 적절한 정규화가 필요함.
- 거리 지표: MSE, SSIM, MS-SSIM, LPIP
Conclusion
- 이 분야에서 주로쓰이는 one-class SVM이랑 비교를 안해서 아쉬운 연구
Related work
- 자연계이미지에서 OOD detection: 생성형모델을 이용하여 OOD detection하는 경우가 있음.
- Likelihood을 지표로 사용하는 방법: In distribution data은 잘 학습했기에 Likelihood(=분포에 맞는가?)가 높을테고, 반대로 본적없는 OD의 경우는 낮을 것. 예를 들어, $p(x)$가 모델이 생각하는 입력의 확률값. 하지만, 이 방법들은 저수준 특징(밝기, 색상, 텍스처, 가장자리)에 집중만해서 Likelihood가 높을 수 있음.
- 복원 품질을 지표로 활용: 테스트 이미지를 복원해서 얼마나 복원이 잘되었는지를 평가. $||x-\hat{x}||$
- 병리이미지에서의 OOD:
- 복원품질 비교: DDPM을 이용해서 복원이미지를 생성하고, 원본이미지와 복원이미지를 비교. (역시 연산량이..)
- 불확실성 비교: 분류기의 불확실성을 이용하는 비교 방법 (domain shift에 약함)
- 분류기의 특징: 분류기가 사용하는 특징값(벡터)을 이용하는 방법.
반응형