Pytorch DDP(Distributed Data Parallel), DP(Data Parallel) 비교 총정리
요약
| DP | DDP | |
| 모델 복제 오버해드 | 매 반복마다 각 GPU에 모델 복제 | 초기 한번만으로 프로세스에 모델 복제 |
| 데이터 분산 및 수집 | Scatter-Gather방식으로 통신비용발생 | 각 프로세스가 독립적으로 작업 (통신비용 적음) |
| GIL | GIL로인해 multi-thread 성능제한 | GIL문제없음 |
| 통신비용 | GPU간 동기화없음 | GPU 간 All-redeuce 통신비용발생 |
| 적합한 환경 | 단일 머신 | 멀티노 |
DataParallel (DP)
DP은 데이터 병렬화 기술 중, 싱글노드에서만 사용할 수 있는 병렬화 기술입니다. DP은 한 프로세스에서만 돌아가기에 "Single process, multi-threaded"입니다. 하나의 프로세스에서 여러 GPU을사용하는 방식입니다. 즉 하나의 프로세스이기 때문에, 모델과 데이터를 한 번만 메모리에 로드하고, 공유하는 방식입니다. 레핑코드인 torch.nn.DataParallel은 다음과 같은 방법을 따릅니다.
- Scatter mini-batch inputs to GPUs: DataLoader에서 병렬처리를하든 일단 하나의 GPU로 데이터를 모은 후, 이를 서로다른 GPU에 퍼뜨립니다. (여기서 불필요하게 오버해드가 발생합니다. 큰 데이터를 로드하는 경우, 데이터를 복사하는데 병목이 될 수 있습니다)
- Replicate model on GPUs: DP은 매 반복(step, iteration)마다 모델의 복제본(model replicas)을 만들어 각 GPU에 뿌려줍니다. 이유는 각 GPU가 독립적으로 연산을 수행할 수 있도록 동리한 모델을 GPU별로 만들기 위함입니다.(여기서 불필요하게 오버해드 발생)
- Parallel forward: 이 단계에서는 미니배치가 N이라면, N/4씩의 미니배치씩 처리하여 출력을 생성합니다. (이 과정은 병렬로 처리되기 때문에, 데이터가 미리 복제가되지않았거나, 모델이 복제되지 않았다면 연산시작까지 대기해야해서 오버해드가 발생합니다)
- Gather : 모든 출력을 하나의 GPU1에 가져옵니다. 이 과정에서는 GPU to GPU 통신이 발생합니다. (GPU1의 데이터를 모으는 과정에서 병목이 발생할 수 있음)
- Compute gradient: O1~O4까지 얻었으니 하나로 합쳐서 loss을 계산합니다. 이 합친 텐서에서는 .grad_fn 속성에 GatherBackward가 붙는데 여러 GPU에서 왔음을 알 수 있는 흔적입니다.
- Backword process: 하나의 모델에 대하여 백워드 프로세스가 진행됩니다.
- Parameter update: 모델의 파라미터를 한 GPU에서 업데이트 합니다.
import torch
from torchvision.models import resnet50
model = resnet50()
dp_model = torch.nn.DataParallel(model).to("cuda") # 이 단계까지는 GPU:0에만 옮겨집니다.
o = dp_model(torch.rand(8, 3, 256, 256)) # forward하는 순간 모델이 복제되고 배치가 나뉘어집니다.
o.device
tensor([[-0.4658, -0.4177, 1.4429, ..., -0.5929, 0.6103, -0.0062],
[-0.2560, -0.3838, 1.4179, ..., -0.4299, 0.6211, 0.0942],
[-0.3859, -0.4096, 1.4012, ..., -0.5815, 0.6894, -0.0200],
...,
[-0.4031, -0.4946, 1.3107, ..., -0.4936, 0.5158, 0.0206],
[-0.3646, -0.3747, 1.4674, ..., -0.5438, 0.6902, -0.0674],
[-0.3301, -0.4867, 1.3945, ..., -0.4488, 0.6343, 0.0417]],
device='cuda:0', grad_fn=<GatherBackward>)model = nn.DataParallel(model)
# 옵티마이저 초기화
optimizer.zero_grad()
# 순전파
outputs = model(inputs) # 이 단계에서 모델복제, 데이터 scatter, forward, gather가 이뤄짐
# 손실 계산
loss = criterion(outputs, labels) # 손실은 하나의 GPU에서만
# 역전파
loss.backward() # 역전파도 하나의 GPU에서만
# 파라미터 갱신
optimizer.step() # 파라미터 갱신
실제로 pytoch.nn.DataParallel에서도 다음과 같이 foward가 정의되어있습니다. 모아서 output만 반환해주는 것이죠.
class DataParallel(Module, Generic[T]):
def forward(self, *inputs: Any, **kwargs: Any) -> Any:
inputs, module_kwargs = self.scatter(inputs, kwargs, self.device_ids)
replicas = self.replicate(self.module, self.device_ids[: len(inputs)])
outputs = self.parallel_apply(replicas, inputs, module_kwargs)
return self.gather(outputs, self.output_device)
# 사용시
CLASS torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)아래와 같이 DP은 `torch.DataParallel(model)`의 원라인만 추가하면 사용할 수 있던 기술입니다 [1, 2]. 이 클레스는 데이터 병렬(DP)은 모듈레벨(torch.nn.module) 에서 손 쉽게 사용할 수 있도록 구현한 것입니다. 일단 데이터를 작은 배치사이즈로 나눈 후(split), 데이모델을 각 장치(GPU)에 복제한 후, 데이터를 fowarding합니다. 이후, 각 복제된 모델로부터 백워드(backpropagation)을 진행하고, 원본(original module, 첫 번째 장치에 있던)로 모듈로 가져와 집계합니다[3].
- module: pytorch model을 의미
- device_ids:cuda devices (디폴트가 all devices)
- output_devices: 복제한 모델로부터 집계할 장치를 의미합니다. (디폴트: device_ids=[0])
어찌되었든 하나의 텐서를 모아서 backward을 진행하기 때문에, gather을 수행하는 GPU입장에서는 VRAM이 더 요구되는 사항입니다. 그래서 다른 개발자들은 Gradent까지 다 계산한다음에 GPU1로 가져오는 방법도 제안합니다.
Distributed DataParallel (DDP)
DDP은 데이터 병렬화를 모듈레벨(모델레벨)에서 쉽게 구현한 것이고, 노드수(=머신수)가 여럿일 때도 사용할 수 있습니다. DPP은 병렬처리시에, multiprocessing으로 프로세스를 spawn(부모프로세스의 메모리를 복제하지 않는, 새롭게 프로세스를 실행시키는) 방식으로 진행합니다(spawn vs fork 설명)
| 병렬처리방식 | 노드수 | 속도 | |
| DP | Multithread (GIL발생) | 싱글 노드 | 느림 |
| DDP | Multiprocessing | 싱글 / 멀티 노드 | 빠름 |
파이토치 세팅은 내부통신이 여러방법이 가능한데, 별도의 설치는 필요없고 파이토치 패키지 내에 들어가있습니다(`torch.distributed`). 가장기본적으로 아래와 같이 할 수 있습니다.
싱글머신에서는 아래와 같이 진행합니다.
"""run.py:"""
#!/usr/bin/env python
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def run(rank, size):
""" Distributed function to be implemented later. """
pass
def init_process(rank, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank, world_size=size)
fn(rank, size)
if __name__ == "__main__":
size = 2
processes = []
mp.set_start_method("spawn")
for rank in range(size):
p = mp.Process(target=init_process, args=(rank, size, run))
p.start()
processes.append(p)
for p in processes:
p.join()
- `init_process`: 마스터노드와 통신하기위해서 마스터노드의 호스트IP와, PORT을 지정합니다. backend은 어떻게 통신할 것인가에 대한 백엔드를 의미하는 것이며 `gloo`, `NCCL`, `MPI`, `Filesystem`, TCP`와 같은 백앤드가 가능합니다. 위 예시에서는 싱글 노드의 예시이므로 자기 자신 `127.0.0.1`로 통신하도록 되어있습니다.
- `dist.init_process_group`: 프로세스 그룹을 초기화합니다. 인자 중 `rank`은 프로세스의 순위를 나타내며, 스폰되는 프로세스의 수만큼 0부터 N까지 랭크를 갖습니다. `world_size`은 스폰되는 전체 프로세스의 총 수를 의미합니다. 아래의 그림은 멀티프로세스 4개를 띄운 상태며, 0-3을 포함한 각각의 랭크를 지닌 프로세스입니다.

두 개의 프로세스를 띄워서 DDP로 병렬처리하는 코드는 아래와 같습니다.
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
import os
from torch.nn.parallel import DistributedDataParallel as DDP
def example(rank, world_size):
# create default process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
# create local model
model = nn.Linear(10, 10).to(rank)
# construct DDP model
ddp_model = DDP(model, device_ids=[rank])
# define loss function and optimizer
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# forward pass
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
# backward pass
loss_fn(outputs, labels).backward()
# update parameters
optimizer.step()
def main():
world_size = 2
mp.spawn(example,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__=="__main__":
# Environment variables which need to be
# set when using c10d's default "env"
# initialization mode.
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "29500"
main()
Distributed Data-Parallel with multi-mode
멀티 노드로 분산처리하기위해서는 파이토치 유틸리치 중하나인 `torchrun`을 이용해야합니다.
- torchrun을 이용하면 `run`, `world_size`을 명시적으로 전달할 필요도 없고 환경변수도 알아서 세팅해줍니다.
- DDP을 이용할 때 사용하는 `torch.multiprocessing.spawn`도 사용할 필요없습니다.
각 머신에서 돌려야하는 소스코드는 아래와 같다고 생각해보겠습니다.
import torch
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from datautils import MyTrainDataset
import torch.multiprocessing as mp
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed import init_process_group, destroy_process_group
import os
def ddp_setup():
init_process_group(backend="nccl")
torch.cuda.set_device(int(os.environ["LOCAL_RANK"]))
class Trainer:
def __init__(
self,
model: torch.nn.Module,
train_data: DataLoader,
optimizer: torch.optim.Optimizer,
save_every: int,
snapshot_path: str,
) -> None:
self.local_rank = int(os.environ["LOCAL_RANK"]) # 머신 내 프로세스들의 랭크
self.global_rank = int(os.environ["RANK"]) # 전체 머신에서의 각 프로세스의 랭크
self.model = model.to(self.local_rank)
self.train_data = train_data
self.optimizer = optimizer
self.save_every = save_every
self.epochs_run = 0
self.snapshot_path = snapshot_path
if os.path.exists(snapshot_path):
print("Loading snapshot")
self._load_snapshot(snapshot_path)
self.model = DDP(self.model, device_ids=[self.local_rank]) # DDP로 감싸줍니다.
def _load_snapshot(self, snapshot_path):
loc = f"cuda:{self.local_rank}"
snapshot = torch.load(snapshot_path, map_location=loc)
self.model.load_state_dict(snapshot["MODEL_STATE"])
self.epochs_run = snapshot["EPOCHS_RUN"]
print(f"Resuming training from snapshot at Epoch {self.epochs_run}")
def _run_batch(self, source, targets):
self.optimizer.zero_grad()
output = self.model(source)
loss = F.cross_entropy(output, targets)
loss.backward()
self.optimizer.step()
def _run_epoch(self, epoch):
b_sz = len(next(iter(self.train_data))[0])
print(f"[GPU{self.global_rank}] Epoch {epoch} | Batchsize: {b_sz} | Steps: {len(self.train_data)}")
self.train_data.sampler.set_epoch(epoch)
for source, targets in self.train_data:
source = source.to(self.local_rank)
targets = targets.to(self.local_rank)
self._run_batch(source, targets)
def _save_snapshot(self, epoch):
snapshot = {
"MODEL_STATE": self.model.module.state_dict(),
"EPOCHS_RUN": epoch,
}
torch.save(snapshot, self.snapshot_path)
print(f"Epoch {epoch} | Training snapshot saved at {self.snapshot_path}")
def train(self, max_epochs: int):
for epoch in range(self.epochs_run, max_epochs):
self._run_epoch(epoch)
if self.local_rank == 0 and epoch % self.save_every == 0:
self._save_snapshot(epoch)
def load_train_objs():
train_set = MyTrainDataset(2048) # load your dataset
model = torch.nn.Linear(20, 1) # load your model
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
return train_set, model, optimizer
def prepare_dataloader(dataset: Dataset, batch_size: int):
return DataLoader(
dataset,
batch_size=batch_size,
pin_memory=True,
shuffle=False,
sampler=DistributedSampler(dataset)
)
def main(save_every: int, total_epochs: int, batch_size: int, snapshot_path: str = "snapshot.pt"):
ddp_setup()
dataset, model, optimizer = load_train_objs()
train_data = prepare_dataloader(dataset, batch_size)
trainer = Trainer(model, train_data, optimizer, save_every, snapshot_path)
trainer.train(total_epochs)
destroy_process_group()
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description='simple distributed training job')
parser.add_argument('total_epochs', type=int, help='Total epochs to train the model')
parser.add_argument('save_every', type=int, help='How often to save a snapshot')
parser.add_argument('--batch_size', default=32, type=int, help='Input batch size on each device (default: 32)')
args = parser.parse_args()
main(args.save_every, args.total_epochs, args.batch_size)
multinode training을 할 경우에는 training job을 직접 SLURM이라는 스케쥴러를 이용해서 돌리거나, torchrun을 이용해서 각자 머신에 실행시키거나 해야합니다. 위의 코드는 `torchrun`으로 같은 rendezvous 인자를 전달해서 돌리는 예시입니다.
// node 1
$ torchrun \
--nproc_per_node=1 \
--nnodes=2 \
--node_rank=0 \
--rdzv_id=456 \
--rdzv_backend=c10d \
--rdzv_endpoint=127.0.0.1:29603 \
multinode_torchrun.py 50 10
// node 2
$ torchrun \
--nproc_per_node=1 \
--nnodes=2 \
--node_rank=1 \
--rdzv_id=456 \
--rdzv_backend=c10d \
--rdzv_endpoint=[node 1의 IP]:29603 \
multinode_torchrun.py 50 10
아래와 같이 올바르게 학슴됨을 확인할 수 있습니다.
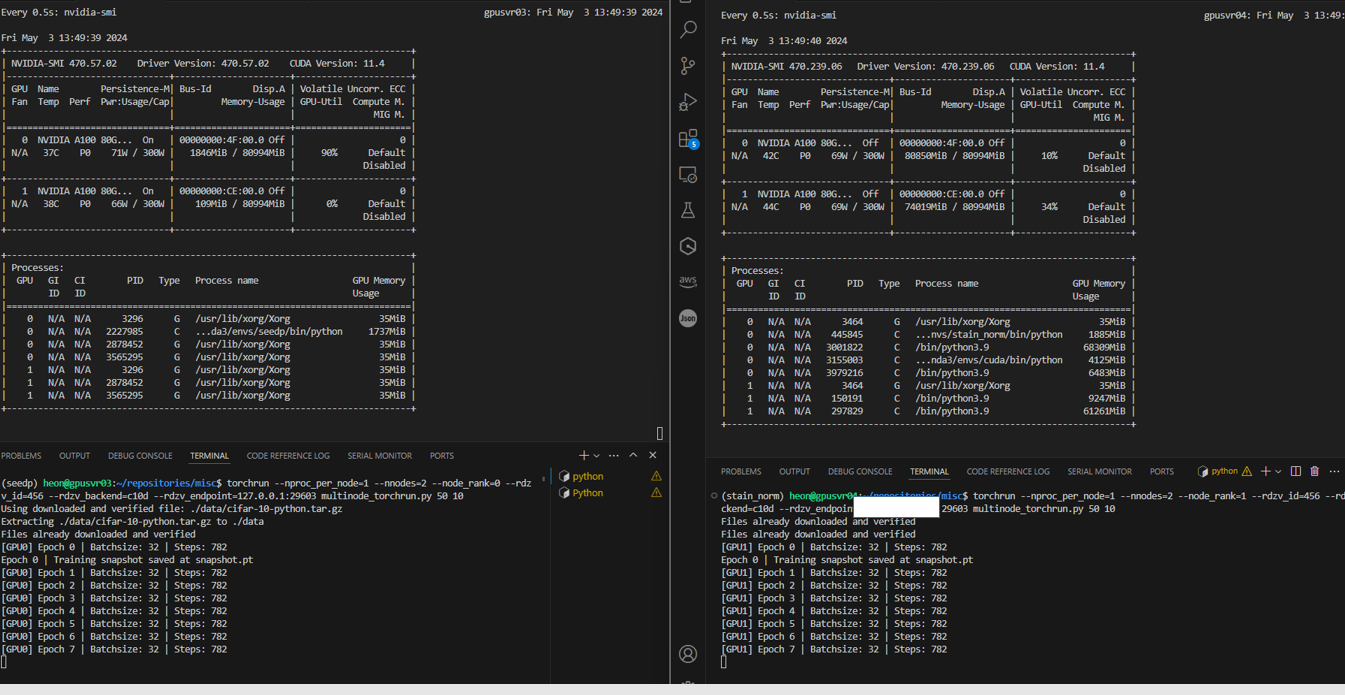
Load map
노드 수, GPU, 스케쥴러 지원에 따라 데이터병렬화 방법
| 노드 수 | GPU 수 | 데이터페러렐 방법 | 스케쥴러지원 |
| Single-machine | single GPU | DistributedDataParallel | NA |
| Single-machine | multiple GPU | DistributedDataParallel | NA |
| Multi-machine | multiple GPU | torchrun + rendezvous | X |
| Multi-machine | multiple GPU | SLURM 이용 | SLURM |
Trouble shooting 1): The IPv6 network addresses of (서버명, 55039) cannot be retrieved (gai error: -3 - Temporary failure in name resolution
- 도메인을 찾지 못하는 문제입니다. `DNS`쪽 문제일 수 있습니다. DNS 세팅을 다시하거나 서버명에 해당하는 내용을 `/etc/hosts`에 추가합니다.
저의 경우 아래와 같이, `etc/hosts`을 추가해서 해결했습니다.
heon@gpusvr04:~/repositories/misc$ cat /etc/hosts
127.0.0.1 localhost
127.0.1.1 gpusvr04
***.***.***.*** gpusvr03