[5분 안에 이해하는] 프롬프트 엔지니어링 핵심기법: Few shot ,CoT, SC, ReACT, RAG
프롬프트 엔지니어링
프롬프트 엔지니어링은 거대한 언어 모델을 사용하여 특정 작업이나 질문에 대한 원하는 출력을 얻기 위해 입력 프롬프트를 조정하는 과정을 말합니다. 이는 모델의 출력을 조정하고 원하는 유형의 답변을 생성하기 위해 입력 텍스트의 형식, 콘텍스트(맥락), 질문의 구조 등을 조정하는 것입니다. 즉, 프롬프트 엔지니어링은 거대언어모델(LLM)에 원하는 출력을 얻기 위해 입력 프롬프트를 조작하는 기술입니다. 이 글을 Prompting guide의 내용을 좀 더 쉽게 풀어쓴 글입니다.
In-context learning (ICL)
인컨텍스트 러닝(In-context learning)은 모델이 주어진 프롬프트 내의 예시에서의 학습을 하는 것을 의미합니다. 즉, 파인튜닝(미세조정)과 다르게, "런타임(runtime)"에서 프롬프트로부터 학습해서 더 나을 결과를 내도록 하는 기술을 의미합니다. 보통의 머신러닝은 훈련데이터(training data)로부터 학습해서 모델이 고정되고, 더 나은 성능을 유도하기가 쉽지 않은데 반해서, ICL을 이용한 경우, 프롬프트엔지니어링으로 이 학습의 결과를 유도할 수 있습니다.
Following the paper of GPT-3 (Brown et al., 2020), we provide a definition of in-context learning: Incontext learning is a paradigm that allows language models to learn tasks given only a few examples in the form of demonstration.
프롬프트엔지니어링과 ICL의 차이를 구붆하자면, 프롬프트엔지니어링은 수단에 가깝고,더 큰 범위를 말하며, In-context learning은 학습의 목적에 가까운 것 같습니다. 어찌보면, Few-shot과 유사합니다. Few-shot learning과 딱히 구별하기 어렵기도 합니다. 그래서 ICL을 few-shot learning, few-shot prompting이라고하기도합니다 [REF].
In-context learning (ICL) is known as few-shot learning or few-shot prompting
Zero-shot
제로샷은 학습해본 적없는 클레스에 대해서, 분류(Classification)하는 것을 의미합니다. 실제로 언어모델은 감정분류에 대해서 학습한적은 없습니다.
// 프롬프트
중립, 긍정, 부정으로 감정을 분류하세요.
오늘 코스피는 전일 대비 -2% 마감이었습니다.
감정:
// 결과
부정
Few-Shot prompting
위에서 보듯, Zero-shot도 어느정도 되지만, 복잡한 문제들은 실패합니다. 대신에 Few-shot은 Zero-shot과 대비하여, 몇 가지 추가적인 예시(질문-답변)들을 좀 더주는 것입니다. 컨텍스트 상에서의 학습을 유도하는 것입니다. reversed label을 주어도 잘 학습합니다.
//프롬프트
아래의 예시문장들을 참고하여, <문제>에 해당하는 다음의 문장을 긍정, 부정으로 감정을 분류하세요
<예시>
질문1: 오늘 코스닥은 전일 대비 +5% 상승 마감하였습니다.
정답1: 부정
질문2: 오늘 코스피는 전일 대비 -2% 마감이었습니다.
정답2: 긍정
질문3: 오늘 나스닥은 중동 전쟁으로 인해 전일 대비 -2% 마감이었습니다.
정답3: 긍정
질문4: 코스피, 코스닥은 전일 대비 +5% 상승 마감하였습니다.
정답4: 부정
질문5: 미국 나스닥은 전일 대비 +5% 상승 마감하였습니다.
정답5: 부정
</예시>
<문제>
질문: 오늘 코스피는, 전일 대비 +5% 상승 마감하였습니다.
정답:
// 결과
부정
Chain-of-Thought (CoT)
CoT기법의 핵심적인 내용은 사고과정의 중간내용을 추가(생성, 제공)하는 것입니다. 논리적인 사고의 중간내용을 추가로 작성해주어서, 복합한 문제에 대한 더 나은 성능을 기대할 수 있습니다. CoT가 가능한 이유는 GPT는 자기회기(Auto regressive)한 모델이기에, 여태 나온 문장의 결과를, 다시 입력값으로 사용하게됩니다. 즉, 현재의 반환값이, 미래의 입력값이 되기에 중간중간 어떤 텍스트를 생성하는지가 중요합니다. (https://arxiv.org/abs/2201.11903)
아래의 우측그림과 같이 정답이 유도되는 과정을 (A)에 추가로 기입해주기에, 자기회귀 중간에서 잘못된 답을 내놓지 않도록 유도하고, 결과적으로 더 나은 답을 유도하게 할 수 있습니다.

일반적인 프롬프트에서 작성하면 아래와 같이 틀린답을 얻을 수 있습니다.
문제: 저는 사과가 10개 있었습니다. 2개를 이웃에게 나눠주고, 2개는 사과가 상해서 버렸습니다. 그리고 5개의 사과를 더 샀고, 1개는 먹었습니다. 몇개가 남았나요?
정답: 12개가 남았습니다.
단계별로 사고하라는 말을 추가로 넣어보았습니다.
문제: 저는 사과가 10개 있었습니다. 2개를 이웃에게 나눠주고, 2개는 사과가 상해서 버렸습니다.
그리고 5개의 사과를 더 샀고, 1개는 먹었습니다. 몇개가 남았나요?
단계별로 생각해서, 단계별 사과의 수를 알려주고, 최종적으로 남은 사과의 수를 알려주세요. << 추가
정답:
1단계: 사과 10개
2단계: 이웃에게 2개를 나눠줌 -> (10 - 2 =) 8개의 사과가 남음
3단계: 2개를 버림 -> (8 - 2 =) 6개의 사과가 남음
4단계: 5개를 추가로 삼 -> (6 + 5 =) 11개의 사과가 있음
5단계: 1개를 먹음 -> (11 - 1 =) 10개의 사과가 남음
최종 정답: 남은 사과는 10개입니다.
SC(Self-Consistency)
프롬프트 엔지니어링 중에 가장 성능이 좋은 기법입니다 (https://arxiv.org/abs/2203.11171). CoT을 한 프롬프트를 N번 포워딩하여, 집계하는 방식으로 앙상블에 가까운 방식입니다. 아래의 3가지 순서로 이뤄집니다.
- CoT을 이용해서 프롬프팅을 합니다. 아래의 Figure 1과 같이 CoT을 이용해서, 사고과정에서의 중간과정을 해야한다는 컨텍스트를 제시하면서, A을 남겨 completion문제로 만듭니다.
- CoT의 과정과 유사하게 여러 사고방의 중간을 넣어줍니다.
- N개의 답변을 획득한 후 하나의 답변으로 요약합니다.
주의할 것은 여러 답변을 얻어내야하기 때문에, Temperature(randomness의 정도)을 0으로 하면 안됩니다. 또한, 언어모델을 여러번을 추론해야하기 때문에, 그 만큼의 연산비용도 같이 요구됩니다.

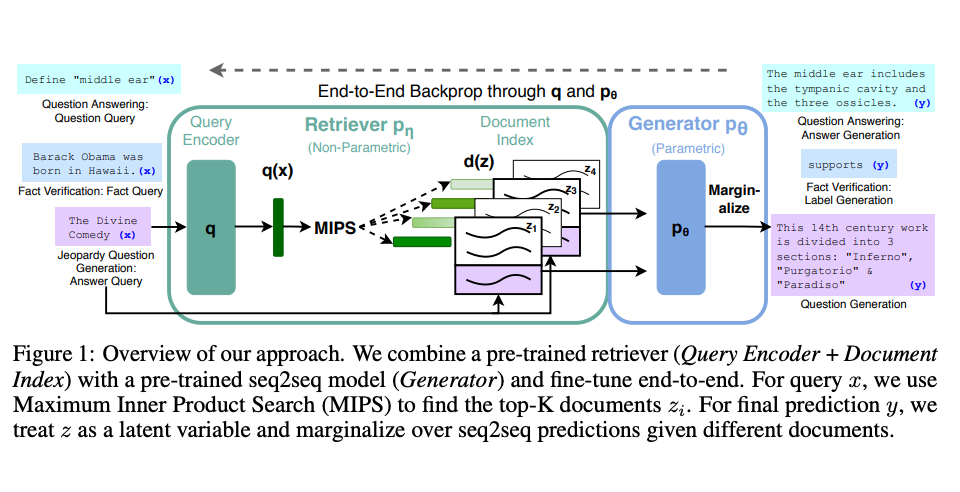
RAG(Retrieval Augmented Generation)
언어모델에서 가장 큰 문제는 환각(Hallucination)입니다. GPT같은 생성형 언어모델 특성상 모른다고 말하는 것이 아니라, 다음 단어(Next token)을 잘 예측하는 것이 주류기이 때문에 그렇습니다. 이 환각 현상을 줄이기 위해서, 내용의 맥락(Context)을 함께 사용되는 방법이 널리 사용됩니다. 이 방법이 RAG(Retrieval Augmented Generation)입니다. 즉, 어떤 정보를 검색(Retrieval)하여 얻은 내용을 포함(증강, Augmented)하여 언어를 생성(Generation)합니다.
이 RAG은 특수 목적(Task-specific)한 내용을 생성할 때 더 유리하게 사용됩니다. 일반적인 언어모델은 복잡한 내용을 이해하기보다는 일반적인 다음단어를 생성하기 위함이기 때문입니다.
- 입력으로 프롬프트를 던지고, 이 프롬프트와 가장 유사한 도큐먼트를 찾습니다.(위키피디아일수도 있고, vector DB로 만들어놓은 문서-벡터 DB일수도있습니다). 이 도큐먼트를 context로 사용됩니다.
- 원본 프롬프트와 도큐먼트(context)을 합쳐(concat)하여 final output을 만듭니다.
ReAct (Synerzing reasoning and Acting in Language models)
ReAct은 "사고과정(Reasoning trace, 추론) -> 행동(task-specific actions)"을 반복해서 돌리는 방법입니다. CoT와의 가장 구별되는 차이점은 실제 "행동(action)"이 들어간다는 것입니다.
아래의 그림은 "Thought, Act, Obs"의 3가지 단계를 구분지어서, 각 상황을 설명해보라고 하는 것입니다. 이 3가지 단계를 하나의 회차(에폭, 또는 Set)으로 두어, 다음 Set의 예측에 활용하는 것을 의미합니다.
실제 엑션이 가능해야하니, 액션을 할 수 있는 자료형을 얻거나/검색하는 기능이 구현이 되어야합니다.
Set 1
- 사고1: 첫회차에는 애플리모트(장비)가 필요한데, 원래 애플장치랑 상호작용할 수 있는 프로그램을 찾아달라고합니다.
- 액션1: 실제 애플리모트를 검색합니다.
- 관찰1: 애플리모트에 대한 설명이 나옵니다. Front Row media center program에 대한 내용도 반환합니다.
Set 2
- 사고2: 관찰1에서 얻은 내용을 다시 입력합니다.
- 액션2: 사고2의 내용을 바탕으로 액션을 다시 시행합니다.
- 관찰2: 액션의 2의 결과를 요약합니다.
아래의 예시에서는 사고-액션-관찰의 3가지 구성으로 사이클을 돌리는 방법입니다. 사고1에서는 애플리모컨으로 조절할 수 있는 장치를 찾고있고, 액션1에서는 실제 검색을 진행을하고, 관찰1에서는 검색의 결과를 가져옵니다. 이후, 사고2은 관찰1의 결과를 정리하고, 액션2은 사고2의 내용을 검색하고, 관찰2은 액션2의 결과를 다시 표현합니다. 이 사이클을 정해진 수만큼 반복합니다.

아래의 그림은 ReAct의 차이점을 Reason Only, Act only와 강조하기 위해 구분지어놓은 그림입니다.
- Reason Only은 사고과정을 추가하면서 더 나은 결과를 얻는 방법입니다. 예로는 CoT가 있습니다.
- Act Only은 RAG과 같이 환경(Environment)에서 Actions(검색)의 결과를 다시 출력에 활용하는 방법입니다.
- ReACT은 사고과정과 액션을 둘 다 하는 방법입니다.
