[5분 컷 리뷰] Reducing self-supervised learning complexity improves weakly-supervised classification performance in computational pathology
요약
Breast cancer관련 병리이미지의 분류문제에서, SSL을 활용할 때, 전체 데이터셋을 다활용하지 않고 50%정도 활용해도 전체를 사용한 것과 비등한 결과를 냈음. 또한, 인코더 전체를 다 사용하지 않고 일부레이어만 사용해도 큰 퍼포먼스의 저하가가 발생하지 않고, 오히려 오르는 경우도 관찰됨
Introduction
의료인공지능은 그 목적성이 강해, 대게는 지도학습으로 학습됩니다. 지도학습시에는 라벨이 있는 데이터를 많이 필요로하는데, 이 데이터를 만들기위한 비용이 매우 큽니다. 하지만 최근에, 라벨 없는 데이터에서 그 특징을 사전학습하는 자기지도학습(Self-supervised learning)으로 획기적인 성능향상을 많이 보였습니다.
문제는 이런 SSL을 할 때, 많은 데이터로 활용하다보니, 컴퓨팅 자원, 시간등이 많이 들어갑니다. 본 연구는 SSL할 때, 정말 이런 많은양의 데이터를 넣어 성능이 나오는가? 1) 더 적은 양을 SSL해도 성능이 유지되는 경우는 없는가? 2) SSL시 사용되는 인코더를 다 쓸필요는 있는가? 3) SSL에 사용되는 Contrastive learning시 샘플링 작업에 따라 성능 개선이 있는가?를 알아보기위한 논문입니다.
Methods

- SSL method for contrastive learning: MoCo v3
- Architecture: tiny Swin Transformer
MoCo: MoCo을 알기전에, 대조적학습(contrastive learning)을 이해해야합니다. 대조적학습은 인코딩된 샘플 $\{ k_{0}, k_{1},...,k_{N}\}$ 가 있을 때, 각각을 딕셔너리의 키(key)로 고려합니다. 즉, 쿼리(q)에 대해 하나의 positive key가 있고, 그 외에 다른 키들은 negative key로 고려합니다. 이 때, 손실함수는 아래의 손실함수를 사용합니다.
$L_{q}=-log(\frac{\psi(q,k^{+})}{\psi(q,k^{+} + \sum_{i=1}^{K}{\psi(q,k_{i})}})$
용어설명
- $\psi(q,k^{+})$: q은 이미지(x)로부터 augmentation 1번에 의해 생성된 벡터, $k^{+}$은 같은 이미지(x)로부터 augmetnation 2번에 의해 생성된 벡터를 의미합니다. 둘 다 같은 origin(원본이미지)으로부터 만들어진 vector입니다.
- $\sum_{i=1}^{K}{\psi(q, k_{i})}$: K은 negative sample을 의미하고 N-1과 동일합니다. 위에서 사용되었던 이미지(x)의 그 외 이미지들을 의미합니다.
- $N$: 배치사이즈 또는 memory queue의 길이를 의미합니다.
유사도
- 유사도함수($\psi (x_{1}, x_{2})$): $exp(sim(x_{1},x_{2})/\tau)$ 입니다. sim은 cosine similarity도 가능합니다.여기서 타우($\tau$)은 "temperature scale"이라고 부르며, 클수록 평활해지는 분포의 값을 가집니다(URL)
해석
유사도 함수($\psi$)은 항상 양의 값을 갖습니다. 따라서, log 내부 값의 값은 항상 0보다 크고 1보다 작은 값을 가집니다. 즉 log값이 (-inf, 0)을 갖기에, 음수(-)을 곱하여 (0, inf)로 손실함수 값을 계산합니다. (query, positive)의 유사도가 클수록(query, negtaive) 유사도가 작을수록 0으로, (query, positive)의 유사도가 작고, (query, negtaive) 유사도가 클수록 inf의 손실함수 값을 갖습니다.
아키텍처
MoCo에서는 feature collapse을 방지하기위해서, 서로 다른 encoder 2개를 사용하여, query, key을 생성합니다. query을 생성한 인코더의 가중치(파라미터)를 $\theta_{q}$라 하고, k로부터 얻은 $theta_{k}$라고하면, 가중합을하여 파라미터를 업데이트 합니다. m은 모멘텀계수(momentum coefficient)라고 합니다.
$\theta_{k} <- m \theta_{k} + (1-m) \theta_{q} $
샘플링방법
1. Semnatically-relevant contrastive learning (SRCL): 추가적인 positive sample을 구하기위한 샘플링 방법
SRCL와 MoCo의 가장 큰차이는 positive smapling수의 차이가 있습니다. 배치당 positive sample을 1개씩만 얻는 MoCo와 달리, SRCL을 더 많은 수를 뽑습니다. 주요 가정은 같은 슬라이드 이미지에서 나온 패치들은 더 유사성이 높을 테니, negative로 취급하면 안된다라는 것입니다.
SRCL의 positive sampling 방법은 슬라이드 내의 위치정보를 사용하지는 않고, 유사도 기반으로 샘플링하는 방법입니다. 배치 또는 메모리큐에서 코사인유사도가 가장 큰 5개의 패치를 골라, positive sample로 정의하고, 그외를 negative로 정해서 contrastive learning을 합니다. 이 논문에서는 Poistive sample이 5개를 고르려면, 인코더가 충분히 학습되어야한다는 가정하에, 파라미터가 잘 학습된 구간이라고 생각할만한 5에폭 이전까지는 일반적인 contrastive learning을 돌리고, 이후로 SRCL로 학습했습니다.
$L_{q}=-log(\frac{\sum_{j=1}^{S+1}\psi(q,k^{+})}{\sum_{j=1}^{S+1}\psi(q,k^{+}) + \sum_{i=1}^{K}{\psi(q,k_{i})}})$
- S: 추가적인 positive samples의 수
- K: negative 샘플의수. (N-S-1). N 배치 또는 매모리 큐의 수, 1은 자기자신 (query), S은 positive sample 수
2. Negative smaplign (N-Sam)
3. Dynamic sampling (DS)
실험 및 평가
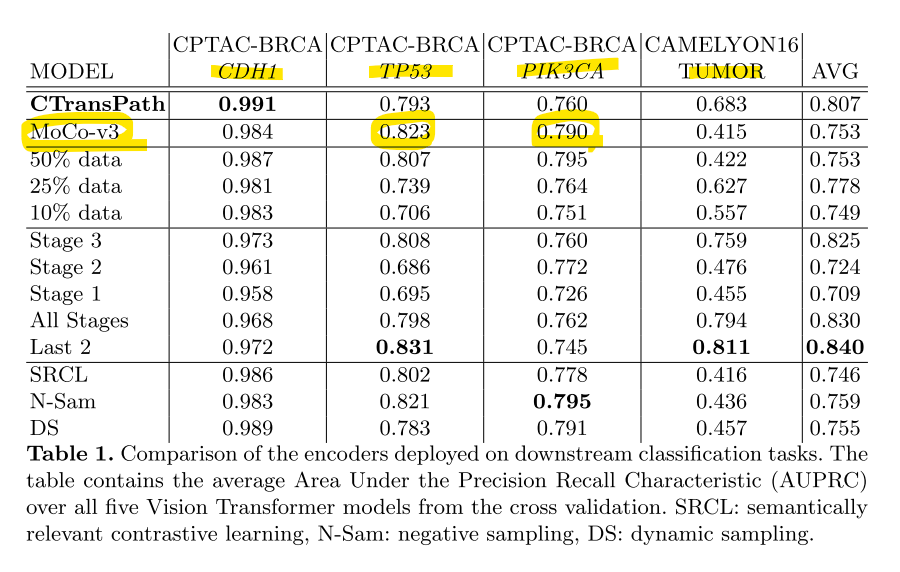
- 행1-2: tiny Swin Transformer의 스크래치모델로부터 50에폭을 돌리고, AdamW 옵티마이저를 사용했때, 약 에폭은 25회이상돌리고, 데이터는 4%정도만 돌렸음에도 SOTA인 CTransPath와 유사한 성능이 보였습니다. 심지어 일부 테스크에서는 좀 더 좋은 성능을 보였습니다. 카멜레온데이터셋에서는 오히려 성능이 감소하는것을 보였습니다. 저자들은 이 이유는 CTransPath모델이 TCGA로 다장기로 SSL했을 때, Camelyon16 데이터셋이 섞여들어가서, 잘나올수 밖에없다고 합니다.
- 행1,행3-5: SSL시 사용하는 데이터를 몇프로 까지 줄여도 성능이 유지되는가를 확인했을 떄, 50%정도 까지 사용해도 전체 데이터셋을 사용했던 MoCo-v3와 유사했다고 합니다. 50%면 충분하다는 실험적인 증거로 제시합니다.
- 행1,행6-10: 인코더를 전체 사용하는게 아니라 몇번쨰 중간레이어을 사용하는 경우에 따라 성능을 비교했습니다. 1, 2번째 레이어에서 가져오는 경우 성능이 저하되었지만, 끝에서 두번쨰(last 2)의 차원을 가져오는 경우는 오히려 성능이 증가함을 보였습니다.
- 행1, 행11,12,13: 이 실험에서는 Negative sampling(N-Sam)과 Dynamic sampling(DS)가 상대적으로 더 좋은 결과를 냈습니다.
결론
유방암의 WSI encoder을 학습을 SSL로 학습할 때, 요구되는 자원을 좀 더 적게 쓸수 있다는 분석을 얻었습니다. 특히, 데이터를 전체 다 사용하지 않더라도 downstream task에서 전체 사용하는 것과 비등한 성능을 보였다는게 놀랍습니다. 또한, 인코더 전체를 굳이사용할필요는 없고, 마지막인코더를 제이하는 경우가 오히려 weakly supervised learning에서 더 나은 성능일 보였습니다.