[5분 컷 리뷰] SimCLR (A Simple Framework for Contrastive Learning of Visual Representations) 리뷰
요약
SimCLR을 이미지 데이터을 더 잘 구별하기위한, 대조적학습 (Constrative learning)을 이용한 사전학습 프레임워크*입니다. SimCLR은 비슷한 같은 데이터 증강(Data augmentation)을 이용하는데, 같은 데이터 소스로 부터 생성된 이미지는 가깝게, 다른 이미지소스로 부터 생성된 이미지는 멀게 학습하는 metric learning 방법입니다. 즉 이미지의 유사성/이질성을 학습하는 방법론입니다. 이 방법론을 사전학습으로 사용하면, 시각적표현을 더 잘학습할 수 있고, 지도학습 등에서의 적은 파라미터로도 더 높은 구별성능을 낼 수 있습니다.
*프레임워크: 세부적인 방법론만 바꿔가면서 동일한 목적을 달성할 수 있도록하는 큰 틀을 의미합니다.
Introduction
- 비전관련 학습은 크게 생성이나, 구분문제(discrimitive approach)로 나뉩니다. 생성도 역시 2가질로 나뉘는데 모델을 학습하는 방법과, 픽셀수준까지 학습하는 방법으로 나뉩니다. 다만, 픽셀수준까지 생성하는것은 매우 비용이 많이듭니다. 한편, 분류문제(discrimitive approach)은 목적함수등을 이용해서 지도학습을 하게되며, 사전학습문제(pretext task)을 이용해서 라벨없는 데이터를 학습하기도합니다. Pretext task을 어떻게 꾸리냐에 따라 다르긴한데, 대부분 사람마다 다른 경험적인(heuristic)한 방법입니다. 그러다보니, 일반화성능에 미치지 못할 수 있습니다. 하지만 최근 들어서는 contrastive learning이 pretext task에 기여할 수 있다는 논문이 주류로 뜹니다.
- 저자들은 Contrastive learning을 할 수 있는 방법론을 하나 제시합니다. 그리고, Constrative learning을 잘하기 위한 주요요소들을 제시합니다.
1. 여러가지 data augmentation 방법을 함께 이용하는 것이 매우 중요함.
2. Augmentation 후에 learnable 비선형변환의 표현이 표현 성능이 더 좋음
3. Contrastive corss entropy을 사용하면 더 좋음
4. 큰 사이즈의 배치사이즈와 긴 훈련시간을 사용하면 좋음
Methods
- Contrastive learning framework - 목적: 같은 데이터에 다른 방법의 Augmentation을 사용하여 비선형매핑을 하더라도 동일함 이미지로 표현됨
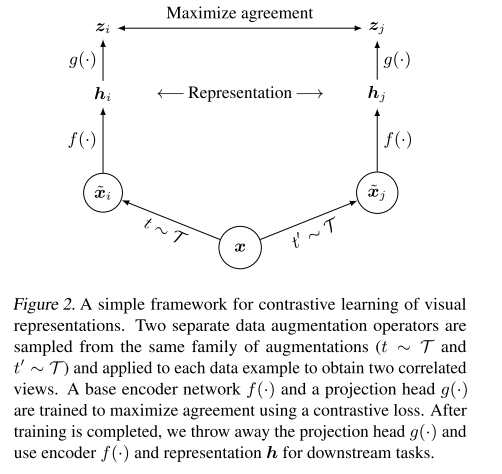
구성요소
- Data augmentation: 한 이미지로부터 각각 다른 데이터증강방법을 이용해서 (x_i), (x_j)을 생성합니다. 이 두 이미지를 positive 데이터로 만듭니다. 위의 그림에서 t~T에해당하는 것이 data augmentation 방법입니다. 그 결과는 $\tilde{x}_{i}$, $ \tilde{x}_{j}$에 해당합니다.
- Base encoder: 인코더 $f()$. 이 인코더를 통과한 이후 d차원의 벡터를 만들어 냅니다.
- Projection head: $g()$. base encoder가 생성한 벡터를 비선형변환을 하는 MLP을 의미합니다. 그 결과 벡터 $z$가 생산됩니다.
- contrastive loss function: negative + positive 이미지가 포함되었을때, x_i을 모델에 입력한 경우 x_j을 선별하는 과정을 목적 정의 되었습니다. 이 논문에서는 미니배치를 N개로 두었습니다. N개의 이미지로부터 각각 2개씩 데이터증강을 하니 총 2N의 데이터포인트가 생깁니다. 이 2N에서 positive을 하나 i라고하면 i와 짝이되는 j 은 positive이고 그외는 negative가됩니다. 2(N-1)이 negative pair가 됩니다. 예를 들어, 5개의 이미지를 미니배치라고하면 각각의 5개로 만들어낸 10개는 유사도: sim(u, v). 두 벡터 u, v가 들어오는 경우 $u^{T}v / ||u||||v||$을 하는 과정으로 cosimilarity을 의미합니다. 위의 유사도를 이용해서 아래의 손실함수를 정의합니다.

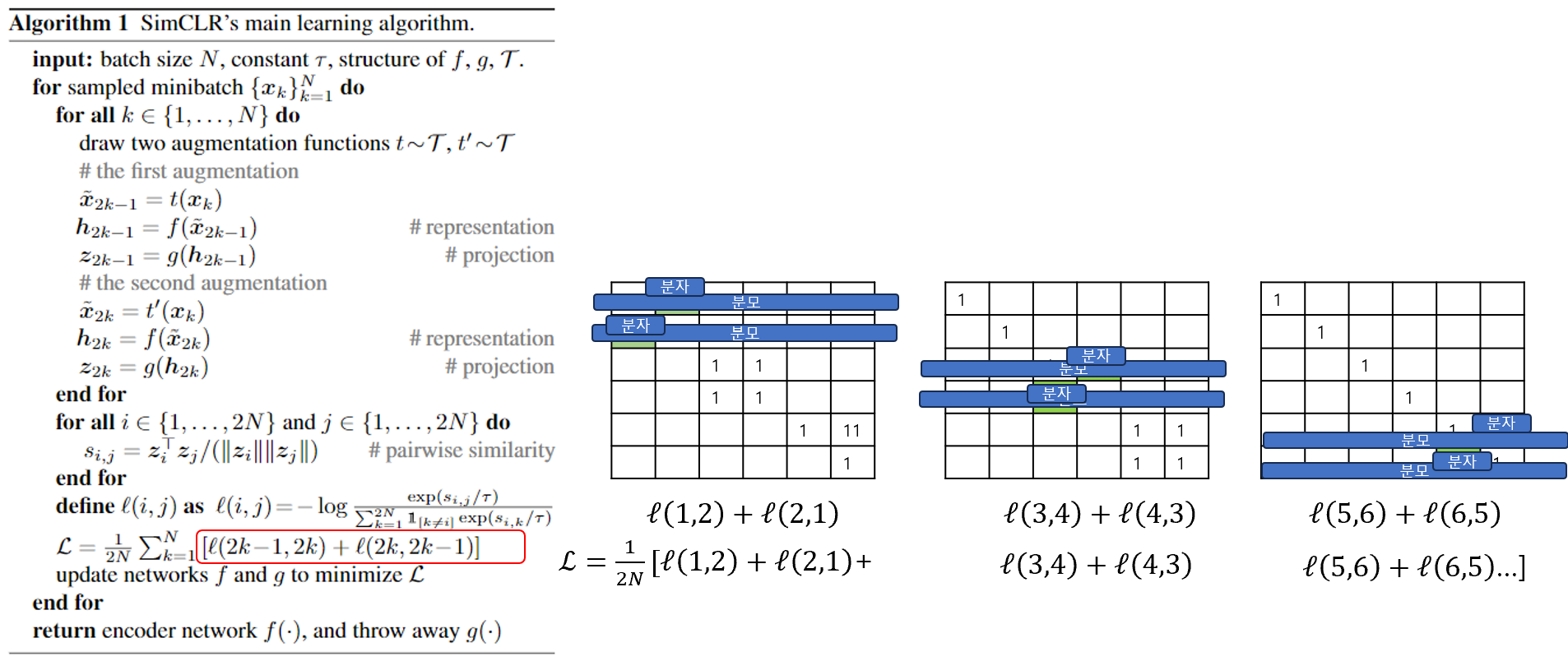
전체적인 SimCLR의 알고리즘은 아래와 같습니다. 그리고, 이를 시각화하면 아래와 같은 메트릭스 연산을 하는 것과 동일합니다.
1. 알고리즘의 첫번째 단계로는 각 이미지를 Augmentation하는 것입니다. N개의 이미지가 배치사이즈라고하면 각 N개의 이미지를 2개씩 각각 다른 방법론으로 augmentation 시킵니다.

2. 유사도 메트릭스를 생성합니다. $_{i,j}$가 유사도 메트릭스에 해당하고, i와 i은 같은 이미지이므로 1이어야하고, i와 바로 +1차이나는 j도 같은 이미지로부터 augmentation 된것이니(=1단계:Augmentation), 같은 이미지로 유사도가 1이어야합니다.

3. 손실함수 계산: 유사도 메트릭스 $s_{i,j}$에 대해서 i,j의 순서를 바꿔가면서 손실함수를 계산합니다. 분모는 한 행을 의미하고, 분자는 i또는 j에 대해서 계산합니다.
Result
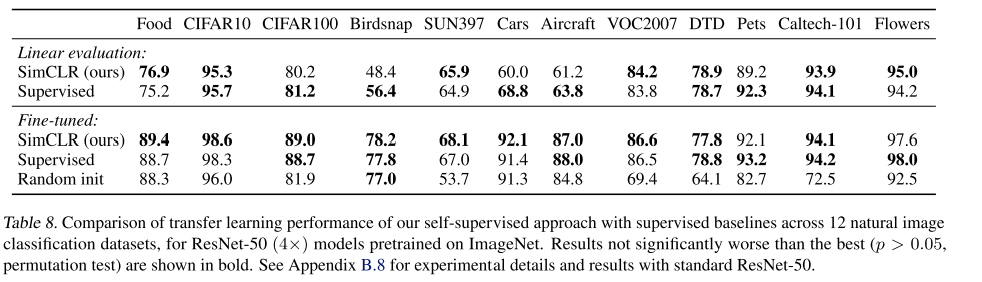
사전작업(Pre-text)을 학습하는 경우, 이 모델을 fix하고 linear 모델만 단 경우는 여러 데이터셋에서 성능의 우위를 가리기어렵지만, 이를 함께 fine-tuning하는 경우 지도학습모다 더 좋은 성능을 기대할 수 있었습니다.
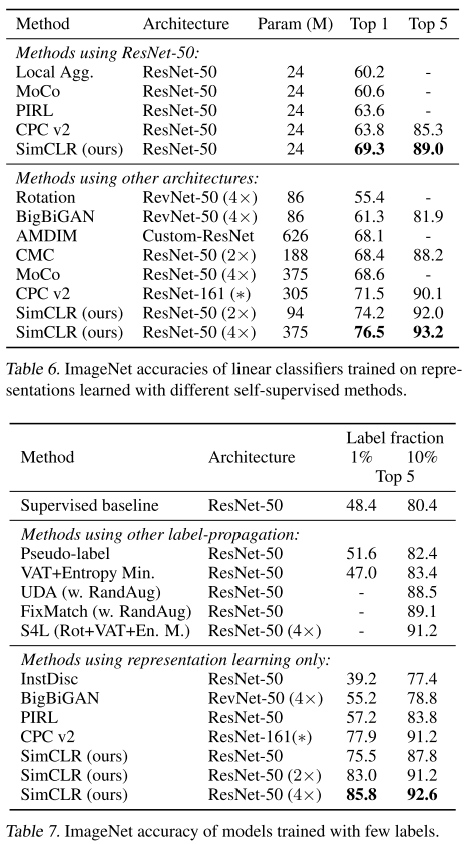
다른 모델과의 비교에서도 동일한 파라미터내에서는 더 잘 시각적인 표현을 학습해서 예측을 잘한 결과를 보여주고 있습니다 (Figure 6). 또한, ImageNet에서도 라벨이 거의 없는 이미지에 대해서도 Top 5예측성능이 우수하게 나오고있습니다.
두 번째 결과로는, "한 이미지로부터 두 Augmentation을 해야하는데, 어떤 조합으로 하는게 좋을까?"를 실험적으로 증명합니다. Augmentation 방법로는 아래의 10가지 말고도 여러가지 방법론이 있습니다. Data augmentation 단계에서 하는게 좋을 지 고민을 해야합니다.

이 고민에 대해서 실험적으로 여러 짝으로 진행해보았고, 그 결과로 컬러왜곡(color distortion)과 Crop의 조합이 가장좋았습니다.

컬러 왜곡이 중요한 이유를 추가적으로 설명했는데, 랜덤크롭한 영상의 이미지가 비슷한 컬러를 보여주기 때문에, 컬러만 가지고 구분이 될 수 있다는 내용을 언급합니다. 그렇기에 이것을 좀더 어렵게하더라도, 더 잘 맞추기위해(=일반화 성능향상) 컬러 왜곡을 하는 것이 중요하다고 합니다.
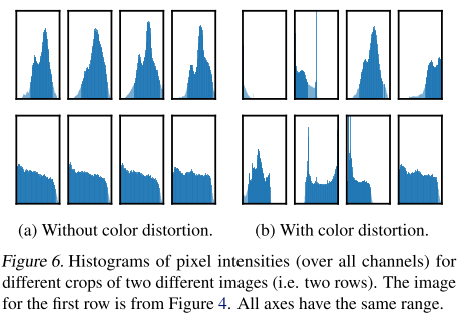
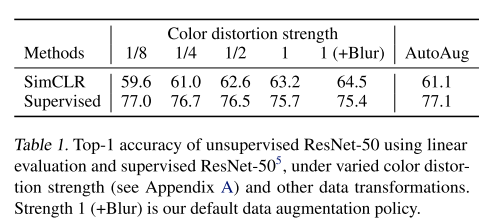
이러한 컬러 왜곡을 더 강하게 줄 수록, 비지도학습에서의 성능이 더 향상된다고합니다. 지도학습보다 더 좋은 성능이다라는 것이 아니라, 컬러왜곡을 지도학습과 비지도학습에 둘다 적용할때, 강도를 세게했을때는 SimCLR에서 더 효과가 좋았다라는 것입니다.
에폭이 적을때는 배치사이즈가 더 큰 사이즈로하는 것이 좋지만, 충분히 학습시킬 수 있는 epoch이라면 배치아시즈가 그렇게 영향을 주는 것 같지 않습니다. 이는 배치사이즈마다 샘플링을 각각 다르게하니, 시각적인 학습을 충분히 더 할 수 있음에도 100에폭밖에 학습을 못해서 충분히 학습이 안된것처럼 보입니다. Constrative learning에서는 더 큰 사이즈의 배치를 넣으면 negative가 엄청 많아지기에, 더 빨리 학습의 수렴을 유도하는것으로 해석해볼 수 있습니다(=더 빠른 이미지의 구별능력)

pytorch구현
파이토치에서 augmentation된 이미지 i, j의 유사도를 구하는 방법은 아래와 같습니다.
- 유사도 메트릭스 ($s_{i,j}$) 내에 각 행에는 2개의 positive 샘플이 있습니다. 하나는 자기자신이고, 나머지는 augmentation된 이미지 2장이 같은 origin이라는 positive sample pair입니다.
- 자기자신(i=j)인 인덱스만 지워줍니다. 이 지운 결과는 벡터로 나옵니다.
- 벡터에서 positive만 따로 가져오고, 나머지 negative을 따로 구한 후 ,concat 합니다. positive와 negative순서로 concat합니다.
- 이 때, 라벨은 positive sample은 항상 0번컬럼에 존재하기에 np.zeros(2N)으로 만듭니다. 왜냐하면 torch.nn.CrossEntropy 구현체에서는 라벨에는 항상 정답라벨의 클레스번호가 들어가기 때문입니다. 정답라벨이 항상 0이기에, 그냥 np.zeros()로 들어갑니다.
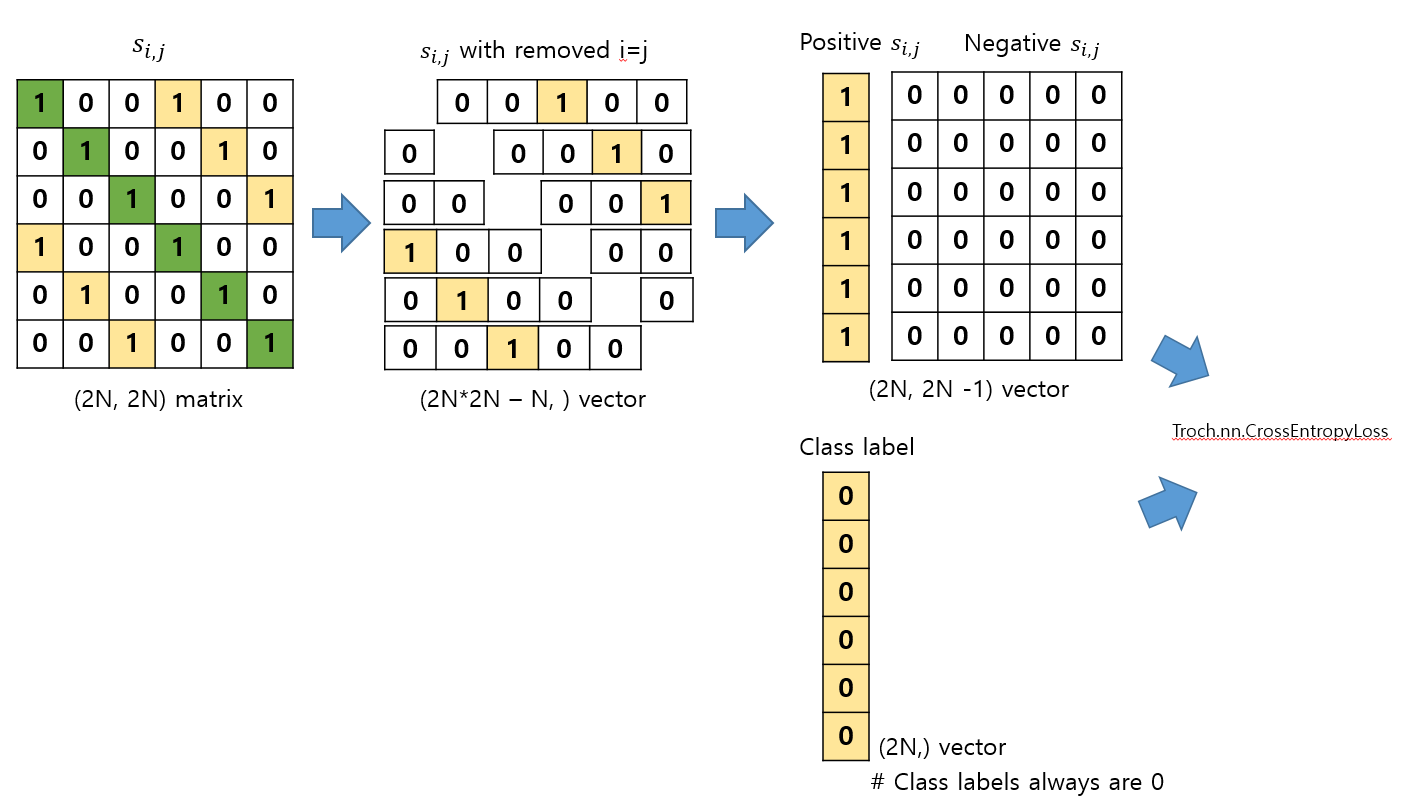
위 내용을 이용해 구현한 코드는 아래에 있습니다.
Conclusion
SimCLR 프레임워크는 Constrative learning을 이용해서 self-supervised learning을 진행하고 다운스트림테스크에서 더 나은 성능을 보여주었습니다. 그리고, 그 각 세부요소들 중에, 어떤 조합/하이퍼 파라미터가 좋은지 결과를 함께 보여주었습니다.