[5분 컷 이해] DERT: End-to-End Object Detection with Transformers
요약
DERT(Detection TRansofmer, 2020)은 객체검출(=Object detection)을 시항 할 때, 복수의 객체를 동시에(=페러렐하게) 예측하는 방법론을 고안한 모델입니다. DERT은 모델이 고정되어 있는 것이 아닌, 하나의 파이프라인으로 동작할 수 있고, 이 파이프라인에서는 NMS와 같은 후처리 공정이 들어가지 않게 고안된 파이프라인이라는 점이 특징입니다. 이 DERT은 Anchor free로 동작하고, 복수의 오브젝트를 예측하고, 각각의 실제 객체에 할당할 수 있도록 하도록 고안한 손실함수(Set-based global loss)을 이용하여 학습합니다.
사전 개념(Preliminary): Anchor-free, Set prediction
1. Anchor base vs Anchor free: 앵커는 이미 정의된 오브젝트의 중앙점 또는 박스를 의미합니다. 영어로는 Pre-defined bounding box라고도 합니다. 이를 이용하여 예측을 하는 경우, Anchor based object dection이라고 합니다. 예를 들어, 아래의 그림과 같이 파란색이 앵커라고하면, 사실 이런 파란색 앵커들이 훨씬 이미지에 많습니다. 그 다음에 가장 IOU가 높은 앵커를 찾고, 이 앵커를 조정하여 객체인식을 하는 방식입니다. 아래의 그림(Figure 1의 좌측 그림)은 여러 앵커중에, IOU가 높은 앵커를 선택하고, 이 앵커를 조정하여 ground truth을 조정하는 방식입니다. [1], [2]. 반면 Anchor free 은 이러한 사전정의된 박스없이, 오브젝트의 중앙점, 가로, 세로를 바로 예측하는 접근 방법론을 의미합니다.

2. Set prediction: 복수의 객체를 동시에 예측하는 것을 의미합니다. 객체를 하나하나 예측하는 방법과 대비되는 개념입니다.
Introduction (도입부): 여태까지는 Set prediction을 할 때, 후처리 성능의 의존적이 었음 => 후처리 없애고, End-to-End로 예측하는 모델을 만들어봄
Set prediction이 없던 것은 아니었습니다. 다만, 여태까지는 Set prediction을 간접적인 방법으로 예측 또는 분류를 하고 있었는데, 이러한 방법들은 오브젝트에 바운딩박스가 여러 개가 예측될 때, 후처리하는 방식에 성능이 영향을 많이 받았습니다. 본 모델은 이러한 후처리 방식을 없애고 End-to-End로 이미지를 입력받아, 객체검출을 하는 방식의 파이프라인입니다. 파이프라인이라 한 것은 이 모델에 백본(backbone)으로 쓰이는 모델들을 충분히 변경하며 다양한 아류들을 만들어 낼 수 있기 때문입니다.

Method: 1) 백본으로 이미지 특징값을 뽑아, Transformer 전달하여 이미지의 객체를 예측, 2) 오브젝트와 실제오브젝트를 매칭하기 위한 Bipartite matching
아래는 DERT가 Set predcition을 진행하는 과정의 전체적인 파이프라인을 보여줍니다. 한 이미지가 들어오면, Pretrained model(본문에서는 Backbone 등으로 표현)모델로 추론을 합니다. 그렇게 얻어진 이미지 특징값들을 Transformer에 전달합니다. 이 transformer 내의 decoder에서 반환되는 예측치가 오브젝트의 예측치로 생각하는 것입니다.

위의 그림을 보면, 크게 1) Backbond, 2) encoder, 3)decoder, 4) Feedforward network(prediction)으로 구성됩니다.
1. Backbone: CNN(convolution neural network)으로 이미지의 특징값을 압축합니다. 보통 3채널의 이미지가 들어오면, CNN을 통과시킨다음에, feature 채널수가 2,048개, 가로, 세로는 원래 H/32, W/32만큼으로 축소하여 전달합니다.
2. Transformer encoder: 1x1 CNN을 이용해서 2,048의 특징값채널을 d채널로 까지 압축시킵니다. 그렇게 만들어낸 특징은 z0입니다. (d,H,W)의 차원을 갖습니다. 이렇게보면, 이미지가 3 x H, W을 넣어서 d x H x W가 되었습니다. 이렇게 된 H, W은 각각 의미가 있습니다. 각 픽셀이 원래 위치하고 있는 위상들이 각각 의미가 있다는 의미입니다. 따라서, Positional encoding을 더합니다. 이는 Transformer에서 위상정보를 추가로 덫대어 학습시키기 위한 전략인데, 이미지에서도 마찬가지로 쓰일 수 있습니다. 트렌스포머 아키텍처는 입력의 순서에 상관이 없는 (Permuational invariant)하기 떄문에, 포지셔널 인코딩을 더한다라고 생각하시면 됩니다.
3. Tansformer decoder: 디코더는 인코더의 출력과, 오브젝트 쿼리(Object queries), 포지셔널 인코딩을 입력으로 받습니다. 오브젝트쿼리가 좀 생소한데, 0,0,0,0값을 넣는것은 아니고, N개의 오브젝트를 무조건 반환한다고 했듯이, N x 임베딩(d)의 차원을 가진 traininable parameter에 해당합니다. 이를 입력 값으로 받아, 멀티헤드어텐션을 이용하여 각 N개의 상호작용을 함게 학습합니다. 이전 Transformer와의 차이점도 있는데, 주요 차이점은 원래 Transformer은 반환되는 값을 다시 Transformer decoder에 넣는다는 점인데, 본 DERT은 그렇지 않습니다. (*쿼리 오브젝트는 Embedding 레이어의 weight을 사용하여 구현합니다.)
4. FNN(feed forward networks): 마지막레이어에 해당됩니다. Fully connected layer 3개와 각각 ReLU을 중첩하여 사용합니다. 각각은 아래의 그림과 같이 Class 라벨예측, Bounding box예측에 사용됩니다.

Transformer을 사용하는 이유? 이 파이프라인은 Transformer을 썼는데, Self-attention을 모든 Sequence에 대해서 NxN으로 계산하여, 상호작용을 다 계산할 수 있듯(all pairwise interaction) 이미지에서도 각 객체의 예측치가 중복되지 않을 것이다라는 예상을 하고 Transormer을 사용하는 것입니다. 저자들도 이 점을 방점으로찍습니다.
DERT의 가장 중요한 점은 1) set predition loss을 이용해서, 학습당시에 예측치의 객체가 실측치의 객체에 중복할당되지 않도록 유도하는 것이고, 2) 하나의 파이프라인으로 오브젝트끼리 관계를 학습해서, 한번에 오브젝트를 예측하는 것입니다. 아래와 같이 정확한 기술사항을 작성해봤습니다.리 정의되어야하는 것은 N입니다. N은 예측할 오브젝트의 개수. DERT은 어떤이미지가 주어지더라도 N개의 오브젝트를 반환합니다. 다만 N개 중에 confidence가 낮은 것만 제거하면 됩니다. 통상, 예측하고자하는 오브젝트보다 큰 숫자를 설정하면 됩니다.
Bipartite matching cost
- 필요성: 위의 사항은 한 문제를 야기하는데, 예측하는 오브젝트의 개수가 무조건 N개만 반환되고, 실제 오브젝트가 이보다 작은 K개라면, 중복이 될 수도 있고, 남는 예측치는 어떻게 할 것인가에 관한 문제입니다. 이를 해결하기위해서 Bipartite matching cost을 정의합니다.
Notations:
- y: ground truth 오브젝트의 집합. 이 집합이 N보다 작으면 패딩($\phi$ = 오브젝트가 없음을 의미)할 수 있음
- $\hat{y}$: 모델이 예측하는 N개의 오브젝트의 집합
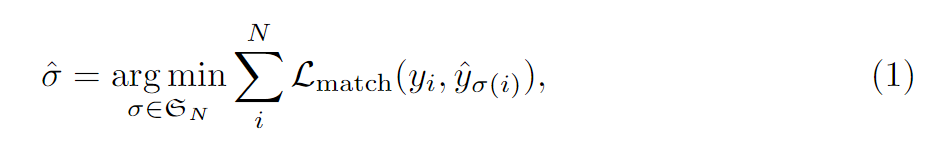
다시 식을 보면, 앞에 $\sigma$ 은 예측치에 대한 순열이며, N개니까 N!만큼 순서가 의미가있는 조합이 생깁니다. 가장 이상적인 예측치는 아래 그림과 같습니다. 각 원은 실제 벡터입니다. 단순히 벡터라고 생각하지않고, 모델이 예측한 예측치1이 실측치1에 상응하게되면, 둘의 차이가 가장 줄고, 예측치K이후부터는 모든 값이 0인 경우가 오차가 가장 적을 것입니다. 이러한 조합을 여러번 계산하는 이유는 Transformer에서 반환되는 오브젝트의 순서가 의미가 없기 때문입니다. 이 의미없는 오브젝트의 예측에서, 실측치에 하나씩 상응시키기위해 이러한 작업을 합니다. 이 작업은 앞서 경우의수가 N!이나 된다고 했습니다. 컴퓨터로도 계산하기 너무 많은 양이지만, 다행스럽게 헝가리안 알고리즘(Hungarian algorithm)을 이용하면 계산식의 부담을 줄일 수 있습니다. 이 알고리즘은 본 포스팅에서 다루지 않습니다.

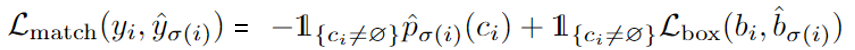
식은 위와 같습니다. L matching은 클레스라벨, 오브젝트의 중앙부, 폭, 높이가 얼마나 차이나는 지를 계산하는 것입니다. y 및 $\hat{y}$ 내의 원소에 해당하는 값들은 실제 튜플 또는 벡터로 표현해볼 수 있고, 총 값은 5개로 표현됩니다. $y_{1}=(c_{i}, b_{i})$. c은 라벨을 의미하며, b은 중심점의 x,y, 높,너이입니다. 그리고 L_match의 앞에텀은 클레스가 맞았는지, L_box은 예측한 오브젝트가 실측의 오브젝트와 거리가 가까운지를 측정하는 손실함수입니다. 당연히 ground truth가 패딩된 것이 아닌 것에 대해서만 계산합니다. Bounding box loss은 GIOU을 사용합니다.
결과(Results)
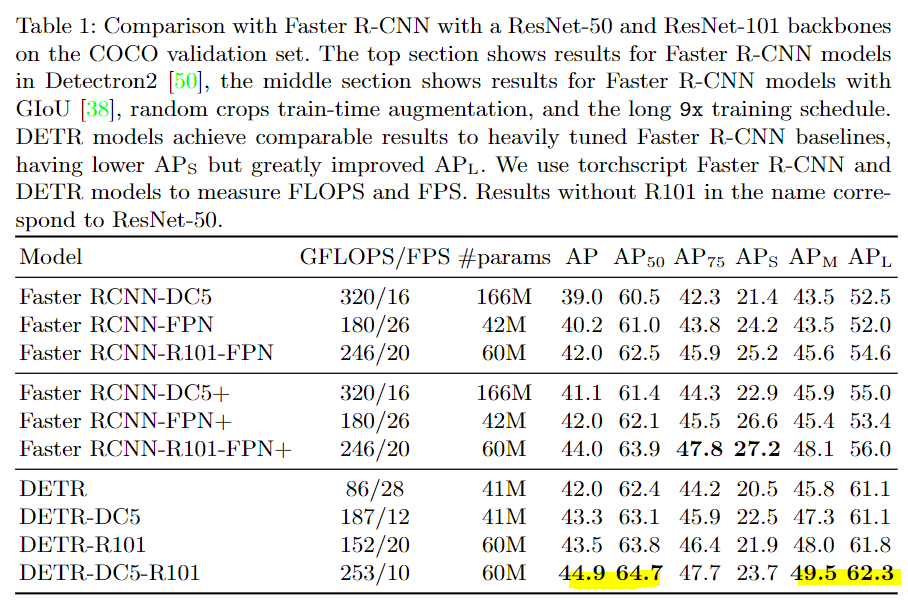
첫 번째 결과로는 Faster R-CNN과 2개의 백본으로 실험한 DERT와의 성능비교입니다. 데이터셋은 COCO이며, DC은 Dilate C5입니다. DERT-DC5-R101의 아키텍처가 가장 우수한 성능으보이며, 파라미터수도 적었습니다.
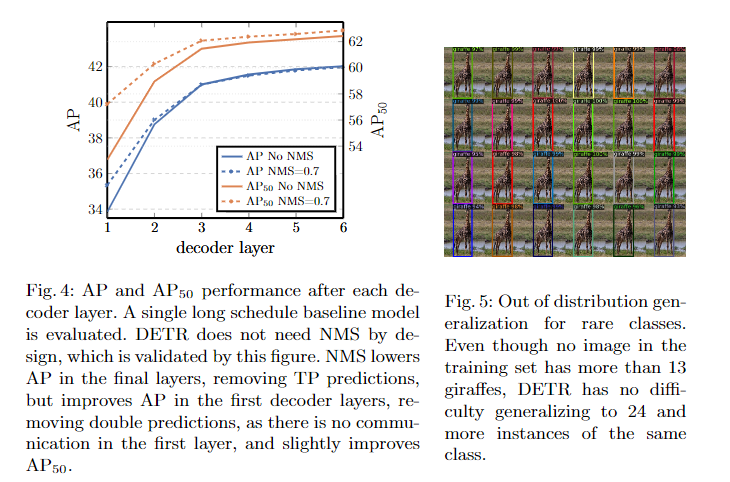
2) 인코딩레이어가 어느정도 성능을 내고있음. 인코딩레이어의 수를 0으로하면, 추론속도를 빠르게할 수있지만 AP가 감소함.
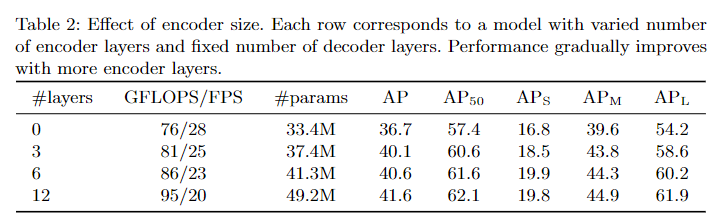
3) 디코더 레이어도 어느정도 성능에 필요함: 디코딩레이어의 수를 없앨수록 성능이 저하됨.
4) 인코더부분의 self-Attention시각해보니, 각객의 개별인스턴스를 잘 예측하도록 Attention map이 구성되어있었다. = 각 인스턴스를 예츠갛도록 Attention이 동작하고있다는 것을 보여줍니다. 언어학에서 중요한 토큰을 보여주듯, 각 인스턴스에 대해서 토큰을 보여주는 형태라고 생각하면 됩니다.

5) GIOU + L1로스를 같이 쓰는 경우가 성능이 제일 좋았다는 결과입니다.
6) 디코어의 attention을보면 각각의 attention score(=attention weight * features)가 경계면에 가중치를 두는 것을 볼 수 있습니다. 즉 바운딩박스를 만들기에 중요한 경계를 보고잇다라고 주장하는 근거입니다.

7) 각각의 예측하고자하는 오브젝트쿼리에 따라서, 주로 보는 영역들이 다르다는 것을 보여주는 그림입니다. 해석: 녹색점은 각 예측치에 해당하는 점입니다. 작은 점은 매우 넓은 분포를 가지고있습니다. 반면, 빨간점은 가로로 긴 박스의 예측치의 중앙부입니다. 가로로 길기 때문에, 이미지내에서는 보통 중앙부에 있을 것입니다. 각 예측치의 크기에따라 어느부분을 중점적으로 관찰하는지에 대한 시각화라고 볼 수있습니다.

참조(References)
[1] Wang, C., Luo, Z., Lian, S., & Li, S. (2018, August). Anchor free network for multi-scale face detection. In 2018 24th International Conference on Pattern Recognition (ICPR) (pp. 1554-1559). IEEE.
[2] https://learnopencv.com/centernet-anchor-free-object-detection-explained/